
Introduction
Over the last few years, a growing interest has been in testing the adversarial robustness of natural language processing (NLP) models. The research in this area covers new techniques for generating adversarial examples and defending against them. Comparing these attacks directly is challenging because they are evaluated on different data and victim models.
Replicating earlier work as a baseline takes time and increases the risk of errors because of missing source code. Perfectly replicating results is also challenging because of the tiny details left out of the publications. These issues create challenges for benchmark comparisons in this space.
Frameworks like TextAttack have been developed to address these challenges. It’s an NLP Python framework for adversarial attacks, data augmentation, and adversarial training. This framework addresses current challenges and inspires progress in adversarial robustness. Exploring TextAttack, this post goes into the details of its components. Additionally, practical implementations will be examined through in-depth code examples.
Key Components of TextAttack
TextAttack unifies adversarial attack methods by decomposing NLP attacks into four components:
- Goal Function: The objective of the attack is defined by the Goal Function, which can include altering the model's prediction or fooling it into making a particular error.
- Set of Constraints: They are rules that the attack must adhere to, for example limiting the number of words or guaranteeing that all modifications made are grammatically accurate.
- Transformation: The transformation determines how the input text is modified to generate an adversarial example. For example, the substitution of words with their synonyms or insertion/deletion of words.
- Search Method: This component determines how the attack explores the space of possible modifications to find the most effective adversarial example, such as using gradient-based methods or random search algorithms.
Main features of TextAttack
At the heart of TextAttack’s modular design are four main components, as we have mentioned above.
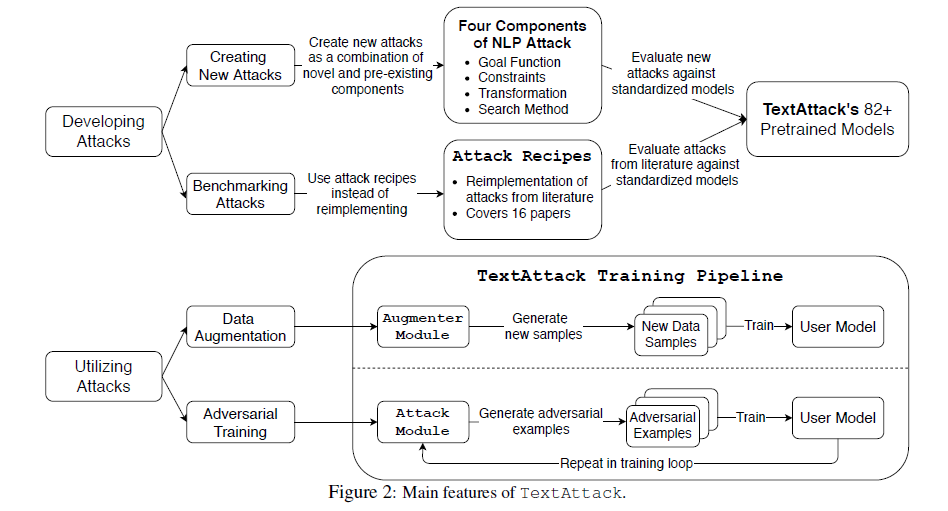
In the diagram the Attack Module section shows TextAttack’s ability to re-implement attacks from the literature. This section mentions that there are 16 papers and pre-built attack recipes that we can use.
The diagram shows how to use TextAttack to build attacks in two ways, creating new attacks and benchmarking existing ones. Users can create new adversarial strategies by combining new and existing components.
TextAttack has over 82 pre-trained models, so researchers can test their new attacks against standard models. This allows them to compare their results with previous work.
The figure shows two methods of attack: data augmentation and adversarial training. By using the Augmenter Module, user models can improve by generating new samples to augment the existing training dataset. With TextAttack’s training pipeline, we can create adversarial examples and feed them into a training process to improve our model.
TextAttack's Pre-trained Models and Datasets
TextAttack's pre-trained models include word-level LSTM and CNN modules alongside transformer-based BERT variants. These models have undergone pre-training on diverse datasets supplied by HuggingFace.
