
Bring this project to life
Introduction
Language model pretraining has been proven effective in enhancing several natural language processing tasks. Natural language inference and paraphrasing are examples of sentence-level tasks, whereas token-level tasks like named entity identification and question answering need models to provide fine-grained output on the token level. Feature-based and fine-tuning are two methods for applying pre-trained language representations to downstream tasks.
Fine-tuning approaches like the Generative Pre-trained Transformer introduce minimal task-specific parameters and are trained on the downstream tasks by simply fine-tuning all pre-trained parameters. Both techniques employ unidirectional language models during pretraining to learn general language representations.
The way toward BERT
We contend that current strategies limit the potency of previously trained representations for the fine-tuning methods. Standard language models are unidirectional, which restricts the architectures that can be utilized in pretraining, a significant restriction. With the left-to-right design used in OpenAI GPT, each token can only attend to tokens that came before it in the self-attention layers of the Transformer.
These limitations are not ideal for tasks at the sentence level, and they might be particularly damaging when used for token-level tasks, such as answering questions, where it is critical to integrate context in both directions. This study proposes improving fine-tuning-based techniques by introducing BERT: Bidirectional Encoder Representations from Transformers.
The Cloze task-inspired "masked language model" (MLM) pretraining aim in BERT alleviates the above mentioned unidirectionality limitation. The goal of the masked language model is to estimate the original vocabulary id of a masked word only from its context after masking specific tokens from the input. A deep bidirectional Transformer can be trained using the MLM objectives rather than a traditional left-to-right language model pretraining approach. In addition to the masked language model, we also utilize a task known as "next sentence prediction" to pre-train text-pair representations.
The Contributions of the Paper
- According to this study, bidirectional pretraining is critical for developing accurate language representations. BERT employs masked language models to allow for pre-trained deep bidirectional representations. It contrasts unidirectional language models for pretraining and a shallow concatenation of independently trained left-to-right and right-to-left LMs.
- The authors demonstrate that Pre-trained representations reduce the need for numerous heavily-engineered task-specific architectures. There are multiple task-specific architectures that BERT outperforms since it is the first representation model that uses fine tuning to attain the current best performance on a wide range of sentence and token level tasks. BERT has improved 11 NLP tasks. The code and pre-trained models are available at https://github.com/google-research/bert.
History: The Most widely-used Approaches to Pre-train General Language Representation
Unsupervised Feature-based Approaches
Learning widely applicable representations of words has been a focus of research for many decades, and this field of study has included both non-neural and neural approaches. Compared to embeddings learned from scratch, pre-trained word embeddings provide considerable gains and are thus an essential component of today's natural language processing (NLP) systems. To pretrain word embedding vectors, left-to-right language modeling goals and objectives that distinguish correct from erroneous words in left and right contexts have been used.
These methods have been extended to coarser granularities, such as sentence embeddings or paragraph embedding.
Unsupervised Fine-tuning Approaches
The first method that works in this manner solely uses pre-trained word embedding parameters obtained from unlabeled text, and this method operates similarly to the feature-based techniques. Sentence or document encoders that generate contextual token representations have been pre-trained using unlabeled text and fine-tuned for a supervised downstream task.
Transfer Learning from Supervised Data
The research demonstrates successful transfer from supervised tasks using large datasets, such as natural language inference and machine translation. Research in computer vision has also proved the value of transfer learning from large pre-trained models. One strategy that has proven to be beneficial is to fine-tune models that have been pre-trained using ImageNet.
BERT
In our framework, there are two steps: the pre-training step and the fine-tuning step. The model is trained using unlabeled data across various pretraining tasks while completing a variety of pre-training tasks. Before starting the process of fine-tuning, the BERT model is initialized with the pre-trained parameters. Next, each parameter is fine-tuned using labeled data from the downstream tasks.
Even though they are all initiated with identical pre-trained parameters, the fine-tuned models for each downstream task are distinct from one another.
Model Architecture
- The model architecture of BERT is based on the original implementation and is a multi-layer bidirectional Transformer encoder.
- The paper does not provide a thorough background explanation of the model architecture since the use of Transformers is already widespread, and the implementation is almost similar to the original. Instead, the authors direct readers towards excellent guides such as “The Annotated Transformer."
- For the sake of this study, the authors will refer to the number of layers (also known as Transformer blocks) as L, the hidden size as H, and the number of self-attention heads as A.
- In the majority of their reports, they focus on the outcomes of two different model sizes: BERTBASE (L=12, H=768, A=12, Total Parameters=110M) and BERTLARGE (L=24, H=1024, A=16, Total Parameters=340M).
- To perform this comparison, BERTBASE was selected since its model size is equivalent to that of OpenAI GPT. Notably, the BERT Transformer uses bidirectional self-attention, while the GPT Transformer relies on constrained self-attention, where each token may only attend to the context to its left.
