
Introduction
With the rise of large language models (LLMs), we are thinking and approaching things differently for many tasks, from natural language processing and text generation to programming. From OpenAI’s GPT-3 and GPT-4 to Anthropic Claude, Google’s PaLM, and Apple’s Certainly, we are in a post-LLM era.
One of the most exciting tools is an open-source LLM for program synthesis that’s democratized everyone’s access to coding. It’s called CODEGEN. CODEGEN has been created by the Salesforce Research team. in this article, we will explore its capabilities and implications for the future of programming.
CODEGEN: Democratizing Program Synthesis
High-performance language models for program synthesis have been held back due to the lack of training resources and data – now, the Salesforce Research team has started to tackle this with a family of LLMs called CODEGEN with a size range from 1.5 billion to 16.1 billion parameters.
The innovation behind CODEGEN is the all-encompassing training. It draws on vast corpora of text in natural language and programming language, leading to a deep understanding by CODEGEN of human language and code. This allows it to excel at many program synthesis tasks.
The most impressive aspect of CODEGEN is its excellence on the HumanEval benchmark, the de facto standard evaluation for zero-shot code generation. By outperforming state-of-the-art models, CODEGEN illustrates the possibility of producing high-quality, functional code without fine-tuning a specific task.
Multi-Stage Training Approach of CodeGen for Enhanced Program Synthesis
CodeGen's transformer-based architecture utilizes self-attention mechanisms to capture complex relationships in natural language and code. What makes CodeGen unique is its multi-stage training approach that enables it to understand and produce codes across various programming languages with robust proficiency. The three pivotal stages involved in the CodeGen model's training process are:
- CODEGEN-NL: Initially pre-trained on The Pile, a large-scale curated dataset that includes code data. This stage establishes a foundation in natural language understanding.
- CODEGEN-MULTI: Building upon CODEGEN-NL, this stage includes training on BigQuery, a dataset containing code from multiple programming languages including C, C++, Go, Java, JavaScript, and Python.
- CODEGEN-MONO: The final stage focuses on Python-specific capabilities by training on BigPython, a dataset of Python code from GitHub repositories.
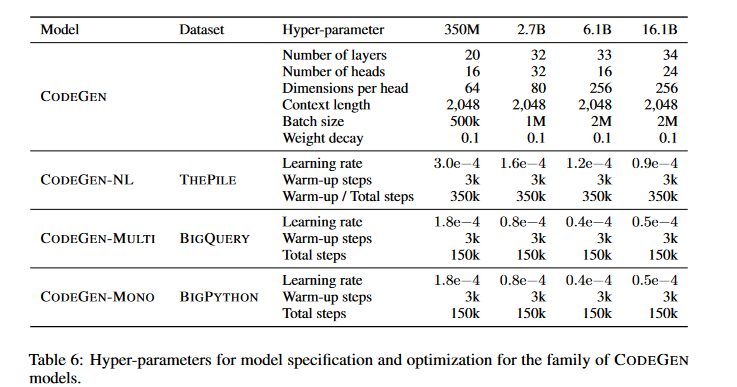
With the possibility of a sequential training approach, CodeGen can understand natural language and several programming languages. As such, it is an effective solution for tasks related to program synthesis.
Unlocking the Power of Multi-Turn Program Synthesis
Multi-turn program synthesis represents a cutting-edge methodology in code creation. In this approach users and systems engage in iterative interaction to incrementally craft, refine, and correct programs.
In stark contrast to conventional single-turn techniques that yield complete snippets from individual prompts alone, multi-turn synthesis facilitates linteractive development. This enables more complex and accurate code to be produced.
Key Concepts of Multi-Turn Program Synthesis
Here are some key concepts of Multi-turn program synthesis:
- Iterative Refinement: Multi-turn synthesis harnesses the cyclical character of user-machine collaboration. From initial input or a lofty description offered by the user, the model spins out a preliminary code draft. The user can then refine the prompt, ask for modifications, and specify corrections - all leading to progressive iterations that optimize the final output.
- Dialog-Based Interaction: This approach involves an interactive interface fostering conversation, where the user and model partake in a lively exchange of ideas. The model poses inquiries for further clarification, to which the user replies with additional details; and the model updates the code accordingly.
- Context Preservation: The ability of the system to preserve the conversation's context is essential in enhancing its comprehension of the user's intentions and efficiently integrating any modifications made. This is crucial for handling complex programming tasks that require multiple steps and adjustments.
