

In recent years, real-world anime super-resolution (SR) has gained significant popularity. However, many current methodologies rely heavily on techniques developed for photorealistic images.
These techniques may not be the best fit for anime content because anime has distinct characteristics, such as hand-drawn lines, vibrant colors, and unique stylistic elements. As a result, these photorealistic-based methods may not fully leverage or accommodate the specific attributes and nuances of anime production, potentially leading to suboptimal results when applied to anime images.
This paper takes a novel approach by examining the specific workflow of anime production and leveraging its distinctive characteristics to enhance real-world anime SR.
I'm thrilled to share that in this article, we'll harness the impressive A100 GPU from Paperspace to determine the model's ability to enhance distorted, vintage anime images.
Super-resolution allows older, lower-resolution anime to be upscaled to meet modern display standards without losing visual fidelity, thus preserving the viewing experience across different screen sizes and resolutions. Anime content is consumed on various devices, from large-screen televisions to smartphones and tablets. Super-resolution will ensure that the content looks good on all types of screens by upscaling and restoring the image to its appropriate resolution, enhancing the versatility and reach of anime productions. We can now leverage AI to create more creative and visually stunning anime images without the hassle of re-creating them manually.
Methodology
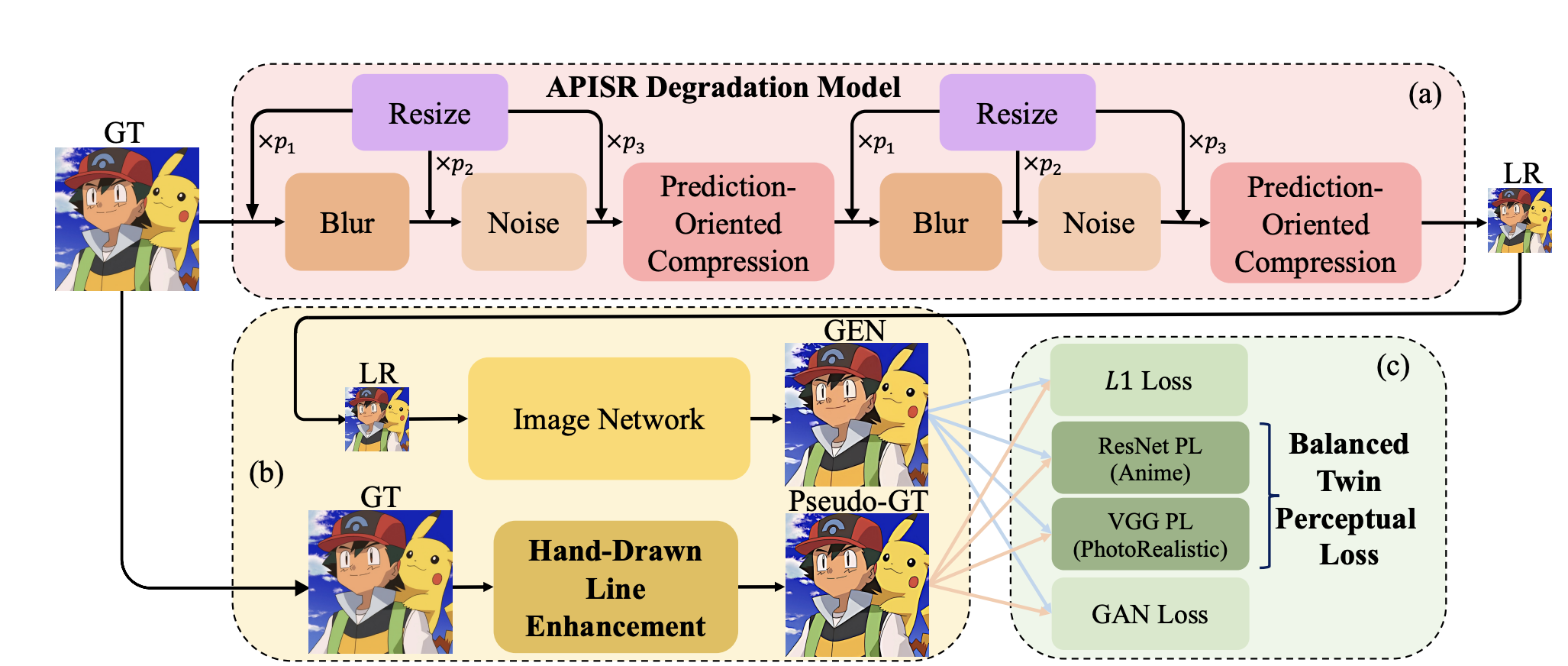
The paper proposes enhancements to restore distorted hand-drawn lines and handle various compression artifacts, enhancing the model's representation.