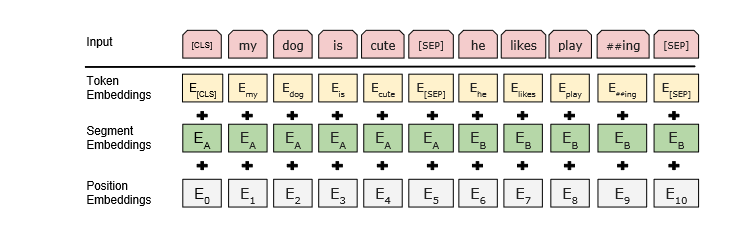
Input/Output Representations
Our input representation can clearly express both a single sentence and a pair of sentences (e.g., Question, Answer ") in one token sequence to support a wide range of downstream tasks. Throughout the paper, "sentences" might refer to an arbitrary stretch of contiguous text rather than linguistic sentences.
The term "sequence" refers to the input token sequence that is sent to BERT, which may consist of a single sentence or two sentences that are packed together.
- 30,000-token WordPiece embeddings were used as stated in the paper.
- In every sequence, the initial token is always a special classification token (CLS). The token's final hidden state serves as the aggregate sequence representation for classification tasks.
- There are two approaches to differentiate the sentences. A specific token is used to separate them (SEP). The second step is to add to every token a learned embedding indicating whether it belongs to sentence A or sentence B.
- The authors denote input embedding as E, the final hidden vector of the special CLS token as C, and the final hidden vector for the ith input token as Ti.
- For a given token, its input representation is constructed by summing the corresponding token, segment, and position embeddings(see the figure below).
Pre-training BERT
BERT was pre-train using two unsupervised tasks:
Masked LM
It's pretty simple to train a deep bidirectional representation by masking some fraction of the input symbols. Masked LM (MLM) is the term used to describe this process, even though the term "Cloze task" is more often seen in the literature (Taylor, 1953). As in a typical LM, the output softmax is supplied with the final hidden vectors corresponding to the mask tokens. The researchers randomly mask 15% of all WordPiece tokens in each sequence.
Downside and Solution
Even if we can get a bidirectional pre-trained model, the MASK token doesn't emerge during fine-tuning, which creates a discrepancy between pretraining and fine-tuning. To avoid this, we don't always use the actual MASK token to replace "masked" words. The training data generator randomly selects 15% of the token positions for prediction. Whenever the i-th token is selected, we replace it with one of three options:
- The MASK token (80% of the time)
- A random token (10%)
- The unchanged i-th token (10%)
To predict the original token, Ti will be utilized with cross-entropy loss.
Next Sentence Prediction (NSP)
Question Answering (QA) and NLI (Natural Language Inference) are essential downstream tasks that rely on apprehending the relationship between two sentences, which is not immediately represented by language modeling.
In the paper, the pretraining was performed for a binary next sentence prediction challenge that can be easily produced from any monolingual corpus to build a model that understands sentence relationships. Pretraining examples, in particular, choose 50 percent of the time from the corpus the next sentence that follows A (labeled as IsNext) and 50 percent of the time from a random sentence in the corpus(labeled as NotNext). The figure above illustrates the usage of C for Next Sentence Prediction(NSP).
Pretraining data
To a large extent, the pretraining technique follows the already published research on language model pretraining. The researchers utilize the BooksCorpus (800 million words) and Wikipedia (English) for the pretraining corpus (2,500M words). Extracting text passages for Wikipedia, they do not include lists, tables, and headers.
Fine-tuning BERT
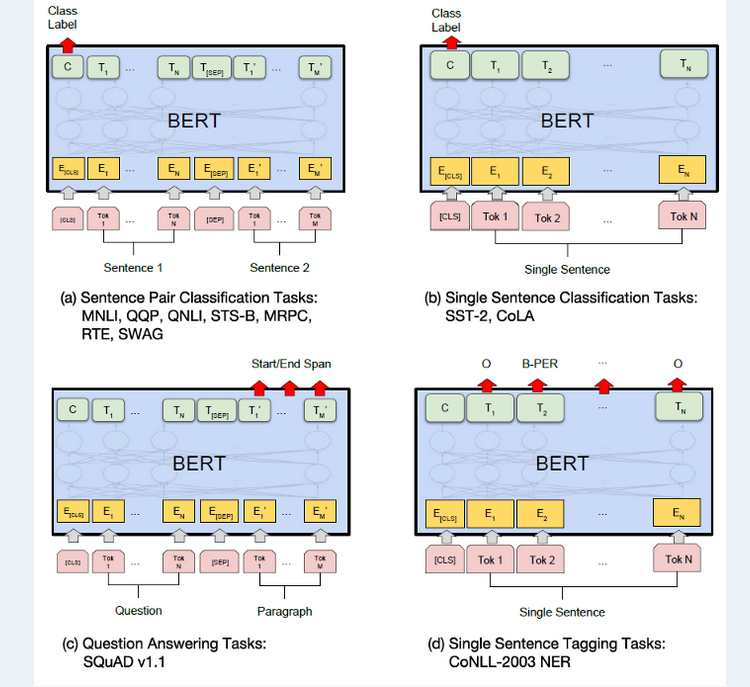
BERT's self-attention mechanism in the Transformer makes fine-tuning simple since it can model a wide range of downstream tasks, whether they entail a single text or a pair of texts. Before applying bidirectional cross attention to text pairings, frequent practice is to encode the text pairs independently. Instead, BERT employs the self-attention mechanism to combine these two steps since encoding a concatenated text pair with self-attention effectively incorporates bidirectional cross attention between two sentences.
For each task, we simply plug in the task-specific inputs and outputs into BERT and fine-tune all the parameters end-to-end.
