
In my experience, data is one of the most challenging issues that we face in developing any ML/AI pipelines in the field of computer vision. There are two aspects to this issue:
- Data Collection
- Data Labeling
In this post, we will dive into each of these challenges and use the most efficient ways and tools to tackle them.
Data Collection

To build your datasets, I recommend using web scraping to gather large image datasets in an efficient way. This article will help you understand how you can curate image datasets from the web that are under the creative commons license.
In this tutorial, we will learn how to scrape images from the website called unsplash using Python.
The following are the pre-requisites for this tutorial:
- Basic Knowledge of Python
- Python 3.7 environment
- Python libraries : urllib, tqdm, concurrent.futures, requests, BeautifulSoup
We will begin this tutorial by learning how to we can query an image to download from the unsplash website.
This tutorial will be divided into two sections:
- Website Query - Understanding how we can get the URL for scraping
- Python Coding - Automating the web scraping
Bring this project to life
Website Query
- Go to the https://unsplash.com/ using Google Chrome.
- Right click on the webpage and select the inspect option.
- Select the Network --> XHR option. The XMLHttpRequest (XHR) is an API in the form of an object whose methods transfer data between a web browser and a web server.
- This would give us the website URL to which we need to send a request to query the search image URLs for download.
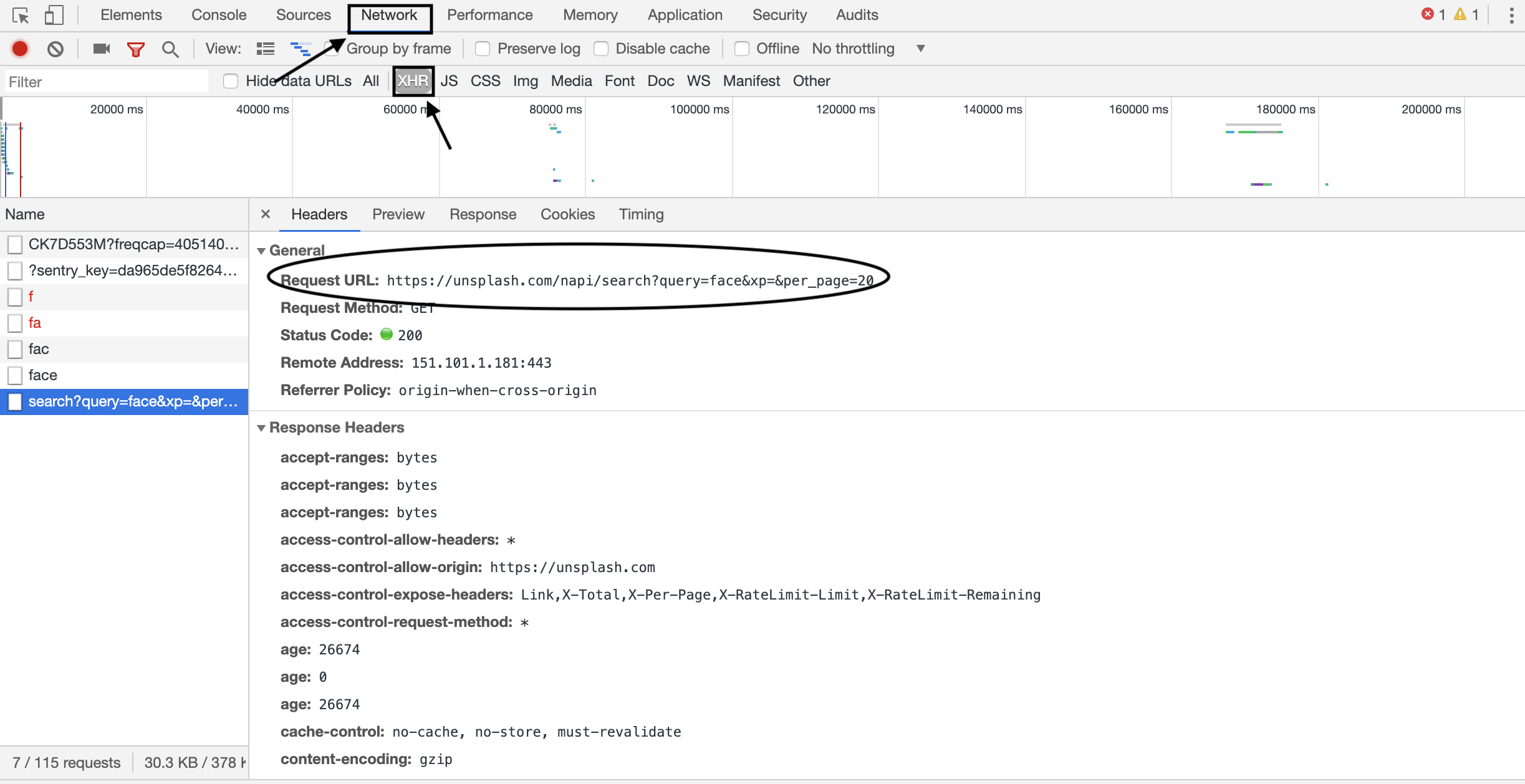
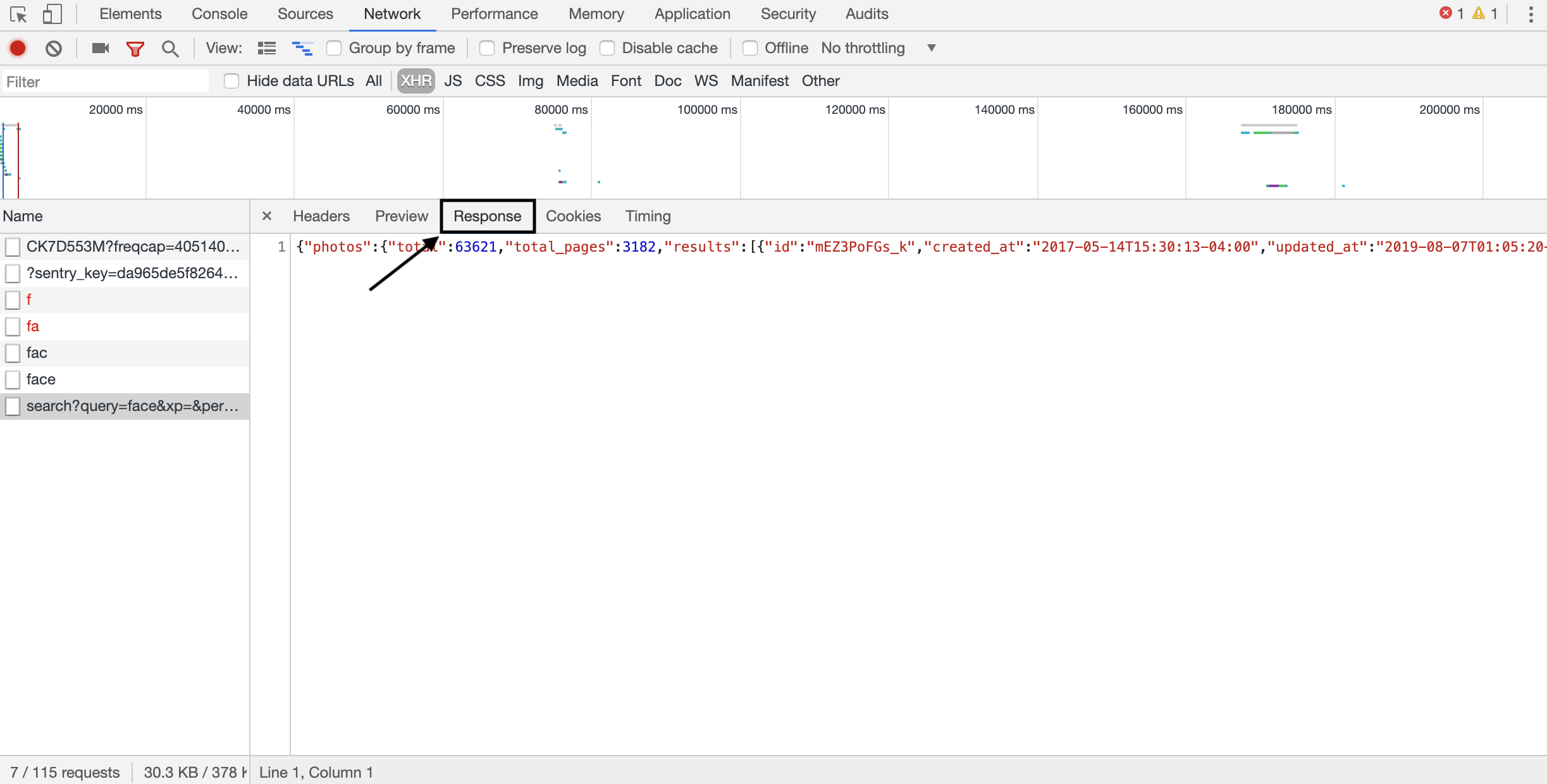
- Select the "Response" option as shown below to see the response that you will get upon pinging the request URL. As you can see, it is in the form of JSON data and we can use the built-in JSON decoder as a part of the
requestlibrary to read it. The keys needed to query the total number of pages to scrape, URLs and IDs of the images can be found here. - Requests is a beautiful and simple HTTP library for Python, built for a high level usage. It removes the complexity of making HTTP requests by taking advantage of this easy to use API that you can focus on for interacting with websites.
