
The last year has evidently been incredible for the world of AI development, and the propagation of deep learning technologies. This is all largely in thanks to the hardware created by Nvidia to serve these needs. The previous generation of GPU microarchitectures, Ampere, remains an incredibly powerful and in demand tool for training and inferencing AI models.
Each successive version of these Nvidia architectures has come with significantly improved bandwidth, typically greater VRAM capacity, and correspondingly larger number of CUDA cores compared to previous versions. In the last year, the new Hopper design has rightfully overtaken its predecessor thanks to its awesome power. One of the only real ways a consumer can access it is through the cloud. The powerful Ampere GPUs, especially the A100, have been essential for bringing about the AI revolution over the past two years. With the advent of the new Hopper gen, we can expect this development speed to rise even higher and fasterthan before.
With a wide selection of high-performance GPU machines and a user-friendly platform, Paperspace now provides easy access to Nvidia H100 GPUs . These machines offer some of the highest performance computing for AI applications. This article will explore Ampere and Hopper architectures and cover the differences specifically between A100 and H100 GPUs that matter to ML engineers working on the cloud. We want to present a coherent argument for when to use each sort of GPU for your AI purposes.
About Nvidia Ampere
The release of Ampere GPUs marked a significant leap forward in performance and power efficiency. One of the key improvements was the introduction of second-generation RTX technologies, which revolutionized real-time ray tracing in gaming, graphic design, and all sorts of rendering. The Ampere GPUs also made significant strides in AI processing, thanks to the advancement of the new third generation Tensor cores that accelerate AI workloads. Furthermore, the Ampere architecture's increased memory bandwidth and improved power efficiency have made it a favorite among both developers and enthusiasts.
To read more about Ampere GPUs, check out our comparison of the full lineup of Paperspace GPUs with benchmarking here on the Paperspace Blog.
For years, the Ampere A100 was the best GPU available for AI tasks. This all changed with the release of the H100 and the H200 after it. Let's look at the Hopper release in more detail.
About NVIDIA Hopper
- The NVIDIA Hopper architecture uses fourth-generation Tensor Core technology with the Transformer Engine to speed up AI calculations. The Hopper Tensor Cores can utilize mixed FP8 and FP16 precisions while performing computations to further accelerate processes thanks to this library. As a result, Hopper GPUs, as reported by Nvidia, triple the possible floating-point operations per second (FLOPS) for TF32, FP64, FP16, and INT8 precision over the prior generation.
- The NVIDIA H100 GPU is partitioned into smaller, isolated instances called Multi-Instance GPU (MIG) instances. The Hopper release contains the second generation of MIG partitioning technology. This represents a noted improvement over the technology in the A100. The new version provides "approximately 3x more computing capacity and nearly 2x more memory bandwidth per GPU instance" (Source).
- Confidential Computing is a new technology that seeks to solve the issue of privacy and data control when working on the cloud. Data being processed, until now, has inherently been unable to be encrypted without potentially affecting the quality. With Confidential Computing, users can securely collaborate with different parties on the cloud. Encrypted transfers occur between CPU and GPU, as shown in the diagram below.