Pretraining sentences A and B are similar to:
- sentence pairs in paraphrase,
- hypothesis-premise pairs in entailment,
- question-passage pairs in answering questions, and
- a degenerate text-pair in text classification or sequence tagging.
At the output, the token representations are fed into an output layer for token-level tasks, such as sequence tagging or question answering, and the CLS representation is fed into an output layer for classification, such as entailment or sentiment analysis.
Fine-tuning is quite affordable in comparison to pretraining. Reproducing the paper's results using a single Cloud TPU can be done in less than an hour(or a few hours on a GPU).
Experiments
Here, we show the fine-tuning outcomes of BERT on 11 NLP tasks.
GLUE
The benchmark known as the General Language Understanding Evaluation (GLUE) is a compilation of a wide variety of natural language understanding tasks.
- To perform fine-tuning on GLUE, the researchers first represent the input sequence; then, they use the final hidden vector C that corresponds to the first input token (CLS) as the aggregate representation.
The only new parameters introduced during fine-tuning are classification layer weights R^K×H, where K is the number of labels. We compute a standard classification loss with C and W, i.e., log(softmax(CW^T)).
- For all GLUE tasks, they employ a batch size of 32 and fine-tune for three epochs on the data. The optimal fine-tuning learning rate (among 5e-5, 4e-5, 3e-5, and 2e-5) was picked for each task in the Dev set.
- BERTLARGE fine-tuning was unstable on small datasets, so they did multiple random restarts and chose the best model on the Dev set. Random restarts employ the same pre-trained checkpoint but execute various fine-tuning data shuffling and classifier layer initialization. The results are presented below.
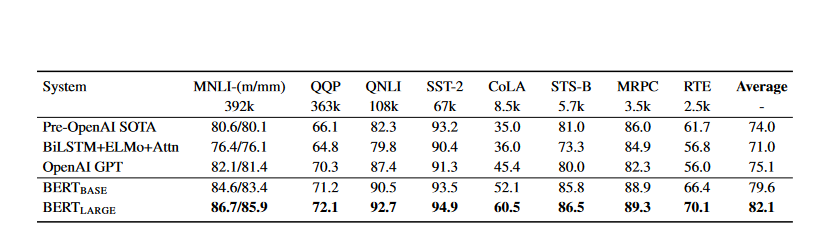
- There is a significant gap between the accuracy gains achieved by BERTBASE and BERTLARGE compared to the previous state-of-the-art(4.5 percent and 7.0 respectively).
- One notable difference between BERTBASE and OpenAI GPT is the attention masking; the rest of their model architectures are essentially similar. With MNLI, the most significant and commonly reported GLUE task, BERT improves absolute accuracy by 4.6%. BERTLARGE ranks higher than OpenAI GPT on the GLUE official leaderboard10, scoring 80.5.
- BERTLARGE performs noticeably better than BERTBASE across the board, particularly in tasks requiring little training data.
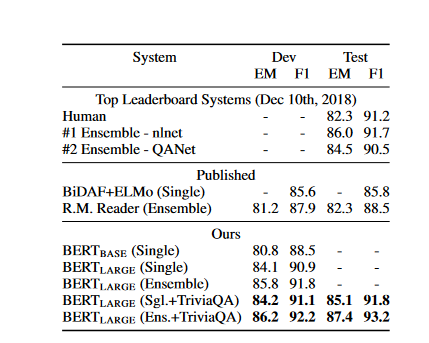
SQuAD v1.1
The Stanford Question Answering Dataset (SQuAD v1.1) is a collection of 100k crowd-sourced question/answer pairs. In answering question task, researchers use the A and B embeddings to represent the input question and passage as a single packed sequence.
They add a start vector S and an end vector E during fine-tuning. Dot product between Ti and S and a softmax over all words in the paragraph are used to determine the probability of word i being the start of the answer span:
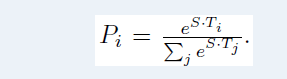
The score of a candidate span moving from position i to position j is computed as follows:
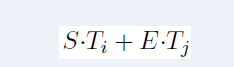
Our best-performing system outperforms the top leaderboard system by +1.5 F1 in ensembling and +1.3 F1 as a single system. In fact, our single BERT model outperforms the top ensemble system in terms of F1 score.
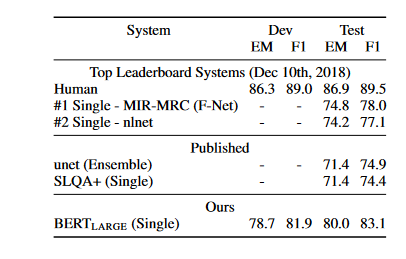
SQuAD v2.0
The SQuAD 2.0 task expands the specification of the SQuAD 1.1 issue by allowing for the possibility that the given paragraph does not include any short answers, making the problem more realistic. To accomplish this objective, researchers use a straightforward strategy to expand the SQuAD v1.1 BERT model. They consider inquiries that do not have an answer to have answer spans that start and end at the CLS token.
The probability space for the start and end answer span position has been expanded to include the position of the CLS token. Below is a comparison of the results to previous leaderboard entries and top published work that does not include systems that use BERT. An improvement of +5.1 F1 over the previous best system can be observed.