Integration of TextAttack with the NLP library enables automatic loading of corresponding pre-trained models for test and validation datasets. While much prior literature has focused on classification and entailment, TextAttack's range of pre-trained models provides a new avenue for research. This allows researchers to delve into studies regarding model robustness across all GLUE tasks.
Adversarial Training
With the text attack train --attack recipes, TextAttack enables the creation of new training sets of adversarial examples. The process involves several steps:
- Initial training: The model is trained for a number of epochs on the clean training set.
- Adversarial example generation: An attack makes an adversarial version of each input.
- Dataset substitution: This process involves replacing the original dataset with a perturbed variant.
- Periodic regeneration: The adversarial dataset is periodically regenerated according to the model’s current weaknesses.
The table below illustrates the accuracy of a standard LSTM classifier with and without adversarial training against various attack recipes used in TextAttack.
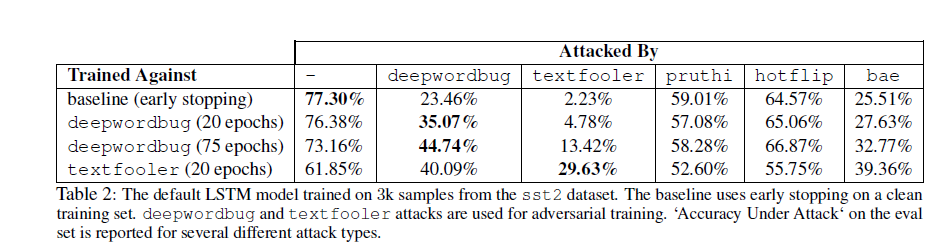
It shows the LSTM model's performance against deepwordbug, textfooler, pruthi, hotflip, and bae attacks compared to its baseline Carlini score on the clean training set. The table compares accuracy with and without attacks, evaluating the model's robustness against deepwordbug at 20 and 75 epochs respectively. It also assesses the model's vulnerability to textfooler at 20 epochs.
Benchmarking Existing Attacks with Attack Recipes
TextAttack allows for a modular structure to combine multiple past research attacks into one framework. This is achieved by adding one or two new components and we get more flexibility and productivity in creating new attack plans.
An attack recipe is a set of pre-defined steps and configurations used to produce adversarial examples for NLP models. Each attack recipe has four main components (Goal Function, Constraints, Transformation, Search Method)
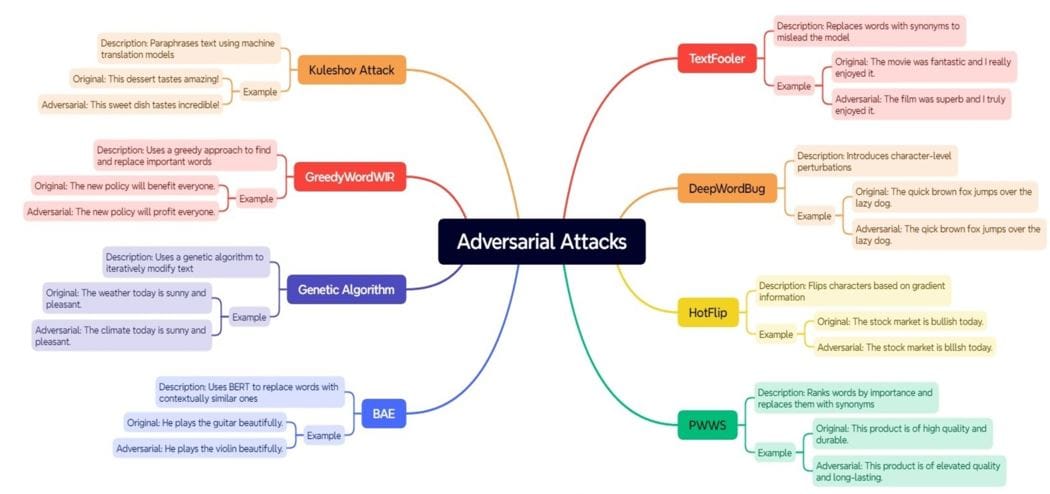
Attack recipes are the best practices and techniques distilled from the latest research. They speed up the production of adversarial examples. Helping both researchers and practitioners in their work these allow us to implement complex attack strategies without having to know all the underlying details. We have illustrated some common types of attacks in the diagram below:
Practical Use Case: Sentiment Analysis
Let’s consider that we have a sentiment analysis model that classifies movie reviews into positive or negative categories. We want to test the strength and robustness of this model using textfooler attack recipe. The input given was “The movie was great” and the model predicted positive sentiment. Let’s see the process in the diagram below.