Prediction-Oriented Compression
Traditional image SR methods rely on JPEG compression, compressing each unit without considering others. Video compression, however, uses prediction algorithms to reference similar pixel content and compress only the differences, reducing information entropy. This can lead to artifacts due to misalignment in residuals. This prediction-oriented compression module within the image degradation model compresses each frame individually using intra-prediction, allowing the image degradation model to synthesize compression artifacts similar to multi-frame video compression, enabling the SR network to learn and restore these artifacts effectively.
Shuffled Resize Module
While real-world artifacts like blurring, noise, and compression can be mathematically modeled, resizing is unique to SR datasets and not part of natural image generation. Traditional fixed resize modules are thus not ideal. This paper approaches the issue by randomly placing resize operations in various orders within the degradation model. This approach better simulates real-world conditions and improves the effectiveness of the SR process.
Anime Hand-Drawn Lines Enhancement
Bring this project to life
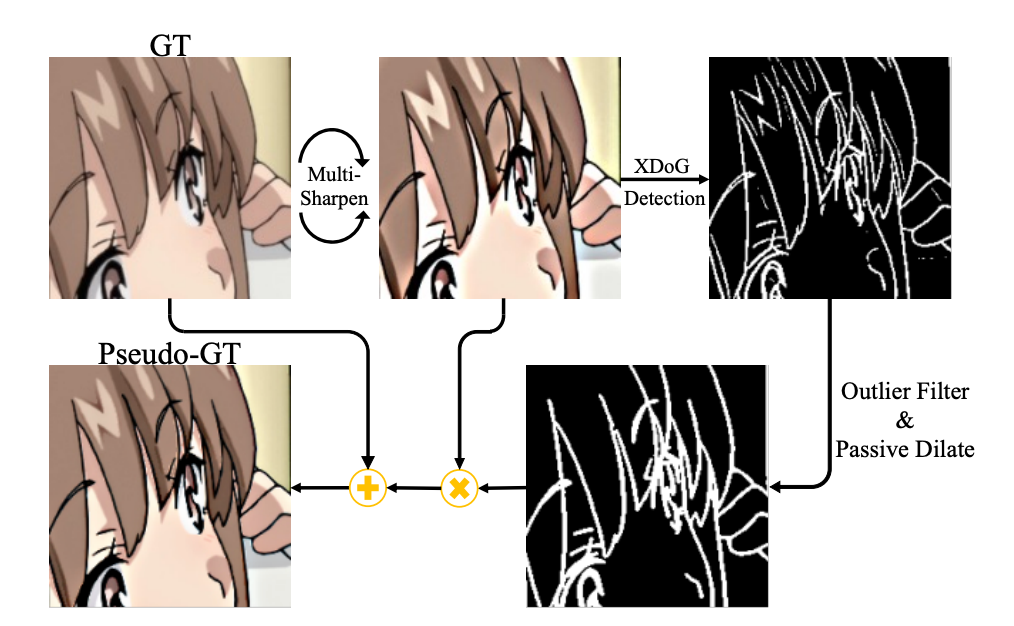
Enhancing faint hand-drawn lines requires a targeted approach rather than global methods like modifying the degradation model or sharpening the entire ground truth (GT). These global methods fail to focus on hand-drawn lines. Instead, sharpened hand-drawn line information is extracted and merged with the GT to create a pseudo-GT. This allows the network to generate sharpened lines during SR training without adding extra neural network modules or separate post-processing steps.
Also, instead of using a sketch extraction model, which isn't ideal because it often distorts hand-drawn details and includes unrelated content like shadows and CGI edges. XDoG, a pixel-by-pixel Gaussian-based method, is used to extract edge maps from the sharpened GT. However, XDoG edge maps can be noisy with outlier pixels and fragmented lines. An outlier filtering and a custom passive dilation method are used to fix this, producing a more explicit representation of hand-drawn lines.