SWAG
There are 113k sentence-pair completion examples in the Scenario With Adversarial Generations (SWAG) dataset that assesses grounded common sense. The goal is to choose the most logical continuation from a set of four options.
It is feasible for the SWAG dataset to be fine-tuned by creating four input sequences, each of which contains a potential continuation(sentence B) of the supplied sentence(sentence A).
The only task-specific parameters that are introduced are in the form of a vector. This vector's dot product with the CLS token representation C indicates a score for each possible option, and this score is then normalized using a softmax layer.
We fine-tune the model for three epochs with a learning rate of 2e-5 and a batch size of 16. Results are presented in the figure below. BERTLARGE outperforms the authors’ baseline ESIM+ELMo system by +27.1% and OpenAI GPT by 8.3%."
Ablation Studies
In this section, the authors undertake ablation experiments across a variety of different facets of BERT so that we can have a better understanding of the relative importance of these facets.
Effect of Pre-training Tasks
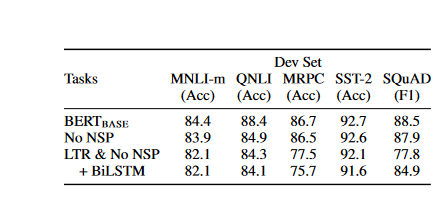
the authors highlight the significance of BERT's deep bidirectionality by assessing two pretraining goals using the same pretraining data, fine-tuning technique, and hyperparameters as BERTBASE:
- No NSP: A bidirectional model that is trained using the "masked LM" (MLM) but does not include the "next sentence prediction" (NSP) task. This model is referred to as having "no NSP."
- LTR & No NSP: Rather than employing an MLM, a typical Left-to-Right (LTR) LM is used to train the left-only model. Fine-tuning also used the left-only restriction since eliminating it caused a pre-train/fine-tune mismatch, resulting in reduced performance. It is also worth noting that the NSP task was omitted from the model's pretraining.
- The LTR model performs more poorly on every task than the MLM model, with particularly significant declines on MRPC and SQuAD.
- Because the token-level hidden states in SQuAD do not include any right-side context, it is intuitively obvious that an LTR model will not perform well when making token predictions. On top of the LTR system, we tacked on a randomly initialized BiLSTM so that we could make an honest effort to improve its strength. Even though this dramatically enhances the results on SQuAD, the results are still of much lower quality than those produced by the pretrained bidirectional models. The BiLSTM hurts performance on the GLUE tasks.
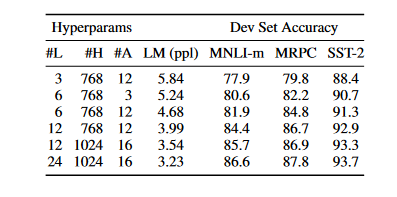
Effect of Model Size
The researchers trained some BERT models with a differing number of layers, hidden units, and attention heads while otherwise using the same hyperparameters and training procedure.
- The figure below displays the results of a few different GLUE tasks. In this table, we provide the average Dev Set accuracy from 5 random restarts of fine-tuning. All four datasets show that larger models lead to a consistent gain in accuracy, even for MRPC, which only includes 3,600 labeled training examples and is significantly different from the pretraining tasks.
- It has long been recognized that expanding the model size would lead to constant advances in large-scale tasks such as machine translation and language modeling, as illustrated by the LM perplexity of held-out training data in the figure below.
- However, the authors think this is the first effort to persuasively show that, given a suitably pre-trained model, scaling to extreme model sizes also leads to considerable gains on small-scale tasks.
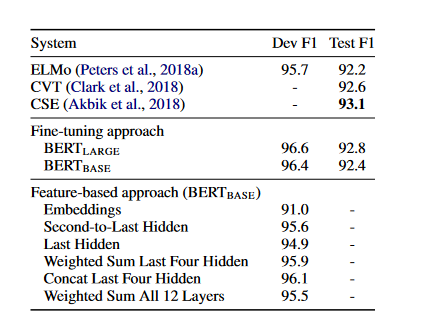
Feature-based Approach with BERT
All of the BERT results provided up to this point have used the fine-tuning method. In this method, a basic classification layer is added to the pre-trained model, and then all of the parameters are jointly fine-tuned on a down-stream task. The feature-based technique in which fixed features are taken from a pre-trained model offers a few benefits:
- Because not every task can be represented by a Transformer encoder architecture, a task-specific model must be introduced.
- Second, there are significant computational advantages to pre-computing a costly representation of the training data once and then running numerous tests with cheaper models on top of this representation.
- To avoid fine-tuning approach, the researchers use the feature-based technique by extracting activations from one or more layers. Before the classification layer, these contextual embeddings are fed into a 768-dimensional BiLSTM with a randomly initialized two-layer structure.
- The results are shown in the below figure. BERTLARGE utilizes cutting-edge technology to provide competitive results. Concatenating the top four hidden layers of the pre-trained Transformer's token representations is the best-performing technique, which is just 0.3 F1 behind fine-tuning the entire model. Regarding fine-tuning and feature-based processes, BERT is an excellent choice.
Emotion Text Classification using BERT
In the context of this tutorial, we shall go into some depth on implementing the BERT base model with regard to the classification of text. We will see how this cutting-edge Transformer model can accomplish incredibly high-performance metrics with respect to a large data set.