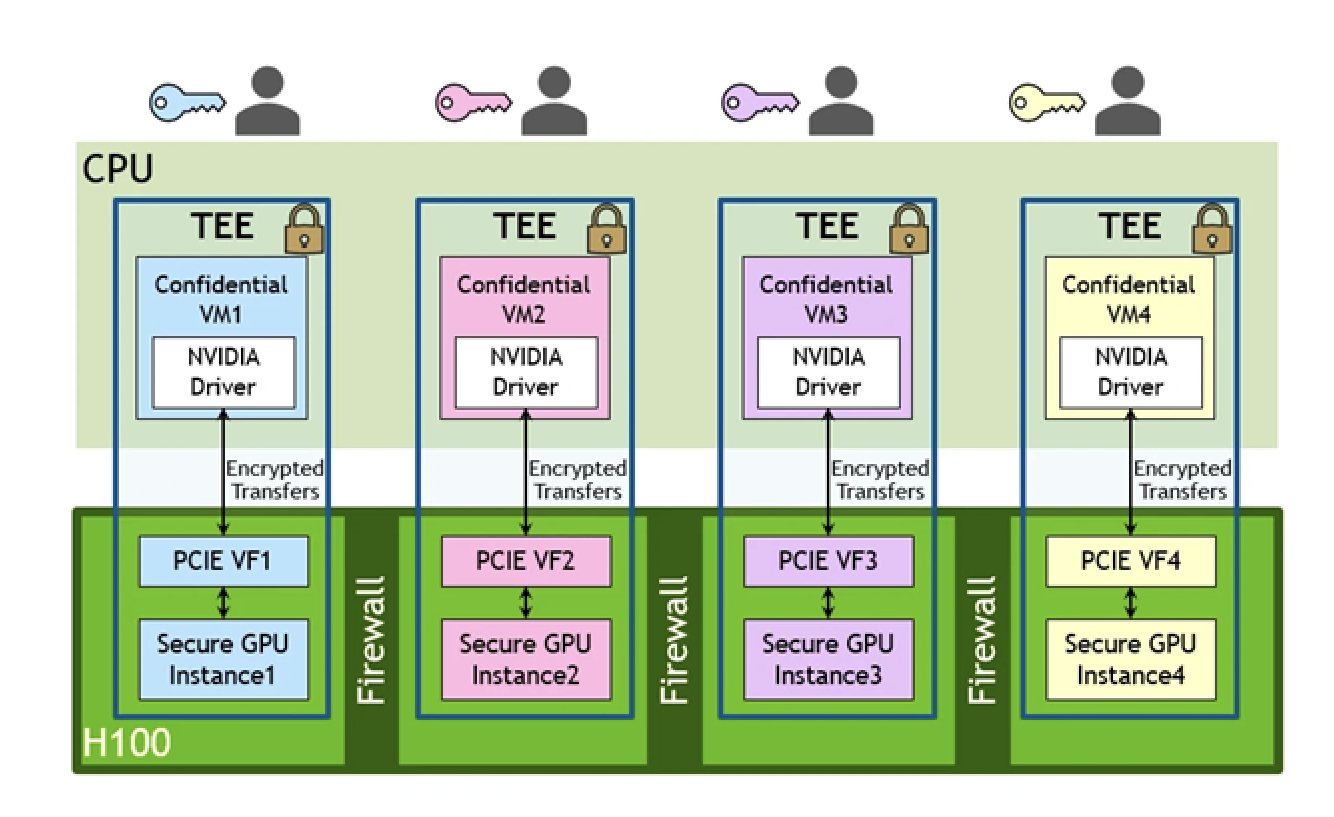
Quick facts about the Hopper and Ampere Microarchitectures
Ampere Microarchitecture
- Launch Year: Introduced in 2020
- Target Use: Designed for various applications, including data centres, AI, gaming, and professional visualization
- Precision Formats: Supports INT4, INT8, FP16, FP32, and a variety of mixed precision formats
- Asynchronous Execution: Offers standard asynchronous execution capabilities, allowing for efficient multitasking within the GPU
- Tensor Core Technology: Second generation Tensor Cores significantly enhance AI and deep learning capabilities over Turing GPUs
- Key Innovations: Notable for improved ray tracing capabilities, enhancing realism in graphics rendering
- Key Example: A100 GPU, which is widely used in AI research and data centres for its powerful computing capabilities
Hopper MicroArchitecture
- Launch Year: Launched in 2022, marking the next evolution in NVIDIA's GPU technology
- Target Use: Primarily designed for data centre applications, focusing on high-performance computing tasks
- Precision Formats: Supports all formats as Ampere, but offering enhanced configuration for various computational needs, especially in AI and machine learning
- Asynchronous Execution: Features improved asynchronous execution and memory overlap, optimizing the GPU's ability to handle multiple tasks simultaneously
- Tensor Core Technology: Advances Tensor Core technology with the introduction of the Transformer Engine, specifically designed to accelerate AI workloads, such as those involving natural language processing
- Key Innovations: Includes enhanced AI and graphics performance, improved MIG (Multi-Instance GPU) capabilities for better resource allocation, and the Transformer Engine for AI, which optimizes processing for AI models
- Example: H100 GPU, which is tailored for the most demanding AI and high-performance computing workloads in data centers
Some other notable innovations that came with the release of Hopper GPUs to note:
- It allows multiple GPU chips to be integrated into a single package
- It significantly reduces latency and increases performance by improving memory bandwidth
- It enables real-time ray tracing for more realistic graphics rendering. Faster rendering, improved ray tracing capabilities, enhanced artificial intelligence (AI) processing, expanded memory capacity, and support for the latest industry standards can be expected
Now that we have looked at the Ampere and Hopper Microarchitectures, let's dig a bit deeper, and examine the A100 and H100 GPUs available on Paperspace.