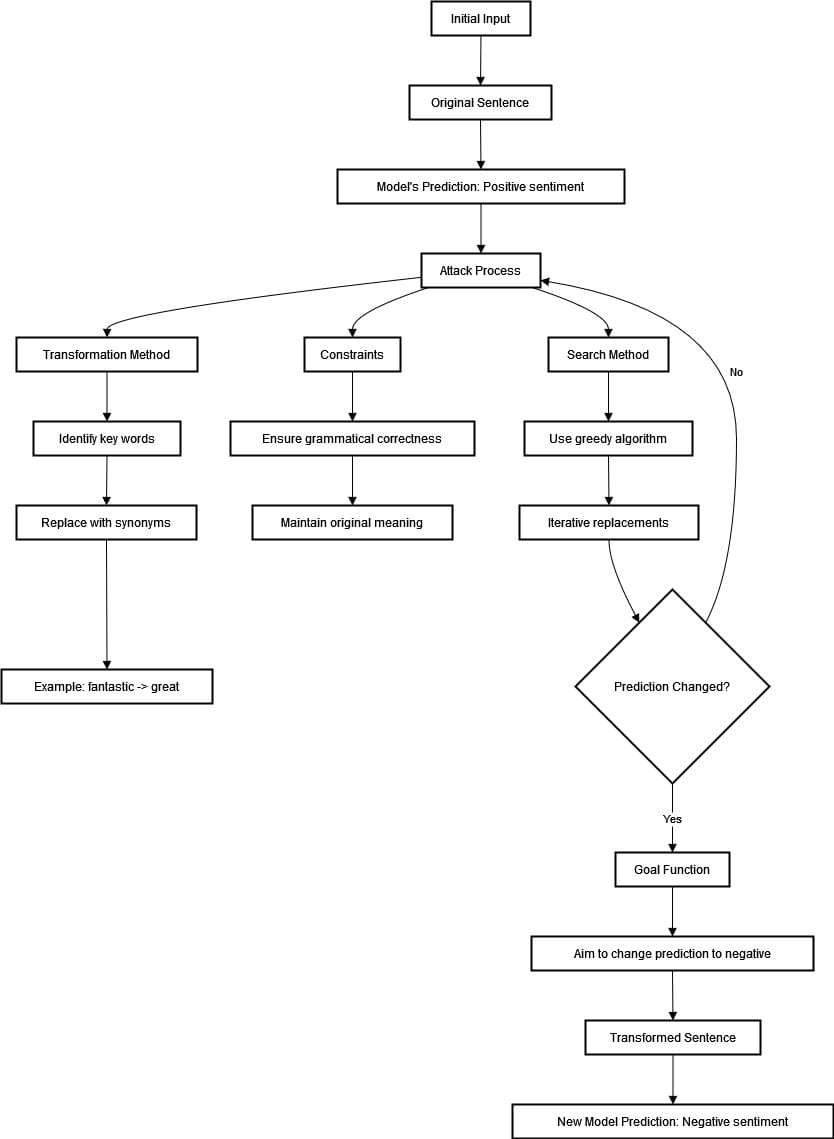
To start the attack process, we must find important words related to positive sentiment in a statement. For example, “fantastic” can be replaced with synonyms using the WordNet database.
We want to preserve grammatical correctness and original meaning as much as possible. We use an iterative approach in the greedy algorithm where the model’s prediction is checked at each replacement.
The process continues until no more substitutions that achieve the desired result can be made or a change in the prediction occurs. A successful attack on the model may occur by replacing the word "fantastic" with an equivalent like "great," which flips sentiments from positive to negative.
In this case, the initial statement "The movie was fantastic" has been changed to "The movie was great," as we can see the model’s prediction has changed from positive to negative. This is proof of a vulnerability in the model.
textfooler is a clever scheme designed to expose deficiencies in sentiment analysis models. This technique can significantly influence model predictions by substituting keywords with their synonyms while maintaining contextual coherence. This compels us to prioritize training and evaluation frameworks that minimize vulnerability to such adversarial attacks.
