
Artificial intelligence (AI) can solve some of the world's biggest problems, but only if everyone has the tools to use it. On Jun 27, 2024, Google, a leading player in AI technology, launched Gemma 2 9B and 27B—a set of lightweight, advanced AI models. These models, built with the same technology as the famous Gemini models, make AI accessible to more people, marking a significant milestone in democratizing AI.
Gemma 2 comes in two sizes: 9 billion (9B) and 27 billion (27B) parameters, and comes with a context length of 8K tokens. Google claims the model performs better and is more efficient than the first Gemma models. Gemma 2 also includes necessary safety improvements. The 27B model is so powerful that it competes with models twice its size, and it can run on a single NVIDIA H100 Tensor Core GPU or TPU host, lowering its cost.
Paperspace is revolutionizing AI development by providing affordable access to powerful GPUs like H100 and A4000, enabling more researchers and developers to run advanced, lightweight models. With their cloud-based platform, users can easily access high-performance NVIDIA GPUs at a fraction of the cost of traditional infrastructure.
This democratizes AI by reducing entry barriers and enabling advanced models like Gemma 2 for inclusive and accelerated progress in artificial intelligence.
Need for a lightweight model
Lightweight AI models are essential for making advanced technology more accessible, efficient, cost-effective, and sustainable. They enable various applications. Furthermore, these models drive innovation and address diverse challenges worldwide.
There are several reasons why Lightweight models are essential in various fields:
- Speed: Due to their reduced size and complexity, lightweight models often have faster inference times. This is crucial for real-time or near-real-time data processing applications like video analysis, autonomous vehicles, or online recommendation systems.
- Low Computational Requirements: Lightweight models typically require fewer computational resources (such as memory and processing power) than larger models. This makes them suitable for deployment on devices with limited capabilities, such as smartphones, IoT, or edge devices.
- Scalability: Lightweight models are more accessible to scale across many devices or users. This scalability is particularly advantageous for applications with a broad user base, such as mobile apps, where deploying large models might not be feasible.
- Cost-effectiveness: The lightweight models can reduce operational costs associated with deploying and maintaining AI systems. They consume less energy and can run on less expensive hardware, making them more accessible and economical for businesses and developers.
- Deployment in resource-constrained environments: In environments where internet connectivity is unreliable or bandwidth is limited, lightweight models can operate effectively without requiring continuous access to cloud services.
Lightweight models like Gemma 2 are crucial because they allow more people and organizations to leverage advanced AI technology, drive innovation, and create solutions for diverse challenges, all while being mindful of costs and sustainability.
Introducing Gemma 2
Gemma 2 is Google's latest iteration of open-source Large Language Models (LLMs), featuring models with 9 billion (gemma-2-9b) and 27 billion (gemma-2-27b) parameters, including instruction fine-tuned variants. These models were trained on extensive datasets—13 trillion tokens for the 27B version and 8 trillion tokens for the 9B version—which includes web data, English text, code, and mathematical content. With an 8,000-token context length, Gemma 2 offers enhanced performance in tasks such as language understanding and text generation, attributed to improved data curation and larger training datasets. Released under a permissive license, Gemma 2 supports redistribution, commercial use, fine-tuning, and derivative works, fostering widespread adoption and innovation in AI applications. A few of the technical enhancements include interleaving local-global attention and group-query attention. Additionally, the 2B and 9B models utilize knowledge distillation instead of next token prediction, resulting in superior performance relative to their size and competitive alternatives to models 2-3 times larger.
Gemma2 performance
During Gemma 2's training, strict safety protocols were maintained. This included filtering pre-training data and conducting thorough testing across various metrics to detect and address potential biases and risks.