What is an A100 GPU?
The NVIDIA A100 Tensor Core GPU is a high-performance graphics processing unit designed primarily for high-performance computing (HPC), AI, data centres, and data analytics. It was the previous generations most powerful Data Center GPU. This GPU can be partitioned into as many as seven GPU instances using the first generation of MIG technology, comes equipped with second generation Tensor Cores, and boasts a lofty 80 GB of VRAM. All components in the A100 are fully isolated at the hardware level.
All together, it is a potent machine for training Deep Learning models. Check out the Differences between the A100 and H100 GPU at a glance section below for technical details.
What is an H100 GPU?
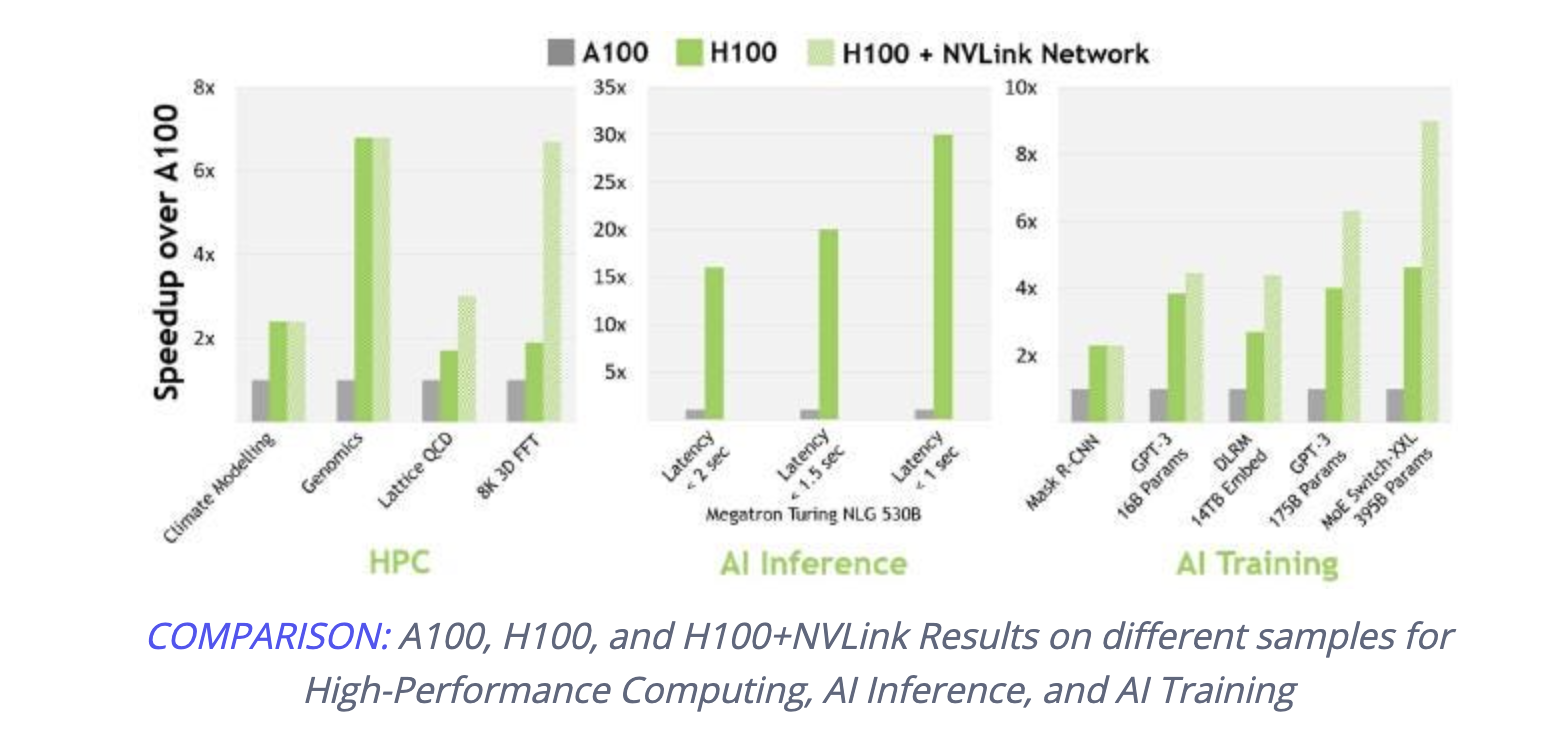
The Nvidia H100 is the new engine of the world's AI infrastructure that enterprises use to accelerate their AI-driven businesses. The first product based on Hopper is the H100, which contains 80 billion transistors and delivers three to six times more performance than the Ampere-based A100. It also supports an ultra-high bandwidth of over 2TB/, speeds up networks 6x the previous version, and has extremely low latency between two H100 connections. The H100 also features an incredible 16896 CUDA Cores, enabling it to perform matrix calculations far faster than an A100 GPU.