Enhancing Adversarial NLP Attacks with TextAttack's AttackedText Object
When using conventional NLP attack implementations, making changes to tokenized text can often lead to problems with capitalization and word segmentation. Tokenization involves breaking down the text into separate words or tokens, which may cause disruptions in its initial capital letters and boundaries between words.
Tokenizing "The movie was fantastic!" could lead to "the", "movie", "was", or "fantastic!" which omits the capitalized letter at the beginning. This makes transformations more difficult. Such concerns can weaken adversarial examples' consistency and validity while impeding accurate assessments of NLP models' resilience.
TextAttack's AttackedText object tackles these issues by enabling transformations to be performed directly on the original text instead of tokenized versions. The object keeps hold of the initial input and preserves all its attributes, such as capitalization and word boundaries.
The helper methods included with this object facilitate controlled modifications. They can manage challenges like transformations in capitalization or adjustments for specific word boundaries. Let's consider as an example a transformation that substitutes "Hello" with "Hi". It will not produce an erroneous output like "hi World!" but rather correctly transforms "Hello World!" into ""Hi World!".
The utilization of the AttackedText object bestows various advantages. It generates adversarial examples by maintaining the authenticity of the original text structure and capitalization during transformations. The precision in word segmentation and capitalization augments the reliability of attacks on models. This leads to a trustworthy evaluation process for model robustness.
Moreover, developers can focus on producing efficient changes devoid of tokenization hurdles that hinder the adoption of new attacks. In essence, the AttackedText component amplifies and enhances TextAttack's adversarial transformation abilities by a great margin.
During an attack using TextAttack's search methods, it is common to encounter the same input multiple times. In such instances, storing (or caching) previously computed results can greatly improve efficiency.
Improving Efficiency in TextAttack with Caching
During an attack using TextAttack's search methods, it is common to meet the same input multiple times. Storing (or caching) previously computed results can improve efficiency in such instances.
TextAttack can expedite the retrieval of pre-calculated model output and verify if all constraints were met without repeating the task. This process is known as memoization. Through this optimization technique, search methods execute faster and enhance overall efficiency during an attack.
Let's consider an application of TextAttack in which we assess the robustness of a sentiment analysis model by testing it with adversarial examples. Let's visualize and explain the process in the diagram below.
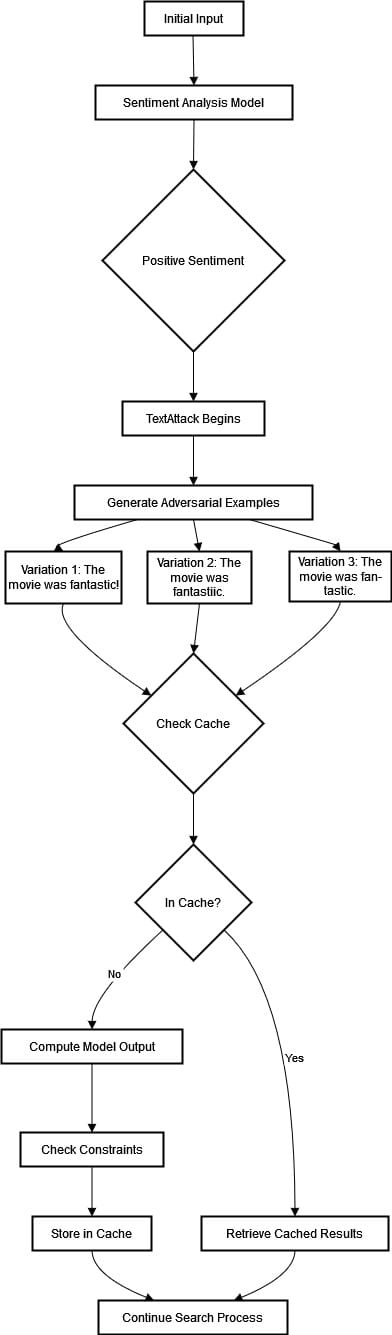
Adversarial example generation with caching- Initial Input: The opening statement reads, "The movie was fantastic." The sentiment analyzer accurately recognizes the emotional tone that characterizes it as a positive sentiment.