Multi-Turn Code Generation with CODEGEN
This is impressive – no one should be underestimating CODEGEN, which still performed well for single-turn code generation tasks. Howerver the researchers building the model have taken these investigations further, exploring multi-turn program synthesis. In most program synthesis efforts, the task is to give the model a single, full input prompt, and let it try to spit out the program in one shot.
The Salesforce Research team realized that a more nuanced, step-by-step approach was often necessary, where a complex problem was pared down into small, modular subproblems.
To investigate this concept, the researchers developed the Multi-Turn Programming Benchmark (MTPB). It's comprehensive dataset consisting of 115 diverse problem sets that require multi-turn program synthesis. By evaluating CODEGEN's performance on this benchmark, they were able to demonstrate the significant advantages of a multi-turn approach over a single-turn approach.
Enhancing Code Generation Through Iterative Refinement
if a user is assigned to execute a linear regression model, he may request the model saying "Execute linear regression on X and Y." The assumption here is that the model understands this instruction fluently and presents an all-inclusive code snippet promptly. This technique can prove useful for simple tasks but becomes inadequate when confronted with more complex programming challenges.
Multi-turn programming synthesis revolutionizes this process. It splits tasks into smaller steps so they can be improved over time. For example, if we wanted to perform linear regression on x and y, instead of doing everything at once, the program would start by setting up basic structures like importing libraries and defining variables before completing the task.
The user will provide more prompts like " Fit the model with the data and print the coefficients" and he can say next "Predict the values for a new set of x and plot the results". This helps to ensure that each part of the task is addressed correctly and can be changed based on feedback from the user. The diagram below illustrates the single-turn and multi-turn examples for a linear regression task.
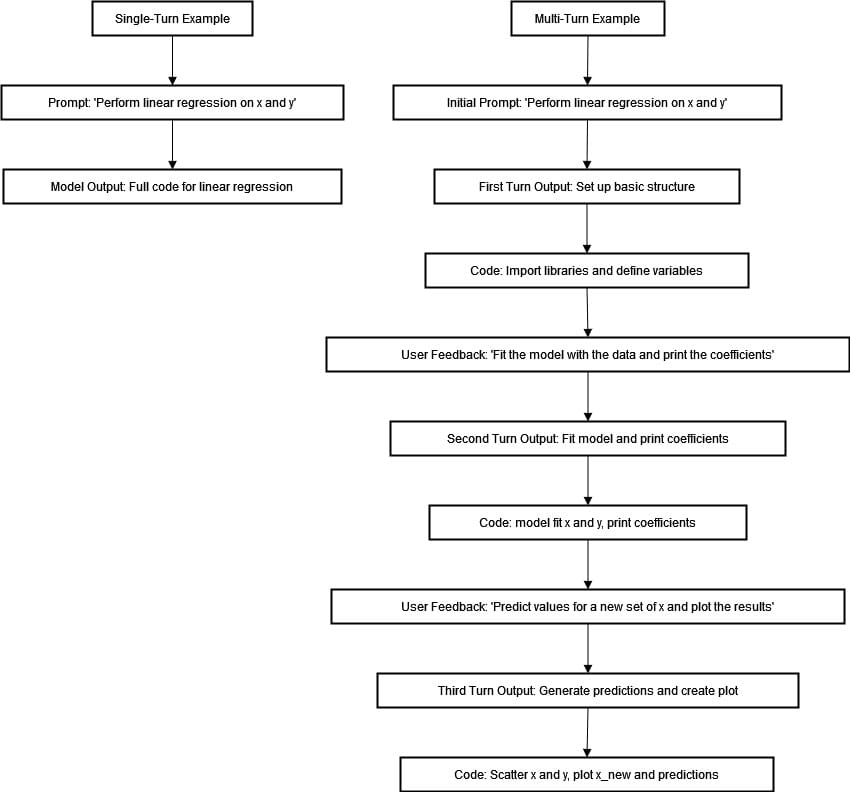
Using multiple turns has many benefits. It helps us control the coding process more accurately because each turn focuses on a particular task, which reduces errors. Getting feedback from the user throughout allows for adjustments to be made that better fit their needs and preferences.
The flowchart above capture the striking divergence that exists between single-turn and multi-turn programming synthesis when it comes to setting up a linear regression model. When using the former approach, users simply prompt: "Perform linear regression on x and y" craving for complete code generation instantaneously. However, this method proves limited in tackling complex coding challenges that demand understanding and iterative refinement.
