Introduction
The GPU memory hierarchy is increasingly becoming an area of interest for deep learning researchers and practitioners alike. By building an intuition around memory hierarchy, developers can minimize memory access latency, maximize memory bandwidth, and reduce power consumption leading to shorter processing times, accelerated data transfer, and cost-effective compute usage. A thorough understanding of memory architecture will enable developers to achieve peak GPU capabilities at scale.
CUDA Refresher
CUDA (Compute Unified Device Architecture) is a parallel computing platform developed by NVIDIA for configuring GPUs.
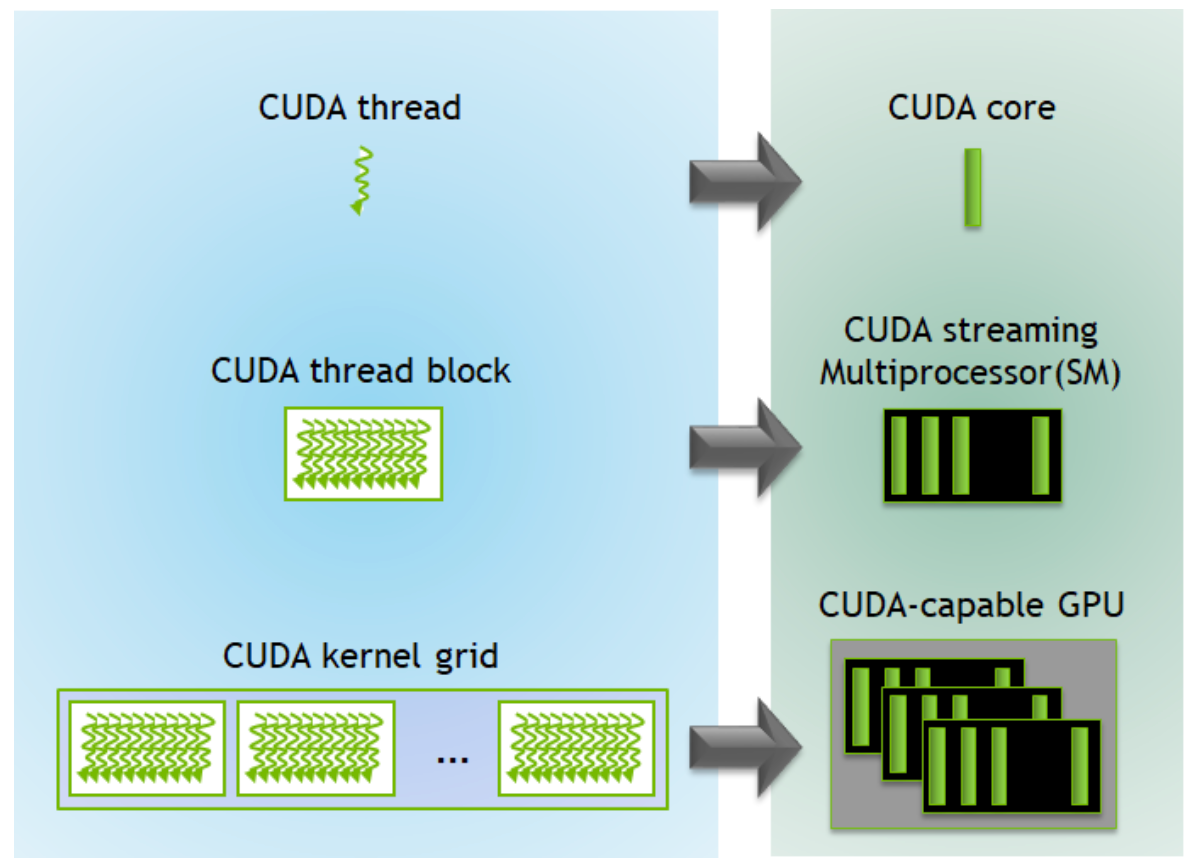
The execution of a CUDA program begins when the host code (CPU serial code) calls a kernel function. This function call launches a grid of threads on a device (GPU) to process different data components in parallel.
A thread is comprised of the program's code, the current execution point in the code, as well as the values of its variables and data structures. A group of threads form a thread block and a group of thread blocks compose the CUDA kernel grid. The software components, threads and thread blocks, correspond directly to their hardware analogs, the CUDA core and the CUDA Streaming Multiprocessor (SM).
