
In today's world, the use of artificial intelligence and machine learning has become essential in solving real-world problems. Models like large language models or vision models have captured attention due to their remarkable performance and usefulness. If these models are running on a cloud or a big device, this does not create a problem. However, their size and computational demands pose a major challenge when deploying these models on edge devices or for real-time applications.
Devices like edge devices, what we call smartwatches or Fitbits, have limited resources, and quantization is a process to convert these large models in a manner that these models can easily be deployed to any small device.
With the advancement in A.I. technology, the model complexity is increasing exponentially. Accommodating these sophisticated models on small devices like smartphones, IoT devices, and edge servers presents a significant challenge. However, quantization is a technique that reduces machine learning models' size and computational requirements without significantly compromising their performance. Quantization has proven useful in enhancing large language models' memory and computational efficiency (LLMs). Hence making these powerful models more practical and accessible for everyday use.
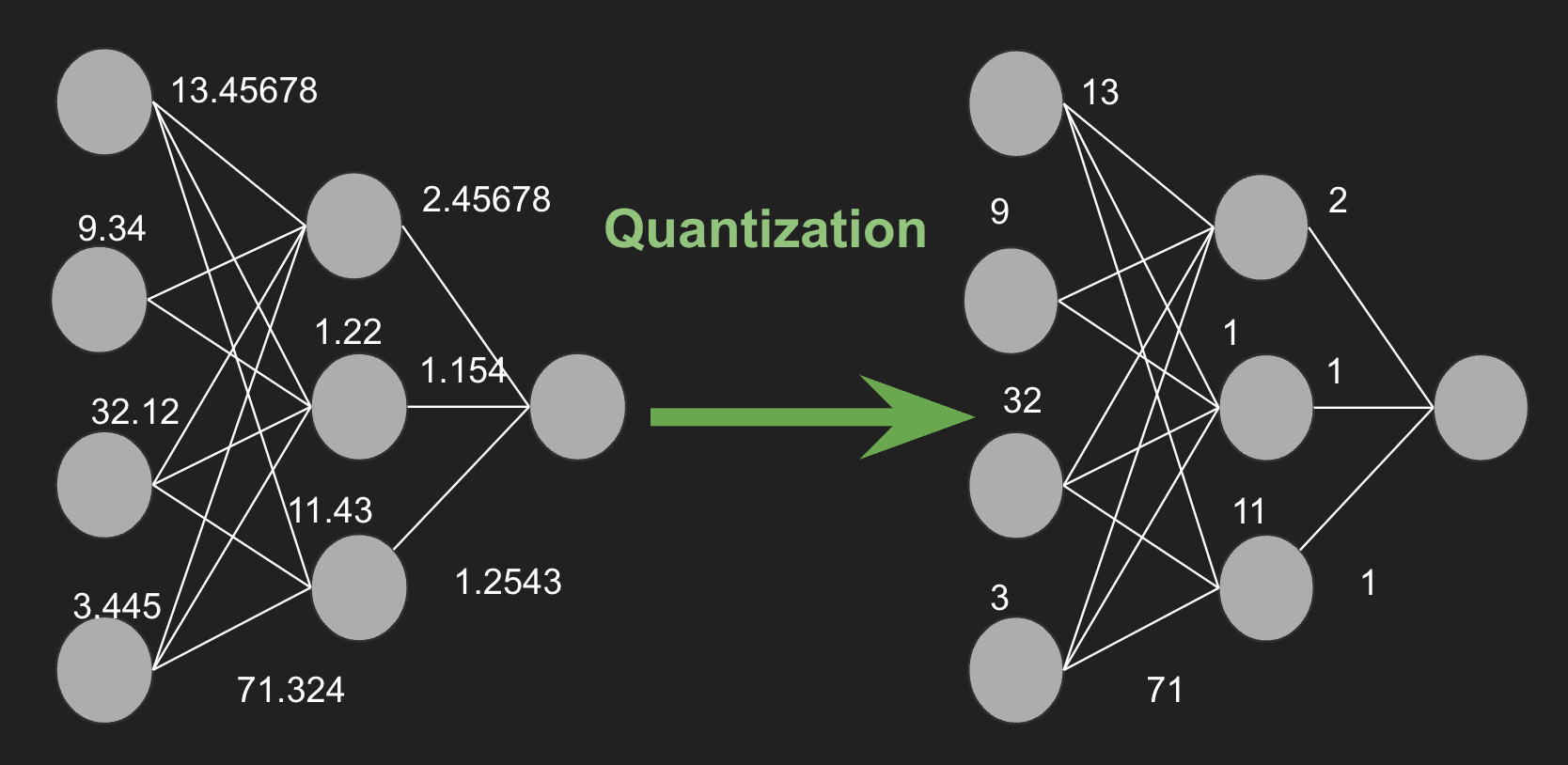
Model quantization involves transforming the parameters of a neural network, such as weights and activations, from high-precision (e.g., 32-bit floating point) representations to lower-precision (e.g., 8-bit integer) formats. This reduction in precision can lead to substantial benefits, including decreased memory usage, faster inference times, and reduced energy consumption.