Bring this project to life
Commands to check for available GPU and RAM allocation on runtime
gpu_info = !nvidia-smi
gpu_info = '\n'.join(gpu_info)
if gpu_info.find('failed') >= 0:
print('Select the Runtime > "Change runtime type" menu to enable a GPU accelerator, ')
print('and then re-execute this cell.')
else:
print(gpu_info)Install Required Libraries
- Transformer package from Hugging Face Library(transformers) contains Pre-Trained Language models.
- ktrain is a lightweight wrapper for the deep learning library TensorFlow Keras (and other libraries), and it was designed to assist in building, training, and deploying neural networks and other machine learning models.
!pip install ktrain
!pip install transformers
!pip install datasetsimport numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import ktrain
from ktrain import text
import tensorflow as tf
from sklearn.model_selection import train_test_split
from datasets import list_datasets
from datasets import load_dataset
from sklearn.metrics import classification_report, confusion_matrix
import timeit
import warnings
pd.set_option('display.max_columns', None)
warnings.simplefilter(action="ignore")Dataset Loading
## Train and validation data
emotion_t = load_dataset('emotion', split='train')
emotion_v = load_dataset('emotion', split='validation')
print("\nTrain Dataset Features for Emotion: \n", emotion_t.features)
print("\nValidation Dataset Features for Emotion: \n", emotion_v.features)
## dataframe
emotion_t_df = pd.DataFrame(data=emotion_t)
emotion_v_df = pd.DataFrame(data=emotion_v)
label_names = ['sadness', 'joy', 'love', 'anger', 'fear', 'surprise']
Train & Validation data Splitting
X_train = emotion_t_df[:]["text"]
y_train = emotion_t_df[:]["label"]
X_test = emotion_v_df[:]["text"]
y_test = emotion_v_df[:]["label"]
print(X_train.shape, y_train.shape, X_test.shape, y_test.shape)Instantiating a BERT Instance
Construct an instance of BERT with the model's name, the maximum token length, the labels that will be used for each category, and the batch size.
bert_transformer = text.Transformer('bert-base-uncased', maxlen=512, classes=label_names, batch_size=6)Perform Data Preprocessing
We must convert split data into list before preprocessing.
bert_train = bert_transformer.preprocess_train(X_train.to_list(), y_train.to_list())
bert_val = bert_transformer.preprocess_test(X_test.to_list(), y_test.to_list())Compile BERT in a Ktrain Learner Object
Since we are using ktrain as a high level abstration package, we need to wrap our model in a k-train Learner Object for further computation. To use ktrain, all we need to do is enclose our model and data in a ktrain.Learner object obtained via the use of the get_learner function.
bert_model = bert_transformer.get_classifier()
bert_learner_ins = ktrain.get_learner(model=bert_model,
train_data=bert_train,
val_data=bert_val,
batch_size=6)BERT Optimal Learning Rates
This step is optional and serves just to demonstrate how the learning rate can be determined for any transformer model. The optimal learning rates for Transformer models have been determined and defined in the research papers(among 5e-5, 4e-5, 3e-5, and 2e-5). The method lr_find() simulate training to find optimal learning rate.
rate_bert_start_time = timeit.default_timer() ## we mesure the execution time ##using the function timeit()
bert_learner_ins.lr_find(show_plot=True, max_epochs=3)
rate_bert_stop_time = timeit.default_timer()
print("\nTotal time in minutes on estimating optimal learning rate: \n", (rate_bert_stop_time - rate_bert_start_time)/60)Output:
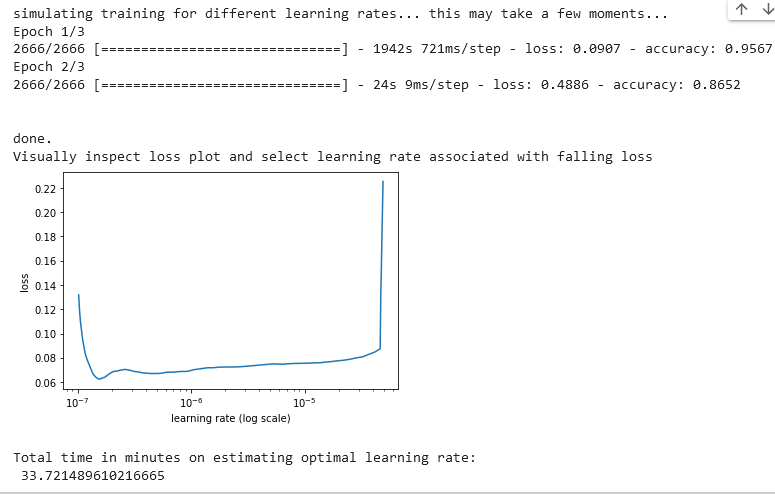
Fine Tuning BERT on Emotion Dataset
We begin the process of fine-tuning by taking our emotion dataset and the BERT model we built and specifying the learning rate and the number of epochs to be utilized. The fit_onecycle() method ramps up the learning rate from the base rate to its maximum during the first half of the training cycle and then gradually decreases it to a near-zero value during the second half. fit_onecycle() employs 1cycle policy
## Fine tuning BERT on Emotion Dataset
## we mesure the execution time using the function timeit()
bert_fine_tuning_start= timeit.default_timer()
bert_learner_ins.fit_onecycle(lr=2e-5, epochs=3) ##1cycle learning rate ##schedule for 3 epochs
bert_fine_tuning_stop = timeit.default_timer()
print("\nFine-Tuning time for BERT on Emotion dataset: \n", (bert_fine_tuning_stop - bert_fine_tuning_start)/60, " min")Note: The reader can run those operations and appreciate the results by himself.