Python Coding
Now, lets dive right into how to write the code to automate the web scraping.
We will start by importing all the required libraries in python.
import argparse, urllib3, os, requests
from tqdm import trange,tqdm
from concurrent.futures import ProcessPoolExecutor,as_completedIf we do not have any one of these libraries, you can use "pip3" which is a package installer for python to download them.
Before we start creating an end to end optimized script , let us first test to see if we can query one single image and download it.
Here we start with defining the base_url of the website, next we create a session using the requests library.
Depending on the action that you are trying to perform there are many HTTP methods that you can use. The most common ones are GET and POST(https://en.wikipedia.org/wiki/Hypertext_Transfer_Protocol#Request_methods). For our scenario, we will need to use the GET method to get or retrieve data/content from the specified website. To make a GET request, invoke requests.get() or requests.Session().get().
If you are making multiple requests to the same endpoint than it is better to use a session by calling requests.Session()
website = "https://www.unsplash.com"
session = requests.Session()
search = 'face'
base_url = website+"/napi/search/photos?query={0}&xp=&per_page=20&".format(search)
response = session.get(base_url)
urls=[]
if response.status_code == 200 :
results = response.json()['results']
urls = urls+[(url['id'],url['urls']['raw']) for url in results]
urllib.request.urlretrieve(urls[0][1],'./'+urls[0][0]+'.jpg')A 200 OK status as a response when you call response.status_code means that your request was successful. There are other codes (https://en.wikipedia.org/wiki/List_of_HTTP_status_codes) as well that will let you know what is the status of your request.
Once response.status_code == 200 we can then use the built-in JSON decoder to get the dictionary of results. The keys for the dictionary can be found above in the website query section.
Now that we have the URL of an example image, we will use the urllib package to download this image.
To get the URLs needed for scraping, you could also use beautiful soup library instead of Requests. It is a tool that you can use for dissecting a document and extracting what you need from HTML pages. However, it is more advantageous in cases where the website does not have a backend api unlike unsplash. It is very easy to use and extracts content from the webpage that is easy to navigate . Here is an example on how to use beautiful soup instead of requests in this tutorial for the URLs:
from bs4 import BeautifulSoup
import json
urls=[]
if response.status_code == 200 :
results = BeautifulSoup(response.content,'html.parser')
results = json.loads(str(results))['results']
urls = urls+[(url['id'],url['urls']['raw']) for url in results]
urllib.request.urlretrieve(urls[0][1],'./'+urls[0][0]+'.jpg')Let us use concurrent.futures library to invoke ProcessPoolExecutor to enable multiprocessing to write an end to end pipeline for web scraping to build datasets.
import argparse, urllib, os, requests
from tqdm import trange,tqdm
from concurrent.futures import ProcessPoolExecutor,as_completed
class _unsplash(object):
def __init__(self):
self.website = "https://www.unsplash.com"
self.session = requests.Session()
def __call__(self,search,pages=None):
base_url = self.website+"/napi/search/photos?query {0}&xp=&per_page=20&".format(search)
if not pages:
pages = self.session.get(base_url).json()['total_pages']
urls=[]
for page in trange(1,pages+5,desc = "Downloading image URLs"):
search_url = self.website+"/napi/search/photos?query={0}&xp=&per_page=20&page={1}".format(search,page)
response = self.session.get(search_url)
if response.status_code == 200 :
results = response.json()['results']
urls = urls+[(url['id'],url['urls']['raw']) for url in results]
return list(set(urls))
unsplash = _unsplash()
class _download_imgs(object):
def __init__(self,output_dir,query):
self.query = query
self.directory = output_dir+'/'+query
if not os.path.isdir(self.directory) : os.makedirs(self.directory)
def __call__(self,urls):
with ProcessPoolExecutor() as pool:
downloads = [pool.submit(urllib.request.urlretrieve,url[1],self.directory+'/'+url[0]+'.jpg') for url in urls]
for download in tqdm(as_completed(downloads),total=len(downloads),desc='Downloading '+self.query+" images...."):
pass
class _scrape(object):
def __call__(self,args):
if args.w.lower() == 'unsplash' : urls = unsplash(args.q.lower(), args.p)
download_imgs = _download_imgs(args.o,args.q.lower())
download_imgs(urls)
scrape=_scrape()
if __name__=='__main__':
parser = argparse.ArgumentParser(description='Web Scraping')
parser.add_argument('-w', default='unsplash',choices = ['unsplash'], metavar = 'website', required = False, type = str,
help = 'name of the website that you want to scrape data from, example: unsplash')
parser.add_argument('-q', metavar = 'query', required = True, type = str,
help = 'search term for query, example: mushroom')
parser.add_argument('-o', metavar = 'output directory', required = True, type = str,
help = 'Path to the folder where you want the data to be stored, the directory will be created if not present')
parser.add_argument('-p', metavar = 'no of pages', type = int, help = 'Number of pages to scrape')
args = parser.parse_args()
scrape(args)
Save the above script under webscrape.py and run it from the command line.
python webscrape.py -q mushroom -o /Users/spandana/WebScraping/WebScraping/data -p 1You are now ready to build your own image datasets(under creative commons license) using web scraping.