What is Model Quantization? Benefits of Model Quantization
Quantization is a technique that reduces the precision of model parameters, thereby decreasing the number of bits needed to store each parameter. For instance, consider a parameter with a 32-bit precision value of 7.892345678. This value can be approximated as the integer 8 using 8-bit precision. This process significantly reduces the model size, enabling faster execution on devices with limited memory.
In addition to reducing memory usage and improving computational efficiency, quantization can also lower power consumption, which is crucial for battery-operated devices. Quantization also leads to faster inference by reducing the precision of model parameters; quantization decreases the amount of memory required to store and access these parameters.
There are various types of quantization, including uniform and non-uniform quantization, as well as post-training quantization and quantization-aware training. Each method has its own set of trade-offs between model size, speed, and accuracy, making quantization a versatile and essential tool in deploying efficient AI models on a wide range of hardware platforms.
Different Techniques for Model Quantization
Model quantization involves various techniques to reduce the size of the model parameters while maintaining the performance. Here are some common techniques:
1. Post-Training Quantization
Post-training quantization (PTQ) is applied after the model has been fully trained. PTQcan reduce a model's accuracy because some of the detailed information in the original floating point values might be lost when the model is compressed.
- Accuracy Loss: When PTQ compresses the model, it may lose some important details, which can reduce the model's accuracy.
- Balancing Act: To find the right balance between making the model smaller and keeping its accuracy high, careful tuning and evaluation are needed. This is especially important for applications where accuracy is very critical.
In short, PTQ can make the model smaller but may also reduce its accuracy, so it requires careful calibration to maintain performance.
It's a straightforward and widely used approach, offering several sub-methods:
- Static Quantization: Converts the weights and activations of a model to lower precision. Calibration data is used to determine the range of activation values, which helps in scaling them appropriately.
- Dynamic Quantization: Only weights are quantized, while activations remain in higher precision during inference. The activations are quantized dynamically based on their observed range during runtime.
2. Quantization-Aware Training
Quantization-aware training (QAT) integrates quantization into the training process itself. The model is trained with quantization simulated in the forward pass, allowing the model to learn to adapt to the reduced precision. This often results in higher accuracy compared to post-training quantization because the model can better compensate for the quantization errors. QAT involves adding extra steps during training to mimic how the model will perform when it’s compressed. This means tweaking the model to handle this mimicry accurately. These extra steps and adjustments make the training process more computationally demanding. It requires more time and computational power. After training, the model needs thorough testing and fine-tuning to ensure it doesn’t lose accuracy. This adds more complexity to the overall training process.
3. Uniform Quantization
In uniform quantization, the value range is divided into equally spaced intervals. This is the simplest form of quantization, often applied to both weights and activations.
4. Non-Uniform Quantization
Non-uniform quantization allocates different sizes to intervals, often using methods like logarithmic or k-means clustering to determine the intervals. This approach can be more effective for parameters with non-uniform distributions, potentially preserving more information in critical ranges.
5. Weight Sharing
Weight sharing involves clustering similar weights and sharing the same quantized value among them. This technique reduces the number of unique weights, leading to further compression. Weight-sharing quantization is a technique to save energy using large neural networks by limiting the number of unique weights.
Benefits:
- Noise Resilience: The method is better at handling noise.
- Compressibility: The network can be made smaller without losing accuracy.
6. Hybrid Quantization
Hybrid quantization combines different quantization techniques within the same model. For example, weights may be quantized to 8-bit precision while activations remain at higher precision, or different layers might use different levels of precision based on their sensitivity to quantization. This technique reduces the size and speeds up neural networks by applying quantization to both the weights (the model's parameters) and the activations (the intermediate outputs).
- Quantizing Both Parts: It compresses both the model's weights and the activations it calculates as it processes data. This means both are stored and processed using fewer bits, which saves memory and speeds up computation.
- Memory and Speed Boost: By reducing the amount of data the model needs to handle, hybrid quantization makes the model smaller and faster.
