
Introduction
The challenge of translating text from one language to another is one of the cornerstones of natural language processing (NLP). Its major goal is to generate target-language text that faithfully conveys the intended meaning of the input material. The objective of this task is to take an English statement as input and output a French translation of it, or any other language of preference. Because of the importance of language translation to the area of NLP, the original transformer model was created with that objective in mind.
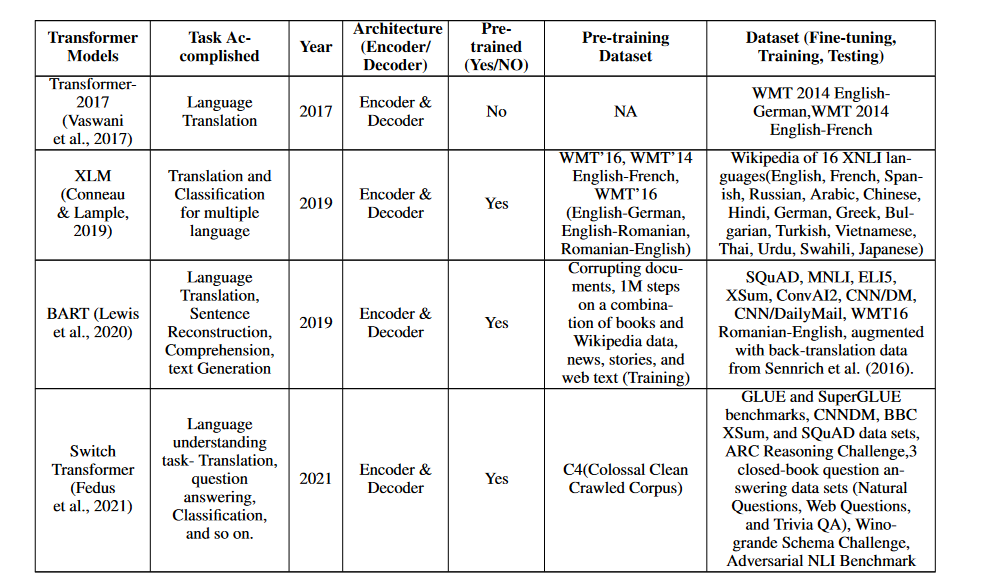
The models in the Table below that use transformers and have performed well on the Language Translation task are listed there. In order to improve the flow of information and knowledge between people of diverse linguistic backgrounds, these models play a crucial role. When considering the breadth of NLP's potential impact in fields as varied as business, science, education, and social interactions, it's clear that the language translation task is an essential topic of study. The table presents many transformer-based models that show promise for enhancing the state-of-the-art in this area, opening the door to novel methods to language translation (Chowdhary & Chowdhary, 2020; Monroe; 2017; Hirschberg; & Manning; 2015).
Transformer
In 2017, Vaswani et al. (Vaswani et al., 2017) proposed the first transformer model, which has since drastically changed the landscape of natural language processing. The Vanilla transformer paradigm was developed for the express purpose of translating across languages. The transformer model is distinct from its forerunners in that it includes an encoder and a decoder module, using multi-head attention and masked-multi-head attention processes.
The input language's context is analyzed by the encoder module, while the decoder module generates output in the target language by applying the encoder's outputs and masking multi-head attention. The capacity of the transformer model to execute parallel computations, which allows the processing of words alongside positional information, is partly responsible for its success. This allows it to manage long-range dependencies, which are essential in language translation, and makes it exceptionally efficient at processing huge quantities of text.
XLM
It is a model for pre-training a language that can be used with more than one language. Both supervised and unsupervised techniques are used to build the model. The unsupervised approach has shown to be very useful in translating tasks via the use of Masked Language Modeling (MLM) and Casual Language Modeling (CLM). However, the translation challenges have been further enhanced using the supervised technique (Conneau & Lample, 2019). With its ability to execute natural language processing tasks in various languages, the XLM model has become an invaluable resource for cross-lingual applications. The XLM model is widely used in the area of natural language processing due to its efficiency in translation assignments.
BART
The pre-trained model, known as BART (Bidirectional and Auto-Regressive Transformers), is largely aimed at cleaning up corrupted text. It has two pre-training steps: the first introduces noise corruption into the text, while the second focuses on recovering the original text from the corrupted one. To generate, translate, and understand text with remarkable accuracy, BART uses a transformer translation model that includes the encoder and decoder modules (Lewis et al., 2020). Its auto-regressive features make it well suited for sequentially generating output tokens, and its bidirectional approach allows it to learn from previous and future tokens. These features make BART an adaptable model for a wide range of NLP applications.
Switch Transformer
The Switch Transformer model is a relatively new development in the world of NLP, and it has attracted a lot of interest due to its impressive accuracy and versatility. It has a gating mechanism and a permutation-based routing system as its two main building blocks. Thanks to the permutation-based routing mechanism, the model can develop a routing strategy that decides which parts of the input sequence to focus on.
Since the model can dynamically decide which parts of the sequence to focus on for each input, it can handle inputs of different lengths. The model can perform classification and segmentation thanks to the gating mechanism. The gating mechanism is trained to make predictions based on a combination of information from the entire input sequence. This allows the model to perform classification tasks, where it predicts a label for the entire input sequence, as well as segmentation tasks, where it predicts labels for each individual part of the input sequence. This is explained in the following section on classification and segmentation (Fedus et al., 2021).