In the multi-turn example, we take iterative steps to complete a process. The user starts with a prompt and gets structured responses that help set up basic framework like necessary libraries and variables. Each subsequent interaction involves feedback to guide the model through fitting data, printing coefficients, predicting new values, and creating visualizations.
Integrating CODEGEN with Hugging Face Transformers
The other crucial ingredient for a Hugging Face-based system is the Transformers library, a powerful all-purpose open-source toolkit that lets developers work with LLMs, including CODEGEN. Integrating CODEGEN into the Transformers library allows users to easily harness the model’s capabilities in their applications and workflows.
Here's an example of how you can use CODEGEN with the Hugging Face Transformers library:
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("Salesforce/codegen-2B-mono")
model = AutoModelForCausalLM.from_pretrained("Salesforce/codegen-2B-mono")
inputs = tokenizer("# this function prints hello world", return_tensors="pt")
sample = model.generate(**inputs, max_length=128)
print(tokenizer.decode(sample[0], truncate_before_pattern=[r"\n\n^#", "^'''", "\n\n\n"]))Output:

The code above demonstrates how to load the CODEGEN-2B-mono model and use it to generate code based on a given prompt. Here's a breakdown of the steps:
- Import the necessary functions from the Transformers library.
- Load the CODEGEN-2B-mono model and tokenizer using the
AutoTokenizerandAutoModelForCausalLMclasses. - Define the prompt, which is a comment indicating that the function should print "hello world".
- Generate the code completion using the
model.generate()function, specifying various parameters such as the maximum length of the output, the sampling strategy, and the number of sequences to generate. - Print the generated code by decoding the output tensor using the tokenizer.
The output of this code is a complete Python function that prints "hello world". We can also try using the other CODEGEN models, such as CODEGEN-2.0 and CODEGEN-2.5, by replacing the model and tokenizer paths accordingly. The models are available on the Hugging Face Hub.
Practical Applications for CODEGEN
The versatility of CODEGEN extends far beyond academic benchmarks, as it offers a wealth of practical applications across various industries and domains. There are some of the key use cases that showcase the power of this open-source language model.
Automated Code Generation
The most obvious use case for CODEGEN is code autogeneration. Developers will be able to create new software much more quickly by applying the natural language understanding built into CODEGEN. This is complemented by its natural language generation and automatic code-generation capabilities. This will save writing and maintenance time and effort to a significant extent, especially when rapid prototyping is needed, as well as being useful in an iterative development context.
Intelligent Code Assistance
CODEGEN can also be embedded in more intelligent forms of code assistance software that can provide developers with real-time, feature-based suggestions, code completion hints and code refactoring suggestions. In this manner, a language model can accelerate the rate at which developers can solve problems.
Conversational Programming Interfaces
The multi-turn capability of CODEGEN to support program synthesis enables the creation of conversational programming interface. The user can engage in natural language dialogue with the system that describes what they want the program to do, without needing to write code. This approach can be particularly useful for non-technical users or those with limited coding experience, as it removes the barrier of having to write code directly.
Domain-Specific Code Generation
Furthermore, CODEGEN can be fine-tuned or adapted to particular domains and industries. Its underlying knowledge and routine encapsulation could be set up and trained in any specific area, such as tthe financial sector, to generate customized trading algorithms or risk management models. Similarly, in the healthcare industry, CODEGEN can be used to create medical decision support systems or patient management apps.
Educational and Learning Applications
CODEGEN’s effective multi-turn synthesis can serve as an enhanced learning tool for students and aspiring programmers. By smoothly integrating step-by-step feedback into the synthesis process, CODEGEN can be effectively used as an interactive tutor. It helps foster the development of coding skills, programming tricks, and logical reasoning abilities. Such a system could be especially suitable in settings where learning takes place remotely or self‐paced.
Conclusion
Salesforce Research’s open-source large language model CODEGEN takes program synthesis to a new level. By combining the exponential capabilities inherent in large language models with the democratization brought about by providing access to these models, CODEGEN can leverage years of synthesis research. By incorporating new multi-turn synthesis capabilities, it has the potential to enable transformative approaches to programming and software development.
CODEGEN offers capabilities from synthesizing human-sounding code with a single input to interactive code help, conversational programming interfaces, and full-fledged domain-specific applications.
Undoubtedly there are more powerful use cases in natural language code synthesis waiting to be discovered. As the research community and industry push the boundaries of what can be achieved, we look forward to see even more groundbreaking applications in the industry.