All together, these make up the constituent parts of the GPU.
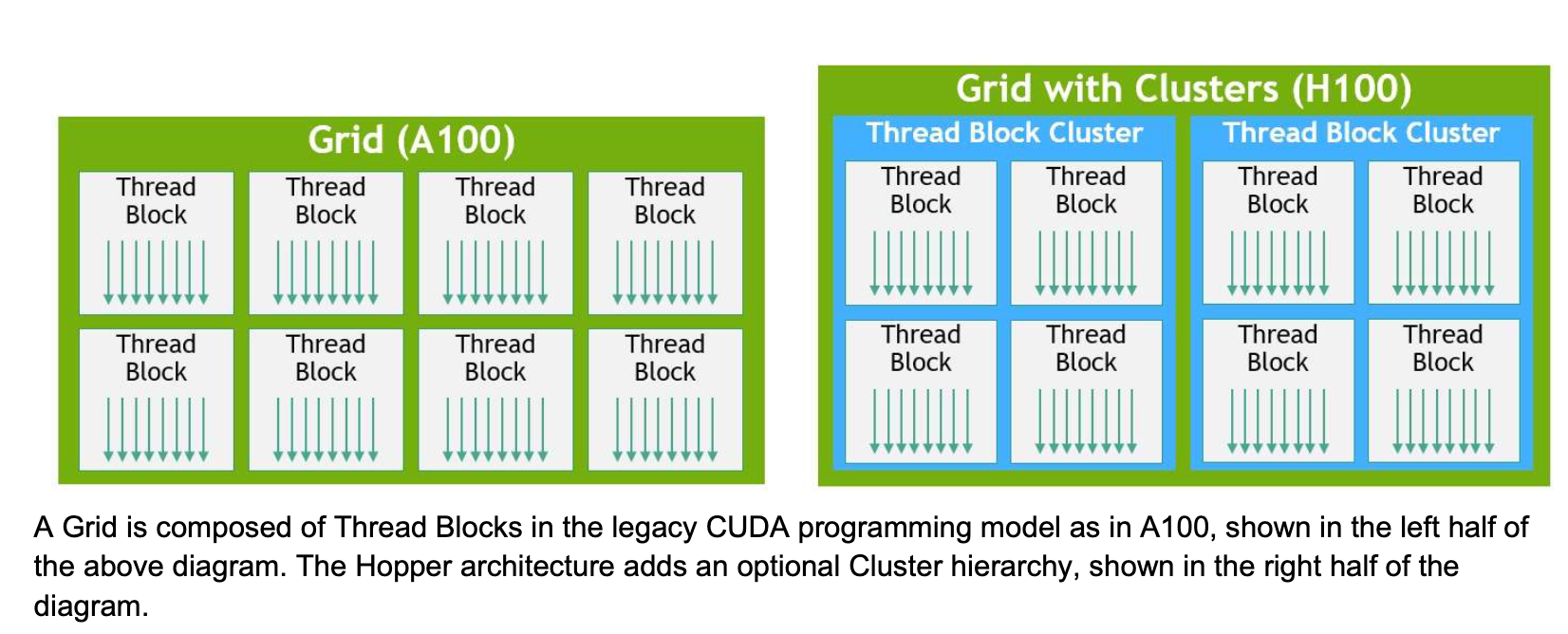
H100s introduce a new Thread Block Cluster architecture, extending GPU's physical programming architecture to now include Threads, Thread Blocks, Thread Block Clusters, and Grids.
CUDA Memory Types
There are varying degrees of accessibility and duration for memory storage types utilized by a CUDA device. When a CUDA programmer assigns a variable to a specific CUDA memory type, they dictate how the variable is accessed, the speed at which it's accessed, and the extent of its visibility.
Here's a quick overview of the different memory types:
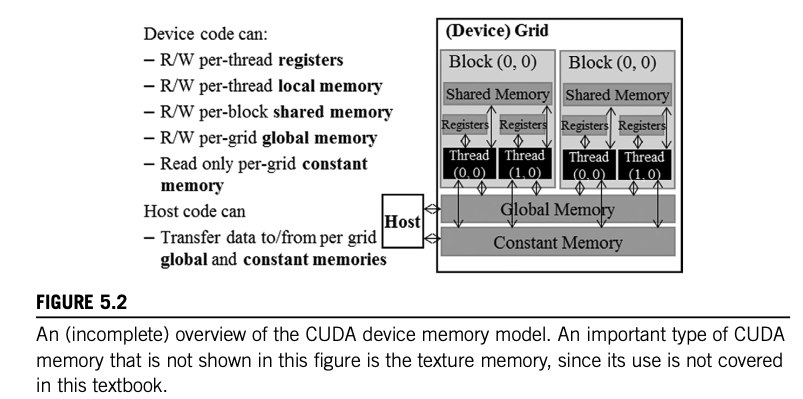
Register memory is private to each thread. This means that when that particular thread ends, the data for that register is lost.