Checking BERT performance metrics
## Performation metrics of Bert model on emotion dataset
## we mesure the execution time using the function timeit
bert_validation_start= timeit.default_timer()
bert_learner_ins.validate()
bert_validation_stop= timeit.default_timer()
print("\nInference time for BERT on Emotion dataset: \n", (bert_validation_stop - bert_validation_start), " sec")Output:
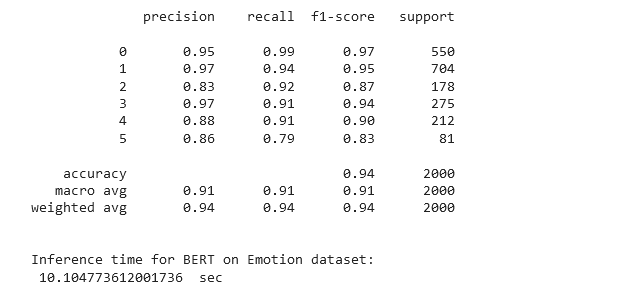
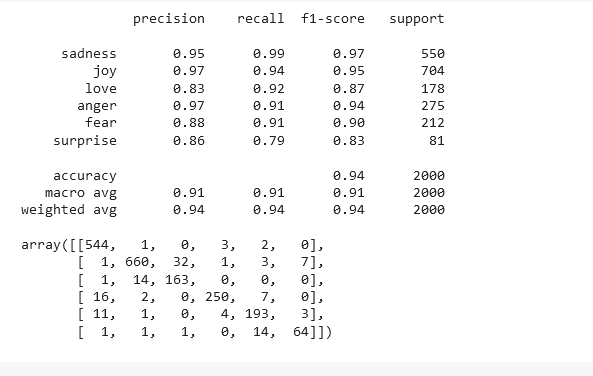
The above result shows that we have got an accuracy of 94%.
Checking performance metrics for each label
## Here we can get the performance metric for each label
bert_learner_ins.validate(class_names=label_names)Output:
Saving BERT Model
bert_predictor = ktrain.get_predictor(bert_learner_ins.model, preproc=bert_transformer)
bert_predictor.get_classes()Save Bert model into your current directory using the save() method
bert_predictor.save('/path/bert-pred-emotion')Some Variants of BERT
RoBERTa: A Robustly Optimized BERT Pretraining Approach
In this paper, the authors report a replication study of BERT pretraining, which includes a thorough analysis of the impacts of hyperparameter tweaking and training set size. The paper shows that BERT was severely undertrained and provides RoBERTa, a more efficient recipe for training BERT models that can achieve performance on par with or better than any post-BERT technique. Our adjustments are straightforward and include the following:
- trained the model for longer with larger batches across more data.
- eliminated the next sentence prediction target.
- trained on longer sequences.
- dynamically changed the masking pattern used for the training data.
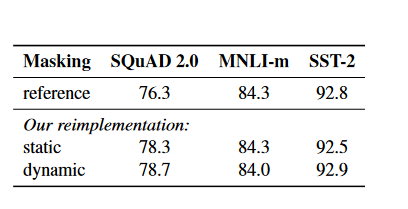
Static vs. Dynamic Masking
BERT uses a system of random token masking and prediction.
In the first BERT implementation, masking is performed only once during data preprocessing, resulting in a static mask. The authors evaluate this method against dynamic masking, in which a new masking pattern is generated each time a sequence is fed into the model. It is vital for larger datasets or for adding more steps to the pretraining process.
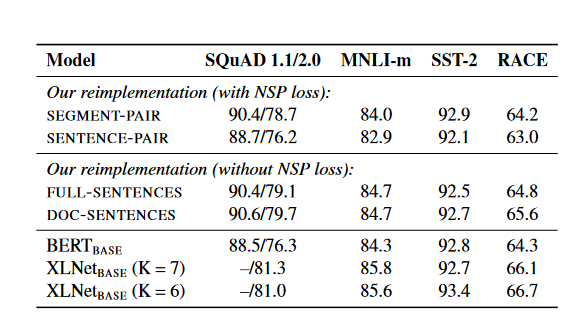
Model Input Format and Next Sentence Prediction
In the original BERT pretraining process, the model takes in the information from two concatenated document segments that are either sampled contiguously from the same document (with p = 0.5) or from different documents.
In addition to the masked language modeling objectives, an auxiliary Next Sentence Prediction (NSP) loss is used to train the model to determine whether the observed document segments are from the same or distinct documents.
We next compare training without the NSP loss and training with blocks of text from a single document (DOC-SENTENCES). We find that this setting outperforms the originally published BERTBASE results and that removing the NSP loss matches or slightly improves downstream task performance
Training with Large Batches
Research in the field of Neural Machine Translation has shown that, with an appropriately increased learning rate, training with very large mini-batches can improve optimization speed and end-task performance. Large-batch training is shown to increase both perplexity for the masked language modeling objective and end-task accuracy.