“Twenty H100 GPUs can sustain the equivalent of the entire world's internet traffic, making it possible for customers to deliver advanced recommender systems and large language models running inference on data in real-time”, Nvidia claimed at Nvidia GTC 2022
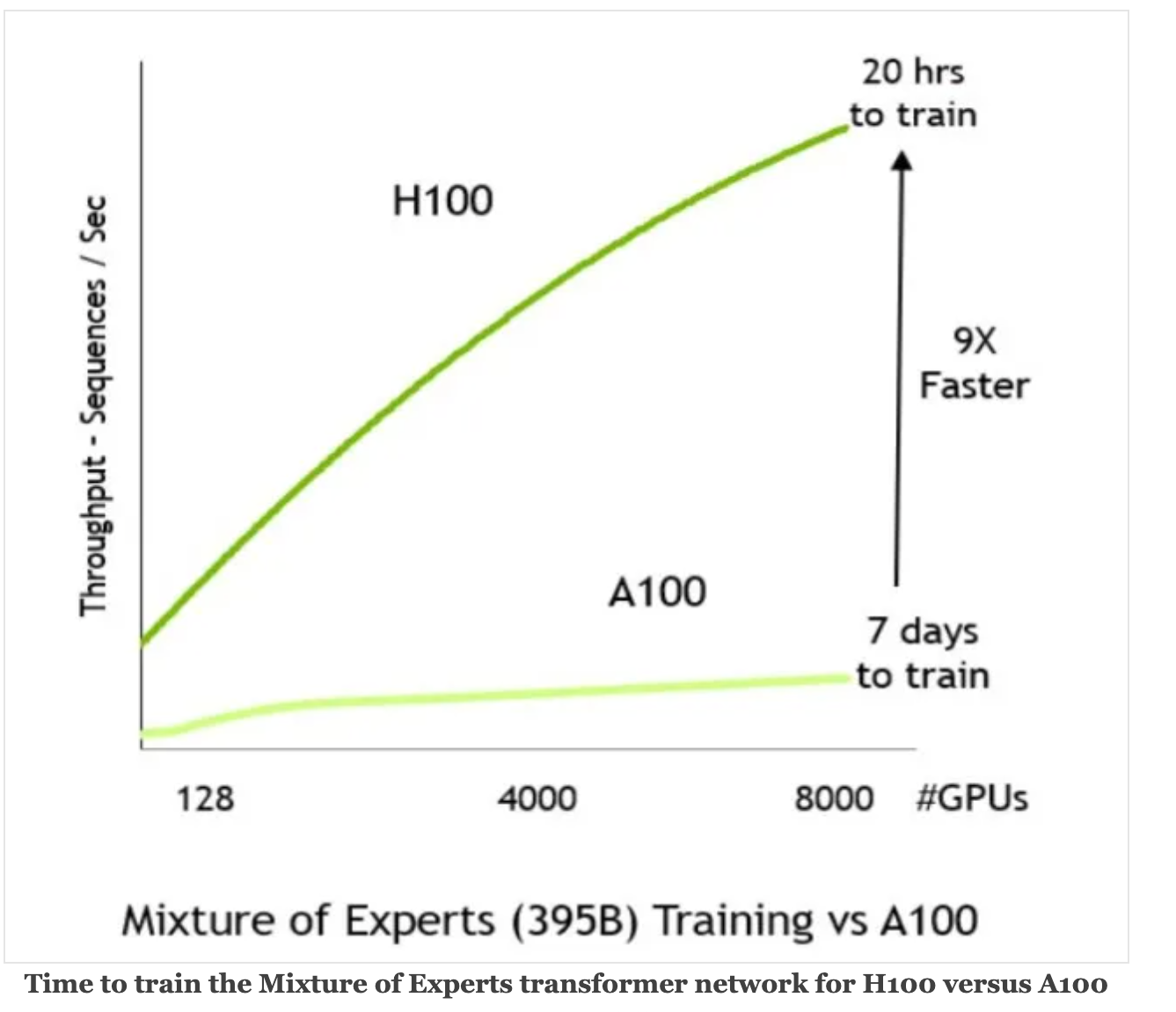
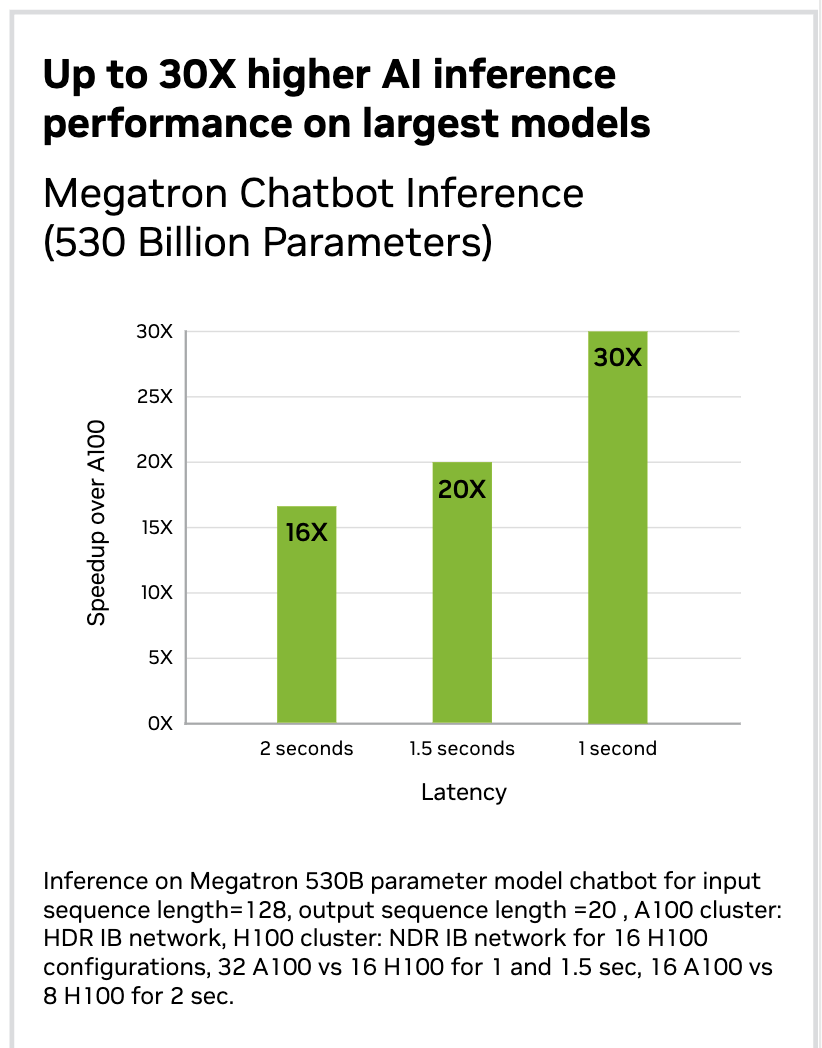
According to NVIDIA, H100 is about 3.5 times faster for 16-bit inference, and for 16-bit training, H100 is about 2.3 times faster. The below picture shows the performance comparison of the A100 and H100 GPU. In the example, a mixture of experts model was trained on both the GPUs. A100 took 7 days to train it, and H100 took 20 hours to train it. For Megatron-530B, with 530 billion parameters, H100 outperforms A100 by as much as 30x.
Differences between the A100 and H100 GPUs on Paperspace
Now that we have introduced each of the machines, let's put them in the context of Paperspace. Selecting the right machine for a task is important, and can lead to costly problems if done incorrectly. The A100 on Paperspace is currently available for $3.19 per hour, and the H100 is available for $5.95 per hour. While the H100 is certainly more powerful, this is only with regards to certain things like speed. Thus, in certain circumstances, it actually may make more sense cost wise to use an A100.