Balanced Twin Perceptual Loss
Balanced Twin Perceptual Loss is a technique designed to improve the quality of super-resolution (SR) images, particularly in the context of anime, by addressing the unique challenges associated with anime content. This method balances the strengths of two different perceptual loss functions to create high-quality SR images without unwanted color artifacts.:
- Anime-Specific Loss: Utilizes a ResNet50 model trained on the Danbooru anime dataset to enhance features unique to anime, like hand-drawn lines and colors.
- Photorealistic Loss: A VGG model trained on ImageNet maintains general image quality and structure.
By balancing these two losses, the SR model reduces unwanted color artifacts and improves visual quality, making it well-suited for enhancing anime content.
Comparison with the SOTA model
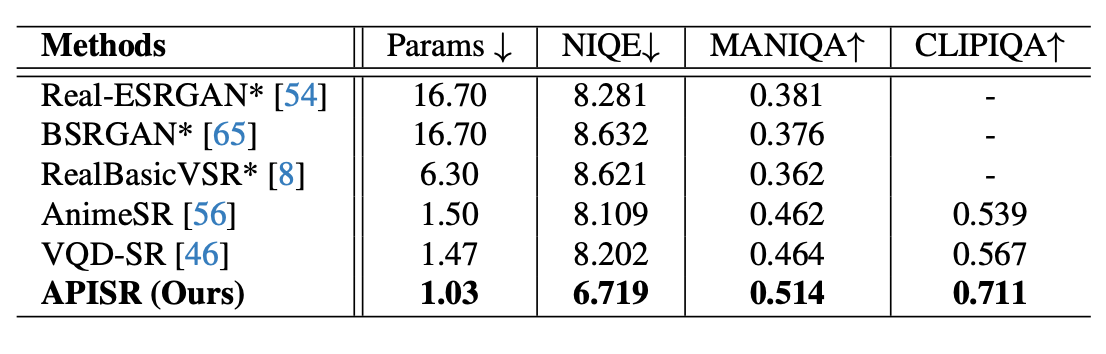
The study compared the APISR model both quantitatively and qualitatively with other state-of-the-art (SOTA) real-world image and video super-resolution (SR) methods, including Real-ESRGAN, BSRGAN, RealBasicVSR, AnimeSR, and VQD-SR.
Quantitative Comparison
Following the standards set by previous SR research, this model was tested on low-quality datasets to generate high-quality images and evaluated using no-reference metrics, with a scaling factor of 4. The evaluation utilized the AVC-RealLQ dataset, the only known dataset designed explicitly for real-world anime SR testing, consisting of 46 video clips, each with 100 frames.
APISR model, with just 1.03M parameters, achieved SOTA performance across all metrics while being the smallest in network size. The model's efficiency is primarily due to the prediction-oriented compression model, which allows video compression degradations to be restored using image datasets and networks. Additionally, the explicit degradation model eliminates the need for degradation model training.
Qualitative Comparison
Visually, APISR significantly enhances image quality compared to other methods. The model excels in restoring heavily compressed images with fewer artifacts and clearer, denser hand-drawn lines. It also outperforms other models in correcting twisted lines and shadow artifacts because of an improved image degradation model. The balanced twin perceptual loss ensures that the restored images avoid the unwanted color artifacts in AnimeSR and VQD-SR.

Through extensive experiments on public benchmarks, this method demonstrates superior performance compared to existing state-of-the-art approaches trained on anime datasets. This research advances the field of anime SR and provides a framework that utilizes the intrinsic characteristics of anime production for better image enhancement.
Paperspace Demo
Bring this project to life
We will use the mighty A100 available on the Paperspace platform. The NVIDIA A100 Tensor Core GPU, powered by the NVIDIA Ampere Architecture, offers unparalleled acceleration for AI, data analytics, and high-performance computing (HPC). The A100 80GB GPU features the world's fastest memory bandwidth, exceeding two terabytes per second (TB/s), enabling it to handle the most significant models and datasets with ease.