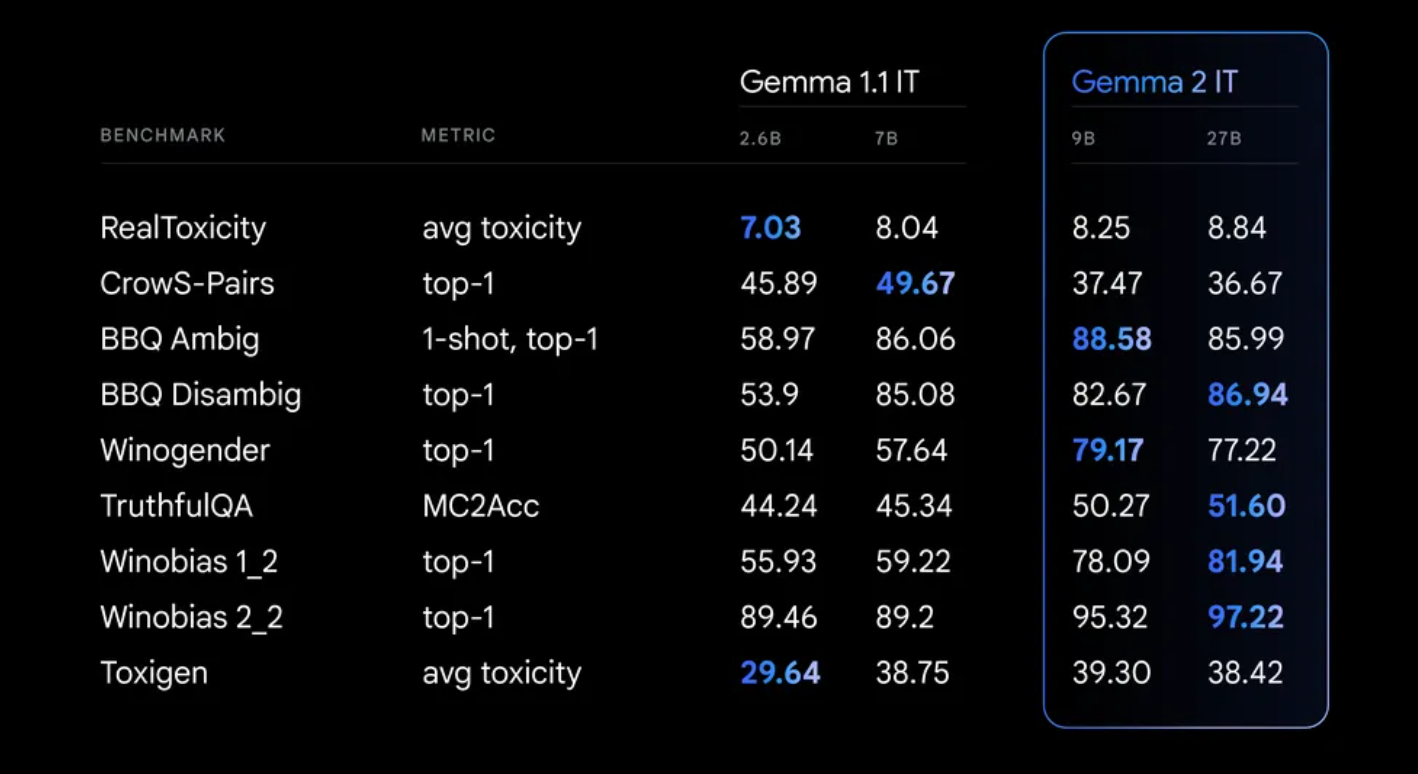
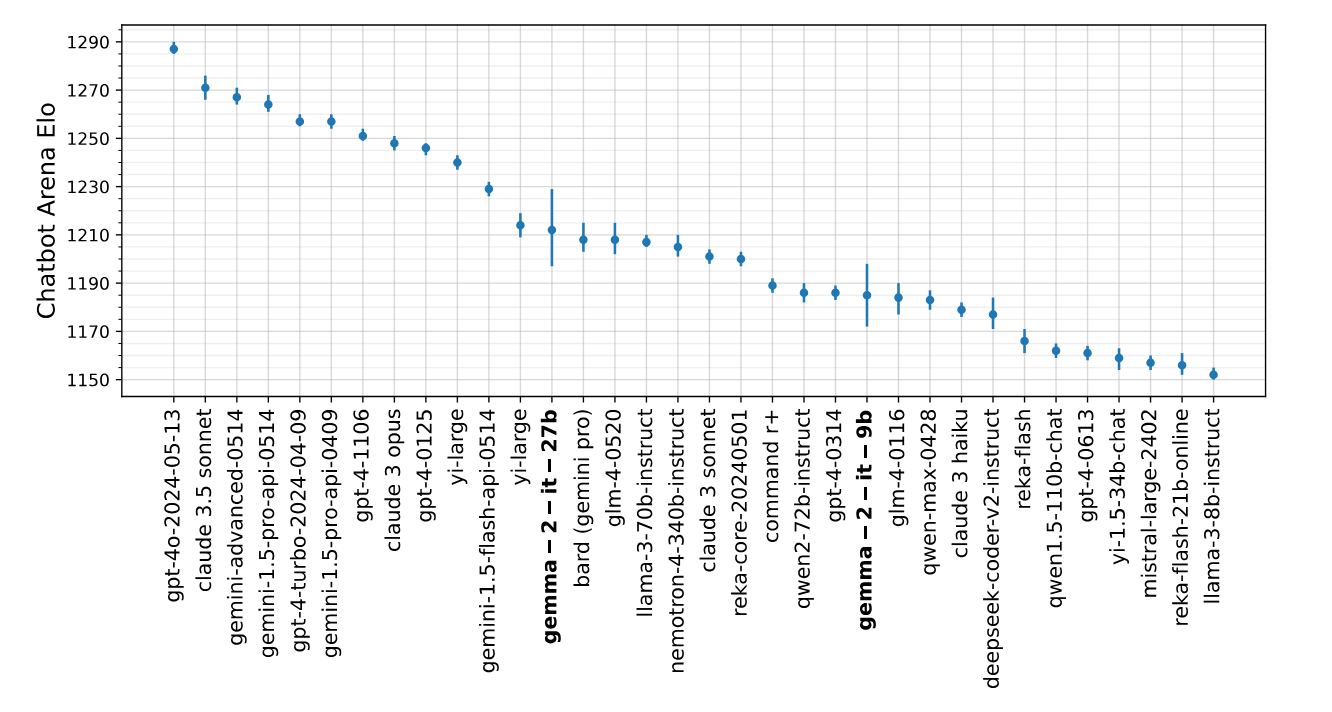
Discover the power of Gemma 2: A Paperspace demo
We've successfully tested the model with Ollama and NVIDIA RTX A4000! Check out our helpful article on downloading Ollama and accessing any LLM model. Plus, Gemma2 works seamlessly with Ollama.
Ready to download the model and get started?