A100 GPU
- Memory: Available with either 40 GB or 80 GB of high-bandwidth memory (HBM2), providing substantial capacity for data-intensive tasks (the same as an H100)
- Performance: Primarily designed for high-performance computing (HPC) and artificial intelligence (AI) workloads, but is now one generation behind
- DPX Instructions: This does not support DPX instructions, which are used for data processing acceleration in AI applications.
- NVLink: Third generation NVLink allows for 600 gigabytes per second (GB/sec) connection between 16 A100 GPUs
- Confidential Computing: Does not support confidential computing
- Energy Efficiency: Generally runs at 400 Watts
- Multi-Instance GPU (MIG): Offers first-generation MIG support, enhancing data communication between GPUs and CPUs and allowing for the partitioning of the GPU into smaller instances for different tasks.
H100 GPU
- Memory: Comes with 80 GB of HBM2 memory, providing ample space for even the most memory-intensive applications
- Performance: the latest generation of GPU, the H100 boasts the highest bandwidth available
- DPX Instructions: Supports DPX instructions, enhancing its capability to accelerate data processing tasks, beneficial for AI and machine learning applications
- NVLink: Features 4th-Generation NVIDIA NVLink, which can connect up to 256 H100 GPUs at 9x higher bandwidth than previous generations, significantly improving data transfer speeds between GPUs
- Confidential Computing: It supports confidential computing, ensuring secure data processing environments
- Energy Efficiency: More energy-efficient due to advancements in power consumption management and faster clock speeds, but still consumes more power at 500 Watts peak power consumption
- Multi-Instance GPU (MIG): Supports 2nd-generation Secure Multi-Instance GPU technology, with MIG capabilities extended by 7x compared to the previous version, allowing for more efficient resource utilization and isolation
H100 in the News
We have seen the H100 proliferate in the AI market over the last year. Here are some useful and relevant reports about the H100's success with AI training from Nvidia.
- When training the Mixture of Experts Transformer model with 395 billion parameters on 8,000 GPUs, Nvidia said rather than taking seven days using A100s, training on H100s takes only 20 hours.-NVIDIA
- H100 is the first GPU to support PCIe Gen5 and the first to utilise HBM3, enabling 3TB/s of memory bandwidth.-NVIDIA
- The company will bundle eight H100 GPUs together for its DGX H100 system that will deliver 32 petaflops on FP8 workloads, and the new DGX.-NVIDIA
- Superpod will link up to 32 DGX H100 nodes with a switch using fourth-generation NVLink capable of 900GBps.-Lambda Labs
- Nvidia said the H100 could handle the 105-layer, 530 billion parameter monster model, the Megatron-Turing 530B, with up to 30 times higher throughput.-NVIDIA
Can the A100 and H100 be used interchangeably?
The answer is generally NO. The A100 and H100 GPUs cannot be used interchangeably. They have different form factors and are designed for different use cases. Notably, the H100 has significantly higher bandwidth and CUDA core counts, which enable the H100 to handle much larger data workloads. The A100 has the equivalent maximum VRAM, but the H100's much larger bandwidth means it can handle the computations with that data much more quickly. As such, the H100 is far faster at both training and AI inference.
The A100 is significantly cheaper, so we recommend it for inference with Paperspace Notebooks or creating an accessible API endpoint for your AI application with Paperspace Deployments. The H100 is an ideal tool for training new AI technologies. We recommend the 8x Multi-GPU Paperspace Machine for these tasks going forward. Use the video below to see how to run the H1o0 on Paperspace.
How to run H100 GPUs on Paperspace
Closing Thoughts
The evolution between NVIDIA Ampere and Hopper architectures marks an exciting time for GPU enthusiasts. Both architectures offer significant capabilities in performance, efficiency, and cutting-edge technologies, but it is immediately evident that Hopper is a significant step forward. That being said, the choice between Ampere and Hopper GPUs on the cloud ultimately depends on individual computing needs and budget constraints. While Ampere GPUs deliver outstanding performance, the Hopper architecture promises to keep pushing the boundaries even further. Whether we are content creators, gamers, or researchers, NVIDIA GPUs continue to offer unparalleled capabilities and are worth considering for the next computing upgrade.
Related Sources
- H100 Transformer Engine Supercharges AI Training
- NVIDIA H100 Tensor Core GPU - Deep Learning Performance Analysis
- NVIDIA H100 Tensor Core GPU
,