Local memory is also private to each thread, but it's slower than register memory.
Shared memory is accessible to all threads in the same block and lasts for the block's lifetime.
Global memory holds data that lasts for the duration of the grid/host. All threads and the host have access to global memory.
Constant memory is read-only and designed for data that does not change for the duration of the kernel's execution.
Texture memory is another read-only memory type ideal for physically adjacent data access. Its use can mitigate memory traffic and increase performance compared to global memory.
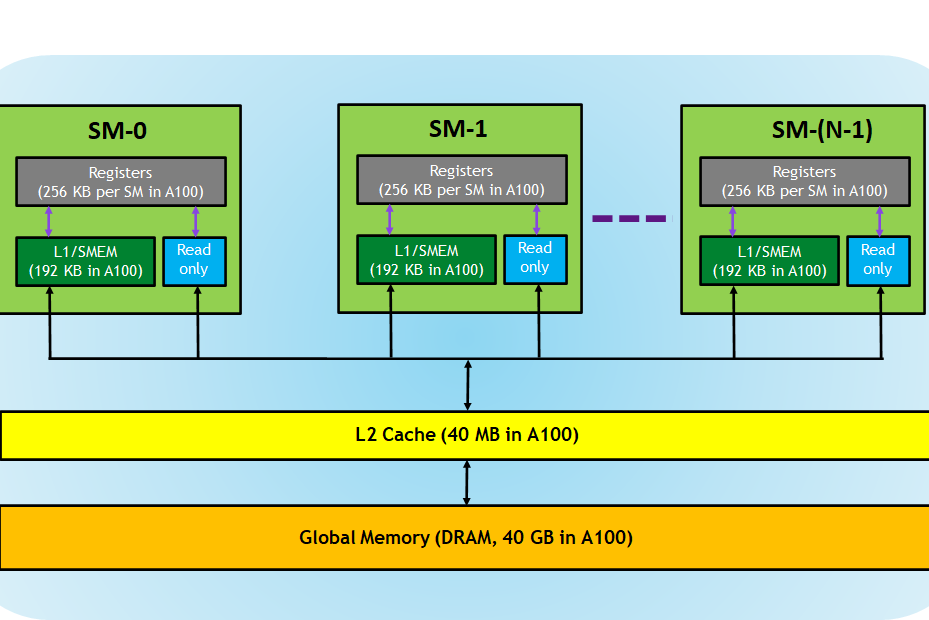
GPU Memory Hierarchy
The Speed-Capacity Tradeoff
It is important to understand that with respect to memory access efficiency, there is a tradeoff between bandwidth and memory capacity. Higher speed is correlated with lower capacity.
Registers
Registers are the fastest memory components on a GPU, comprising the register file that supplies data directly into the CUDA cores. A kernel function uses registers to store variables private to the thread and accessed frequently.
Both registers and shared memory are on-chip memories where variables residing in these memories can be accessed at very high speeds in a parallel manner.
By leveraging registers effectively, data reuse can be maximized and performance can be optimized.
Cache Levels
Multiple levels of caches exist in modern processors. The distance to the processor is reflected in the way these caches are numbered.
L1 Cache
L1 or level 1 cache is attached to the processor core directly. It functions as a backup storage area when the amount of active data exceeds the capacity of a SM's register file.
L2 Cache
L2 or level 2 cache is larger and often shared across SMs. Unlike the L1 cache(s), there is only one L2 cache.
Constant Cache
Constant cache captures frequently used variables for each kernel leading to improved performance.
When designing memory systems for massively parallel processors, there will be constant memory variables. Rewriting these variables would be redundant and pointless. Thus, a specialized memory system like the constant cache eliminates the need for computationally costly hardware logic.
New Memory Features with H100s

Hopper, through its H100 line of GPUs, introduced new features to augment its performance compared to previous NVIDIA micro-architectures.