Text Encoding
With its ability to accommodate the enormous vocabularies seen in natural language corpora, Byte-Pair Encoding (BPE) is a representational method that combines character-level and word-level encodings. BPE uses subword units instead of entire words; these units are retrieved by statistical analysis of the training corpus. BPE vocabulary sizes typically range from 10K-100K subword units.
Emotion Text Classification using RoBERTa
We must follow the same process as with BERT, just that here, to instantiate RoBERTa, just write:
roberta_transformer = text.Transformer('roberta-base', maxlen=512, classes=class_label_names, batch_size=6)DistilBERT, a distilled version of BERT: smaller,faster, cheaper and lighter
Through this paper, researchers offer a way to pre-train a compact general-purpose language representation model, DistilBERT, that can be fine-tuned to achieve excellent performance on a variety of applications. They use knowledge distillation during the pretraining phase to reduce the size of a BERT model by 40 percent while maintaining 97 percent of its language understanding capabilities and being 60 percent faster. The authors offer a triple loss that integrates language modeling, distillation, and cosine-distance losses to take use of the inductive biases learned by larger models during pretraining.
Knowledge Distillation
Knowledge distillation is a compression method employed in the distillation process. This approach involves training a smaller model, known as the student, to mimic the behavior of a larger model, known as the teacher, or an ensemble of models. The student is trained with a distillation loss over the soft target probabilities of the teacher:
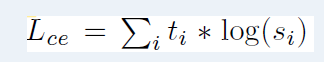
where ti(resp. si) is a probability estimated by the teacher (resp. the student). This objective results in a rich training signal by leveraging the full teacher
distribution. Softmax-temperature is used for this purpose:
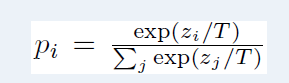
Where T determines how smooth the output distribution is and zi is the model score for the class i. During training, temperature T is kept the same for the student and the teacher; however, during inference, T is set to 1 to recover a typical softmax.
To get at the ultimate training goal, researchers linearly combine the distillation loss with the supervised training loss, which is the masked language modeling loss. To align the directions of the student and teacher hidden state vectors, they found that adding a cosine embedding loss (Lcos) was beneficial.
DistilBERT: a distilled version of BERT
DistilBERT is a student of BERT with similar architecture. The token-type embeddings and the pooler are removed, and the total number of layers is reduced by a factor of 2.
The research showed that variations on the last dimension of the tensor (hidden size dimension) have a minor impact on computation efficiency (for a fixed parameters budget) than variations on other factors like the number of layers and most of the operations used in the Transformer architecture (linear layer and layer normalization) are highly optimized in modern linear algebra frameworks. As a result, we concentrate on minimizing the number of layers.
Emotion Text Classification using DistilBERT
We must follow the same process as with BERT, just that here, to instantiate DistilBERT, just write:
distilbert_transformer = text.Transformer('distilbert-base-uncased', maxlen=512, classes=class_label_names, batch_size=6)ALBERT: A LITE BERT FOR SELF-SUPERVISED LEARNING OF LANGUAGE REPRESENTATIONS
Successes in the field of language representation learning may be traced back to the introduction of the entire network pre-training. These pre-trained models have been beneficial for a wide variety of non-trivial NLP applications, including ones with limited training data.
The improvement of machines at a reading comprehension task created for Chinese middle and high school English examinations (the RACE test) is one of the most striking indicators of these advancements. These advancements show that having a sizable network is essential for optimal performance. Pre-training larger models and then distilling them to smaller ones for practical use is now standard procedure. Due to the importance of model size, the researchers inquire: Is having better NLP models as easy as having larger models?
The current hardware's inability to store a sufficient amount of data presents a limitation to a satisfactory answer to this question. The state-of-the-art models we use today often include hundreds of millions or even billions of parameters, making it simple to run across these limitations when the researchers attempt to scale our models. Because the communication overhead is proportional to the number of parameters in the mode, distributed training may also drastically slow down training speed.
Model parallelization and astute memory management are current approaches to addressing the abovementioned issues. Memory limitations are dealt with, but communication overhead is not. To solve these issues, the authors of this paper designed A Lite BERT (ALBERT) architecture, which uses a lot fewer parameters than traditional BERT designs.
Reduction Techniques
The core of the ALBERT design is a transformer encoder with GELU nonlinearities, the same as in BERT. Following the guidelines established by the BERT notation, the authors use the symbols "E" for the size of the vocabulary embedding, "L" for the number of encoder layers, and "H" for the hidden size. They set the feed-forward/filtersize to be 4H and the number of attention heads to be H/64.
Two of the main hurdles to scaling pre-trained models are eliminated through the parameter reduction techniques used by ALBERT.
Factorized Embedding Parameterization
Firstly, we have a factorized embedding parameterization: Here, The size of the hidden layers is unrelated to the size of the vocabulary embedding, which is achieved by decomposing the large vocabulary embedding matrix into two tiny matrices. This separation makes it easier to grow the hidden size without significantly increasing the parameter size of the vocabulary embeddings.
the WordPiece embedding size E is tied with the hidden layer size H, i.e., E ≡ H. This decision appears suboptimal. From a modeling perspective, WordPiece embeddings are meant to learn context-independent representations, whereas hidden-layer embeddings are meant to learn context-dependent representations.