Classification and Segmentation
Natural language processing (NLP) relies heavily on text classification and segmentation to automate the organization and analysis of massive amounts of text data. Tags or labels are applied to text based on content such as emotion, topic, and purpose. Applications such as content filtering, information retrieval, and recommendation systems can benefit from this method of classifying text from multiple sources. Segmenting text into meaningful chunks such as sentences, words, or topics for further processing is what text segmentation is all about. Important natural language processing (NLP) applications rely heavily on this process, and it has been extensively researched and written about (Chowdhary & Chowdhary, 2020; Kuhn, 2014; Hu et al., 2016).
Charformer
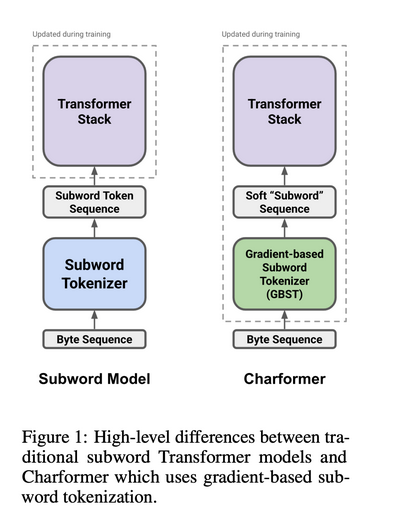
This transformer-based model introduce gradient-based subword tokenization (GBST) which is a lightweight method for learning latent subwords directly from byte-level characters. The model, available in English and several other languages, has shown exceptional performance in language comprehension tasks, including classification of long text documents (Tay et al., 2022).
Switch Transformer
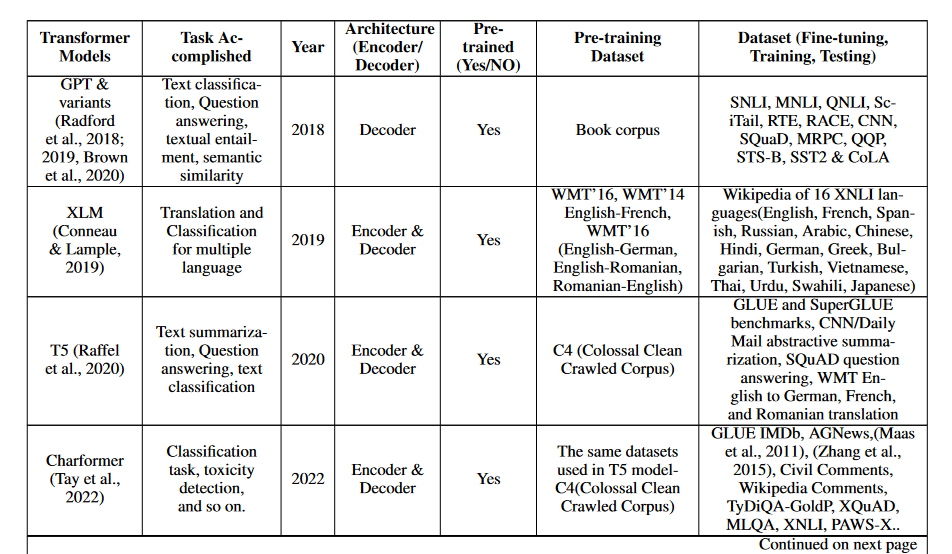
In the field of natural language processing, pre-trained models such as BERT and GPT, which are trained on large datasets, have become increasingly popular. However, the cost and environmental burden of developing these models has raised eyebrows. The Switch Transformer was developed as a solution to these problems; it allows for a more comprehensive model without significantly increasing the computational cost. A model with trillions of parameters is achieved by replacing the feed-forward neural network (FFN) with a switch layer containing multiple FFNs.
The computational cost of the Switch transformer is consistent with that of previous models, even as the size of the model increases. In fact, the Switch transformer has been tested on 11 different tasks, with impressive results across the board (Fedus et al., 2021). These include translation, question answering, classification, and summarization.
GPT & Variants
These models can be used for a variety of natural language processing (NLP) tasks, such as categorization, segmentation, question answering, and translation. Let us talk about GPT and its variants.
By focusing only on the decoder block of transformers, Generative Pre-Trained Transformer (GPT) models significantly advance the use of transformers in NLP. By combining unsupervised pre-training with supervised fine-tuning techniques, GPT takes a semi-supervised approach to language understanding (Radford et al., 2018).
Following the success of the GPT model in 2019, a pre-trained transformer-based model called GPT-2 with 1.5 billion parameters was introduced. This model significantly improved the pre-trained version of transformers (Radford et al., 2019). In the following years (2020), the most advanced pre-trained version of GPT, known as GPT-3, was made available. It had 175 billion parameters. This is ten times the size of any previous non-sparse language model. Unlike pre-trained models such as BERT (Brown et al., 2020), GPT-3 shows good performance on a variety of tasks without the need for gradient updates or fine-tuning.
T5
To boost its performance in downstream natural language processing (NLP) tasks, the T5 transformer model—short for "Text-to-Text Transfer Transformer"—introduced a dataset called "Colossal Clean Crawled Corpus" (C4). T5 is a general-purpose model that can be trained to perform many natural language processing (NLP) tasks using the same configuration. Following pre-training, the model can be customized for a variety of tasks and reaches a level of performance that is equivalent to that of various task-specific models (Raffel et al., 2020).
Conclusion
Transformes can be used to process language translation. They excel in modeling sequential data, such as natural language, and use a self-attention mechanism to convey information across input sequences. This makes them especially effective at modeling sequential data. Hugging Face, TensorFlow, PyTorch, and Huawei are just some of the examples of libraries and models that are available for using transformers for the purpose of language translation. These libraries include pre-trained transformer models for a variety of language translation applications, in addition to tools for fine-tuning and assessing the performance of models.
Reference
A Survey of Transformers: https://arxiv.org/abs/2106.04554