Thread Block Clusters
As mentioned earlier in the article, Thread Block Clusters debuted with H100s, expanding the CUDA programming hierarchy. A Thread Block Cluster allows for greater programmatic control for a larger group of threads than permissible by a Thread Block on a single SM.
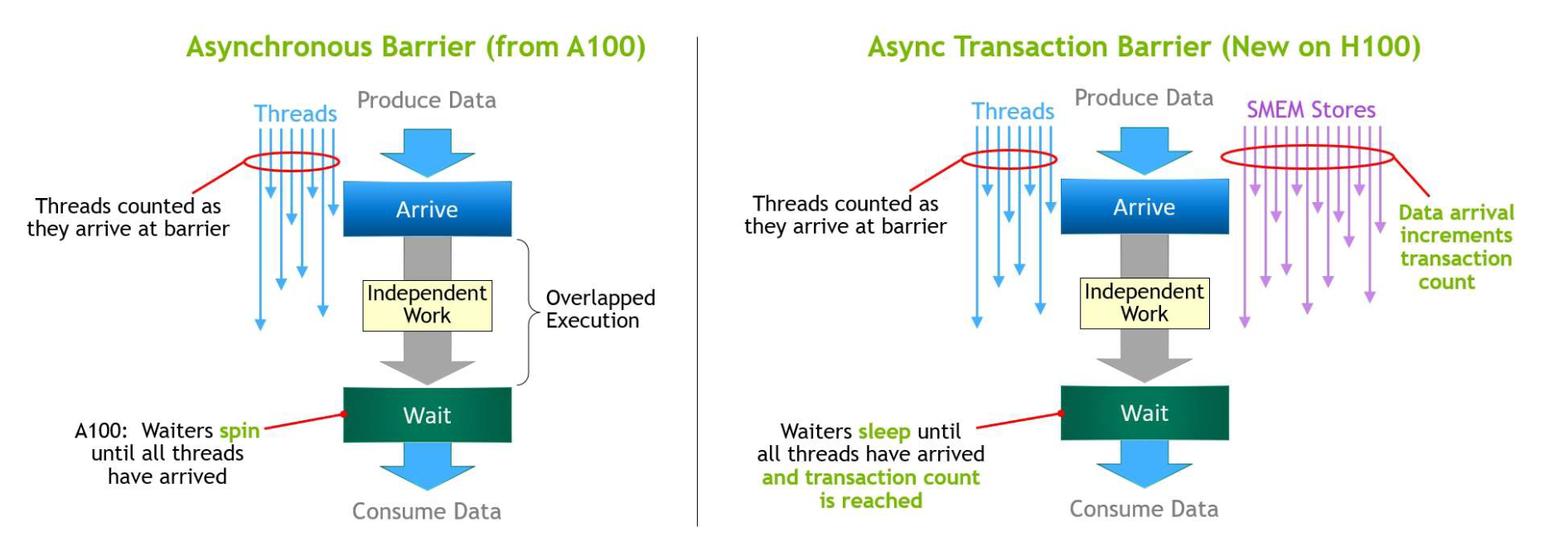
Asynchronous Execution
The latest advancements in asynchronous execution introduce a Tensor Memory Accelerator (TMA) and an Asynchronous Transaction Barrier into the Hopper architecture.
The Tensor Memory Accelerator (TMA) unit allows for the efficient data transfer of large blocks between global and shared memory.
The Asynchronous Transaction Barrier allows for synchronization of CUDA threads and on-chip accelerators, regardless of whether they are physically located on separate SMs.
Conclusion
Assigning variables to specific CUDA memory types allows a programmer to exercise precise control over its behaviour. This designation not only determines how the variable is accessed, but also the speed at which this access occurs. Variables stored in memory types with faster access times, such as registers or shared memory, can be quickly retrieved, accelerating computation. In contrast, variables in slower memory types, such as global memory, are accessed at a slower rate. Additionally, memory type assignment influences scope of the variable's usage and interaction with other threads. The assigned memory type governs whether the variable is accessible to a single thread, a block of threads or all threads within a grid. Finally, H100s, the current SOTA GPU for AI workflows, introduced several new features that influence memory access such as Thread Block Clusters, the Tensor Memory Accelerator (TMA) unit, and Asynchronous Transaction Barriers.
References
Programming Massively Parallel Processors (4th edition)


 Pradeep Gupta
Pradeep Gupta