- Adversarial Attack: TextAttack uses an adversarial attack technique where cunning modifications are applied to the original sentence to manipulate the model's prediction. Examples with altered wording - for instance, "The movie was fantastic!" or "The movie was fantastic."- may be part of this process.
- Caching: Engaging the power of caching, Variations posing as duplicates are identified and sorted out in real-time to optimize efficiency, preventing needless reprocessing. For instance, if "The movie was fantastic." is generated repeatedly - either verbatim or with slight modifications - the system will use cached responses that were previously computed upon the first encounter. Constraints are always cross-checked for coherence before any further action is taken on a particular piece of language under scrutiny by TextAttack's sophisticated algorithmic models.
- Efficiency Gain: TextAttack's efficiency gain is impressive. Imagine encountering the same delightful phrase, "The movie was fantastic," while continuing our search journey. Our tool no longer needs to compute its output or monitor for any constraints because it retrieves cached results. This spares our precious time, conserves computing power, and leads to a smoother ride toward successful results.
Custom Transformation
A straightforward transformation will be attempted to initiate the creation of transformations in TextAttack: changing any word with the word "banana." Within TextAttack, an abstract class called WordSwap undertakes to break down sentences into words while avoiding swapping stopwords. By extending WordSwap and executing only one function - _get_replacement_words – all terms can be substituted with "banana".
Prior to executing the subsequent codes, please run the following command in your environment:
pip3 install textattack[tensorflow] The following code defines a custom transformation class BananaWordSwap that inherits from WordSwap. It replaces any given word in the input with the word "banana".
from textattack.transformations import WordSwap
class BananaWordSwap(WordSwap):
"""Transforms an input by replacing any word with 'banana'."""
# We don't need a constructor, since our class doesn't require any parameters.
def _get_replacement_words(self, word):
"""Returns 'banana', no matter what 'word' was originally.
Returns a list with one item, since `_get_replacement_words` is intended to
return a list of candidate replacement words.
"""
return ["banana"]
Using transformation
The transformation has been selected. However, a few items are still missing for the attack to be completed. The search method and constraints must also be chosen to fulfill the attack. Furthermore, we require a goal function, model, and dataset before using this strategy. (The goal function indicates the task our model performs – in this case, classification – and the type of attack – in this case, we’ll perform an untargeted attack.)
Creating the Goal Function, Model, and Dataset
Our mission is to launch an attack on a classification model. Therefore, we shall employ the UntargetedClassification class. For our task, let's go for BERT, refined specifically for news categorization using the AG News dataset. No need to worry as many models are prepared and conveniently stored in HuggingFace's Model Hub. TextAttack synergistically merges with any of these high-quality models and their datasets.
# Import the model
import transformers
from textattack.models.wrappers import HuggingFaceModelWrapper
model = transformers.AutoModelForSequenceClassification.from_pretrained(
"textattack/bert-base-uncased-ag-news"
)
tokenizer = transformers.AutoTokenizer.from_pretrained(
"textattack/bert-base-uncased-ag-news"
)
model_wrapper = HuggingFaceModelWrapper(model, tokenizer)
# Create the goal function using the model
from textattack.goal_functions import UntargetedClassification
goal_function = UntargetedClassification(model_wrapper)
# Import the dataset
from textattack.datasets import HuggingFaceDataset
dataset = HuggingFaceDataset("ag_news", None, "test")
Creating the Attack
Let’s use a greedy search method. We'll not use any constraints for now.
from textattack.search_methods import GreedySearch
from textattack.constraints.pre_transformation import (
RepeatModification,
StopwordModification,
)
from textattack import Attack
# We're going to use our Banana word swap class as the attack transformation.
transformation = BananaWordSwap()
# We'll constrain modification of already modified indices and stopwords
constraints = [RepeatModification(), StopwordModification()]
# We'll use the Greedy search method
search_method = GreedySearch()
# Now, let's make the attack from the 4 components:
attack = Attack(goal_function, constraints, transformation, search_method)
We can print our attack to see all the parameters:
print(attack)Output:
Attack(
(search_method): GreedySearch
(goal_function): UntargetedClassification
(transformation): BananaWordSwap
(constraints):
(0): RepeatModification
(1): StopwordModification
(is_black_box): True
)
Using the Attack
Let’s use our attack to successfully attack 10 samples.