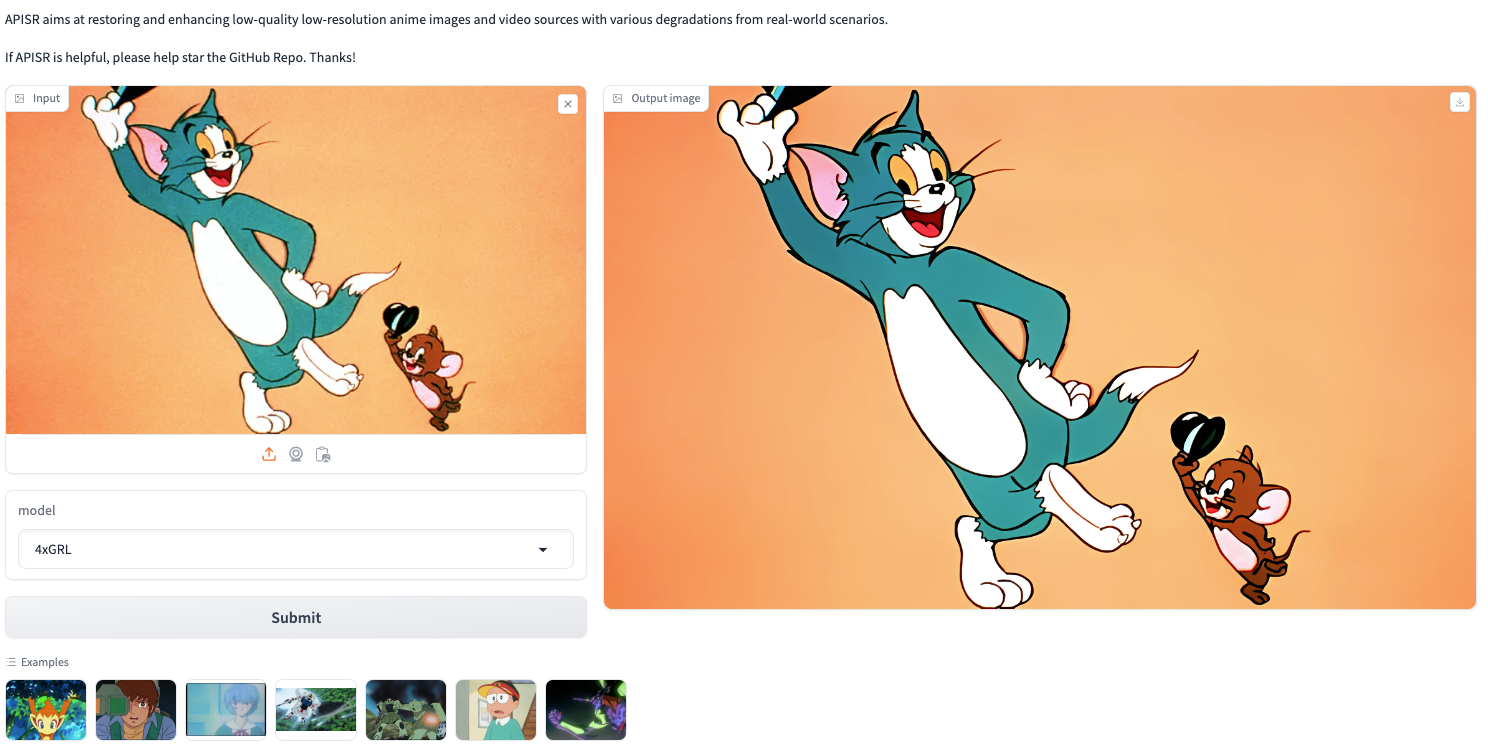
Once the machine is started, we will copy and paste the following lines of code into the notebook and then click "run."
This will generate the Gradio web app link.
%cd /notebook
!git clone -b dev https://github.com/camenduru/APISR-hf
%cd /notebook/APISR-hf
!pip install -q gradio fairscale omegaconf timm
!apt -y install -qq aria2
!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/camenduru/APISR/resolve/main/2x_APISR_RRDB_GAN_generator.pth -d /content/APISR-hf/pretrained -o 2x_APISR_RRDB_GAN_generator.pth
!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/camenduru/APISR/resolve/main/4x_APISR_GRL_GAN_generator.pth -d /content/APISR-hf/pretrained -o 4x_APISR_GRL_GAN_generator.pth
!python app.pyYou can experiment with various anime images and enhance their quality using the APISR. It's a great way to see your favorite characters in stunning detail!


Conclusion
APISR represents a significant advancement in the field of anime SR, offering a robust and efficient solution that improves the quality of anime content while preserving its unique artistic characteristics. The experiments performed prove the model is superior to the existing model.
Be sure to check out the demo with A100 GPUs and give the model a try!!