Bring this project to life
Before we get started, let's gather some information about the GPU configuration.
nvidia-smi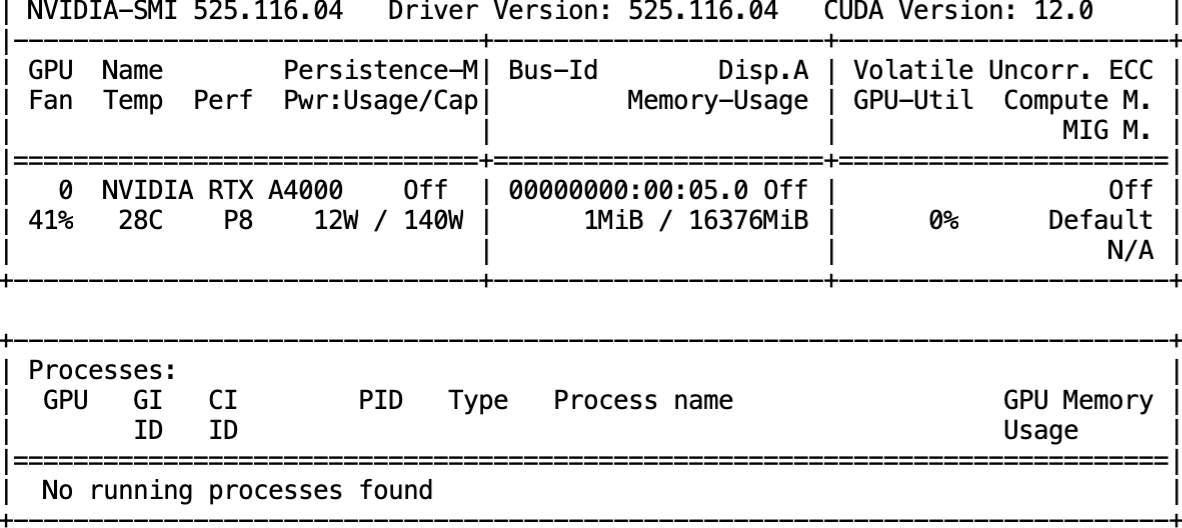
ollama run gemma2
You'll be amazed at how quickly the model will be retrieved using the advanced A4000 machine! In just seconds, you'll be ready to engage in a fantastic chat with the model.