Using context as a signal for learning context-dependent representations is where BERT-like representations shine. Therefore, the authors use the overall model parameters more efficiently, as dictated by modeling requirements(H≫E), by decoupling the WordPiece embedding size E from the hidden layer size H.
A large vocabulary size V is often necessary for practical purposes in natural language processing. The size of the embedding matrix, V×E, grows proportionally with H if E≡H. Consequently, the resulting model may have billions of parameters.
First, the one-hot vectors are projected into an embedding space of size E and then into the hidden space of size H. Using this decomposition, they reduce the embedding parameters from O(V×H) to O(V×E+E×H). This parameter reduction is significant when H ≫E
Cross-layer Parameter Sharing
The second technique is cross-layer parameter sharing. Using this method, the parameter will not increase in size as the network becomes deeper. Both methods significantly decrease the amount of BERT parameters without severely impacting performance, enhancing parameter-efficiency. ALBERT configuration with the same functionality as BERT-large may be trained around 1.7 times faster with 18 times fewer parameters.
There are multiple ways to share parameters, e.g., only sharing feed-forward network (FFN) parameters across layers, or only sharing attention parameters. The default decision for ALBERT is to share all parameters across layers.
The parameter reduction techniques also serve as a sort of regularization, which helps to stabilize the training and contributes to generalization.
Inter-sentence Coherence Loss
BERT uses a loss known as a next-sentence prediction (NSP). The NSP loss predicts whether two segments occur consecutively in the original text based on binary classification. To generate positive examples, we select consecutive segments from the training corpus; to generate negative examples, we couple segments from different documents; and we randomly sample both positive and negative examples with equal probability. The NSP objective was created to boost performance on downstream tasks like natural language inference, which requires reasoning about the relationship between sentences.
However, further research concluded that NSP's effect was inconsistent and opted to do away with it; this was backed by an increase in downstream task performance across various tasks. The performance of ALBERT is further enhanced by the introduction of a self-supervised loss for sentence-order prediction (SOP). Because the next sentence prediction (NSP) loss proposed in the original BERT was ineffective, SOP now focuses on enhancing the coherence between sentences.
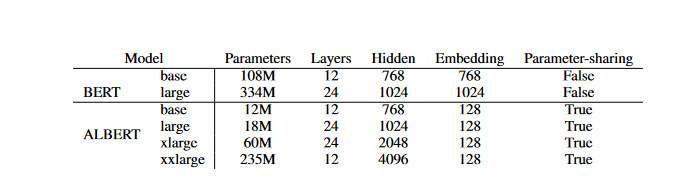
Model Setup
When compared to BERT-large, ALBERT-large uses around 18M fewer parameters. There are only 60M parameters in an ALBERT-xlarge configuration with H = 2048 and 233M parameters in an ALBERT-xxlarge configuration with H = 4096; this is around 70% of the parameters in BERT-large. Note that for ALBERT-xxlarge, we mainly report results on a 12-layer network
because a 24-layer network (with the same configuration) obtains similar results but is computationally more expensive.
ALBERT-xxlarge is computationally more expensive, having fewer parameters than BERT-large and much better outcomes. So, improving ALBERT's training and inference speeds with techniques like sparse attention is a crucial next step.
Emotion Text Classification using ALBERT
We must follow the same process as with BERT, just that here, to instantiate ALBERT, just write:
albert_transformer = text.Transformer('albert-base-v1', maxlen=512, classes=class_label_names, batch_size=6)Conclusion
Using transfer learning with language models, researchers have shown that pretraining is an essential component of many language understanding systems.
As a result of these findings, deep unidirectional architectures are now usable even for low-resource tasks. Researchers have extended these discoveries to deep bidirectional architectures, such that a single pre-trained model may handle a wide range of NLP tasks.
Although BERT, Albert, and Roberta are the three most well-known transformers, numerous other renowned transformers also attain comparable, state-of-the-art performance. We can mention XLNet, BART, Mobile-BERT, and many others.
Based on the Transformer-XL model, XLNet is an autoregressive language model that leverages permutative language modeling to deliver state-of-the-art outcomes comparable to Roberta. Regarding Natural Language Understanding (NLU) tasks, BART is another pre-trained model that competes well with Roberta. In addition, BART's distinctiveness lies in its ability to excel in Natural Language Generation (NLG) tasks like abstractive summarization.
References
BERT: https://arxiv.org/pdf/1810.04805.pdf
ALBERT: https://arxiv.org/pdf/1909.11942.pdf
DistilBERT: https://arxiv.org/pdf/1910.01108.pdf
RoBERTa: https://arxiv.org/pdf/1907.11692.pdf
https://towardsdatascience.com/everything-you-need-to-know-about-albert-roberta-and-distilbert-11a74334b2da
https://sh-tsang.medium.com/review-bert-pre-training-of-deep-bidirectional-transformers-for-language-understanding-59b1684882db
https://towardsdatascience.com/ktrain-a-lightweight-wrapper-for-keras-to-help-train-neural-networks-82851ba889c