from tqdm import tqdm # tqdm provides us a nice progress bar.
from textattack.loggers import CSVLogger # tracks a dataframe for us.
from textattack.attack_results import SuccessfulAttackResult
from textattack import Attacker
from textattack import AttackArgs
from textattack.datasets import Dataset
attack_args = AttackArgs(num_examples=10)
attacker = Attacker(attack, dataset, attack_args)
attack_results = attacker.attack_dataset()
# The following legacy tutorial code shows how the Attack API works in detail.
# logger = CSVLogger(color_method='html')
# num_successes = 0
# i = 0
# while num_successes < 10:
# result = next(results_iterable)
# example, ground_truth_output = dataset[i]
# i += 1
# result = attack.attack(example, ground_truth_output)
# if isinstance(result, SuccessfulAttackResult):
# logger.log_attack_result(result)
# num_successes += 1
# print(f'{num_successes} of 10 successes complete.')
Output:
+-------------------------------+--------+
| Attack Results | |
+-------------------------------+--------+
| Number of successful attacks: | 8 |
| Number of failed attacks: | 2 |
| Number of skipped attacks: | 0 |
| Original accuracy: | 100.0% |
| Accuracy under attack: | 20.0% |
| Attack success rate: | 80.0% |
| Average perturbed word %: | 18.71% |
| Average num. words per input: | 63.0 |
| Avg num queries: | 934.0 |
+-------------------------------+--------+
In the code above, the TextAttack library is utilized to carry out an adversarial attack on a dataset. Essential modules are imported, including tqdm for progress bars and CSVLogger for recording attack outcomes. To run the attack on 10 examples, we have used the AttackArgs class.
We have created the Attacker object with a designated attack type, corresponding dataset, and any necessary arguments. Next, we have executed the attack_dataset method to carry out the attack and obtain the result. Alternatively, we can log successful attacks manually by going through each element in the dataset, performing the attack, and logging the results if the attack is successful. – as evidenced by code contained in a commented-out section of this script snippet.
A success rate of 80% was achieved in the adversarial attack on the text classification model. Of the ten attempts made, eight successfully led to misclassification of inputs by causing a drop in accuracy from its previous perfect score to just 20%.
The attack strategy proved its robustness and effectiveness, as no skipped attacks were recorded. On average, each query had 18.71% of the words modified in an input that contained approximately 63 words. Moreover, the model was queried around 934 times per input during the attack process.
Visualizing Attack Results
In the below code, we have used CSVLogger method to log AttackResult objects. This logger effectively stores all resulting attacks into a data frame. It facilitates easy accessibility and display of information. By setting color_method to 'html', disparities in attack results are represented via HTML coloring for increased visual clarity. We have used IPython utilities and pandas in this process.
import pandas as pd
pd.options.display.max_colwidth = (
480 # increase colum width so we can actually read the examples
)
logger = CSVLogger(color_method="html")
for result in attack_results:
if isinstance(result, SuccessfulAttackResult):
logger.log_attack_result(result)
from IPython.core.display import display, HTML
results = pd.DataFrame.from_records(logger.row_list)
display(HTML(results[["original_text", "perturbed_text"]].to_html(escape=False)))
Note: The reader can launch the code and visualize the result.
Conclusion
This article offers an extensive analysis of adversarial robustness within NLP models, specifically emphasizing the TextAttack Python framework. It's a Python-based framework intended to streamline and enhance the generation process and defense mechanisms against adverse attacks.
This framework presents a modular architecture incorporating fundamental components such as Goal Function, Constraints, Transformation, and Search Method. This structure empowers the users to create customized attacks efficiently. It also facilitates easy adaptation and standardized performance evaluation through benchmarking.
The framework extends support towards adversarial training practices with data augmentation techniques. This enhances model robustness in real-world application scenarios. The efficiency of this framework is demonstrated through empirical illustrations. These highlight its practical utility across various domains.