Data Labelling
In supervised learning, it is important to have labels for the training data as well as to make sure the labels do not have any noise in them to build a robust computer vision algorithm. Data labelling therefore helps us to deal with these two scenarios:
- Cleaning datasets to remove label noise
- Image annotations for generating labels for supervised learning
Image annotations can be divided as follows depending on the objective of the computer vision algorithm.
| Image Annotation Type | Description/example annotation | Use-case |
|---|---|---|
| 2D bounding box | 4 points{points:(x1,y1),(x2,y2),(x3,y3),(x4,y4),label:'dog'} encapsulating the object | Object detection |
| 3D bounding box | 4 points{points:(x1,y1,z1),(x2,y2,z2),(x3,y3,z3),(x4,y4,z4),label:'car'} encapsulating the object | Depth and distance calculation,3D volumes are also used for medical image annotation for radiology imaging to distinguish various structures in the images |
| Lines | The Line Annotation is used to draw lanes to train vehicle perception models for lane detection. Unlike the bounding box, it avoids many blank spaces and additional noises. | Lane detection as a part of autonomous vehicles |
| Polygon | Mainly used to annotate objects with irregular shapes. Labelers must generate boundaries of objects in a frame with high precision, this gives a clear idea about the shape and size of the object. | Fashion and apparel classification |
| Keypoints | multiple points and labels,Ex:[{points:(x1,y1),label:'nose'} ,{points:(x2,y2),label:'outer-left-eye'}] | Face Landmarks estimation |
| Semantic Segmentation | Pixel level labelling, divides image into multiple segments.Each segment is usually indicated by a unique color code | Geo-sensing(recognize the type of land cover) |
| Image classification | Single label for the entire image, Ex: Dog | Animal identification |
This can be done in three ways:
Crowd-sourcing
Companies like Amazon (Mechanical Turk), Figure Eight Inc, Google(Data Labelling service), Hive etc have started an initiative for human in the loop data labelling as a service. This enables a very large number of people working on annotating the dataset based on the set of rules/instructions provided.The throughput of this method is faster but depending on the number of people working on it, the process can be very expensive.
Pre-trained object detection algorithms
This method removes the human in the loop aspect completely and is the only automated way for data annotations. However the main disadvantage of this process is that the quality of the dataset might be low depending on the generalizability of the trained model. Moreover, this process will not work in cases where the application labels are different from the trained model.
Open source image annotation tools
Sometimes due to data privacy and sensitivity, we cannot publish datasets to online platforms for crowd sources data annotations. In such cases, open source image annotations tools are very helpful, where the data is only accessed and annotated locally within the office network. Some of the common tools are RectLabel, LabelImg etc. This is an extremely slow process since depending on the application, very few people will be working on the manual annotations. However this results in a high quality dataset with minimal human errors.
Depending on the amount of data you have that needs labelling as well as the sensitivity aspect of it, you can choose one of the above methods for data annotation. The table below summarizes the three different methods with their pros and cons. At this point, you have curated your data as well as figured a way to label your data.
| Method | Pros | Cons |
|---|---|---|
| Crowd-sourcing | Fast Process | Can be Expensive, Manual errors |
| Pre-trained object detection algorithms | Automation,cost savings(free software) and fast process | Low quality labelled dataset,Might not have the required class labels as an output. |
| Open source Image annotation tools | Cost savings(free software),High quality labelled dataset | Slow process |
Depending on the amount of data you have and needs labelling, you can choose one of the above methods for data annotation. At this point, you have curated your data as well as figured a way to label your data to start training your computer vision algorithms.
References:
[1] https://en.wikipedia.org/wiki/Creative_Commons_license
[2] https://en.wikipedia.org/wiki/Requests_(software)
[3] https://en.wikipedia.org/wiki/Beautiful_Soup_(HTML_parser)
[3] https://en.wikipedia.org/wiki/List_of_manual_image_annotation_tools
[4] Kovashka, A., Russakovsky, O., Fei-Fei, L., & Grauman, K. (2016). Crowdsourcing in computer vision. Foundations and Trends® in computer graphics and Vision, 10(3), 177-243.