- Complexity: Because it affects both weights and activations, it can be trickier to implement than just quantizing one or the other. It needs careful tuning to make sure the model stays accurate while being efficient.
7. Integer-Only Quantization
In integer-only quantization, both weights and activations are converted to integer format, and all computations are performed using integer arithmetic. This technique is especially useful for hardware accelerators that are optimized for integer operations.
8. Per-Tensor and Per-Channel Quantization
- Per-Tensor Quantization: Applies the same quantization scale across an entire tensor (e.g., all weights in a layer).
- Per-Channel Quantization: Uses different scales for different channels within a tensor. This method can provide better accuracy, particularly for convolutional neural networks, by allowing finer granularity in quantization.
9. Adaptive Quantization
Adaptive quantization methods adjust the quantization parameters dynamically based on the input data distribution. These methods can potentially achieve better accuracy by tailoring the quantization to the specific characteristics of the data.
Each of these techniques has its own set of trade-offs between model size, speed, and accuracy. Selecting the appropriate quantization method depends on the specific requirements and constraints of the deployment environment.
Challenges and Considerations for Model Quantization
Implementing model quantization in AI involves navigating several challenges and considerations. One of the main issues is the accuracy trade-off, as reducing the precision of the model's numerical data can decrease its performance, especially for tasks requiring high precision. To manage this, techniques like quantization-aware training, hybrid approaches that mix different precision levels, and iterative optimization of quantization parameters are employed to preserve accuracy. Additionally, compatibility across various hardware and software platforms can be problematic, as not all platforms support quantization uniformly. Addressing this requires extensive cross-platform testing, using standardized frameworks like TensorFlow or PyTorch for broader compatibility, and sometimes developing custom solutions tailored to specific hardware to ensure optimal performance.
Real-World Applications
Model quantization is widely used in various real-world applications where efficiency and performance are critical. Here are a few examples:
- Mobile Applications: Quantized models are used in mobile apps for tasks like image recognition, speech recognition, and augmented reality. For instance, a quantized neural network can run efficiently on smartphones to recognize objects in photos or provide real-time translation of spoken language, even with limited computational resources.
- Autonomous Vehicles: In self-driving cars, quantized models help process sensor data in real time, such as identifying obstacles, reading traffic signs, and making driving decisions. The efficiency of quantized models allows these computations to be done quickly and with lower power consumption, which is crucial for the safety and reliability of autonomous vehicles.
- Edge Devices: Quantization is essential for deploying AI models on edge devices like drones, IoT devices, and smart cameras. These devices often have limited processing power and memory, so quantized models enable them to perform complex tasks like surveillance, anomaly detection, and environmental monitoring efficiently.
- Healthcare: In medical imaging and diagnostics, quantized models are used to analyze medical scans and detect anomalies like tumors or fractures. This helps in providing faster and more accurate diagnoses while running on hardware with restricted computational capabilities, such as portable medical devices.
- Voice Assistants: Digital voice assistants like Siri, Alexa, and Google Assistant use quantized models to process voice commands, understand natural language, and provide responses. Quantization allows these models to run quickly and efficiently on home devices, ensuring smooth and responsive user interactions.
- Recommendation Systems: Online platforms like Netflix, Amazon, and YouTube use quantized models to provide real-time recommendations. These models process large amounts of user data to suggest movies, products, or videos, and quantization helps in managing the computational load while delivering personalized recommendations promptly.
Quantization enhances AI models' efficiency, enabling deployment in resource-constrained environments without sacrificing performance significantly and improving user experience across a wide range of applications.
Concluding Thoughts
Quantization is a vital technique in the field of artificial intelligence and machine learning that addresses the challenge of deploying large models to edge devices. Quantization significantly decreases the memory footprint and computational demands of neural networks, enabling their deployment on resource-constrained devices and real-time applications.
A few of the benefits of quantization, as discussed in this article, are reduced memory usage, faster inference times, and lower power consumption. Techniques such as uniform and non-uniform quantization and innovative approaches.
Despite its advantages, quantization also presents challenges, particularly in maintaining model accuracy. However, with recent research and advancements in quantization methods, researchers continue to work on these challenges, pushing the boundaries of what is achievable with low-precision computations. As the deep learning community continues to innovate, quantization will play an integral role in the deployment of powerful and efficient AI models, making sophisticated AI capabilities accessible to a broader range of applications and devices.
In conclusion, quantization is so much more than just a technical optimization - it plays a vital role in AI advancements.
We hope you enjoyed the article!