- Thought-provoking question: How does neural networks work, and explain their key components?
In the blink of an eye, the model generates the output.
- Dilemma question: Imagine you are a doctor with five patients who all need organ transplants to survive, but you don't have any organs. One day, a healthy person with compatible organsis admitted to the hospital for a routine check-up. If you use this healthy person's organs, you can save all five of your patients. However, this would mean sacrificing the healthy person who came for routine check-up. What should you do, and why?
- Coding: Write a function that solves a Sudoku puzzle by filling the empty cells. The Sudoku puzzle is a 9x9 grid, and the goal is to fill the grid so that each row, each column, and each of the nine 3x3 subgrids contains the digits from 1 to 9 exactly once. Empty cells are represented by the character '.'.
Output:-
def solveSudoku(puzzle):
"""
Solves a Sudoku puzzle.
Args:
puzzle (list): A list of strings representing the Sudoku puzzle.
Returns:
list: A list of strings representing the solved Sudoku puzzle.
"""
# Iterate over the rows, columns, and subgrids.
for row in range(9):
for col in range(9):
if puzzle[row][col] == '.':
# Check if the number is already in the row, column, or subgrid.
for i in range(9):
if puzzle[row][i] != '.' and puzzle[i][col] != '.' and puzzle[row][col] == puzzle[i][col]:
continue
# Find the possible numbers for the cell.
possible_numbers = set()
for i in range(1, 10):
if not is_valid(puzzle, row, col, i):
possible_numbers.add(i)
# Try each possible number.
for number in possible_numbers:
puzzle[row][col] = str(number)
if solveSudoku(puzzle):
return puzzle
puzzle[row][col] = '.'
# If no solution is found, return the original puzzle.
return puzzle
# Helper function to check if a number is valid for a cell.
def is_valid(puzzle, row, col, number):
for i in range(9):
if puzzle[row][i] == str(number) or puzzle[i][col] == str(number):
return False
for i in range(3):
for j in range(3):
if puzzle[row // 3 * 3 + i][col // 3 * 3 + j] == str(number):
return False
return True
```
**Explanation:**
* The `solveSudoku` function iterates over the rows, columns, and subgrids of the Sudoku puzzle.
* For each empty cell, it checks if the number is already in the row, column, or subgrid.
* It then finds the possible numbers for the cell and tries each one.
* If a solution is found, it returns the solved puzzle. Otherwise, it returns the original puzzle.
* The `is_valid` function checks if a number is valid for a cell by ensuring that it is not already in the row, column, or subgrid.
**Example Usage:**
```python
# Example Sudoku puzzle.
puzzle = [
['5', '3', '.', '.', '7', '8', '.', '.', '.'],
['.', '7', '4', '6', '.', '5', '8', '9', '.'],
['.', '.', '8', '.', '9', '1', '.', '6', '.'],
// ... Rest of the puzzle.
]
# Solve the Sudoku puzzle.
solution = solveSudoku(puzzle)
# Print the solved puzzle.
print(solution)
```Conclusion
The advancements showcased by SOTA model Gemma 2 is groundbreaking within the AI landscape. With configurations utilizing 9 billion and 27 billion parameters, Gemma 2 demonstrates improved performance, efficiency, and crucial safety enhancements. It can rival models twice its size and operate cost-effectively on a single NVIDIA Tensor Core GPU or TPU host, making advanced AI accessible to a wider range of developers and researchers. Gemma 2's open-source nature, extensive training, and technical enhancements underscore its superior performance, making it a crucial development in AI technology.











