
Bring this project to life
Gone are the days when interacting with PDFs was cumbersome and time-consuming. Users had to open the documents manually using software like Adobe Reader and read through the entire document or use essential search functions to find specific information. But now chatting with an AI assistant is simple with the integration of LangChain. Users can upload PDFs to a LangChain enabled LLM application and receive accurate answers within seconds, through a process called Optical character recognition (OCR).
This benefits businesses requiring customized interaction with company policies, documents, or reports. It can even help researchers and students to identify the important parts and avoid reading the whole book or research paper.
This article will explore the concept of PDF chats using LLM and also show the demo of making PDF AI Chatbot.Integrate the power of LangChain with Paperspace Gradient and redefine the capabilities of chatbots and AI in managing PDF content. RAG (Retrieval Augmented Generation) techniques can also be integrated along with it.
Introduction to PDF Analyser
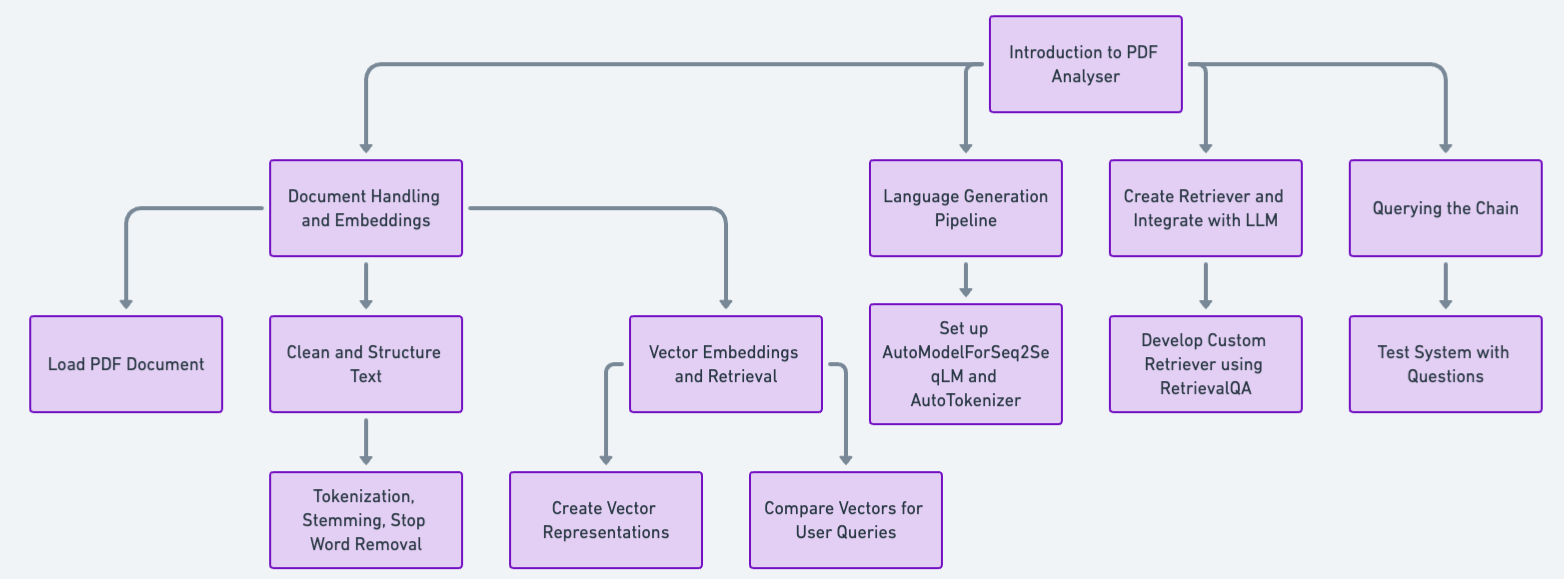
- Document Handling and Embeddings: Load the PDF document using a suitable loader like PyPDFLoader. Clean and structure the text data (removing headers/footers, handling special characters, and segmenting text into paragraphs or sections). It could also involve tokenization (breaking text into words), stemming/lemmatization (reducing words to their root form), or stop word removal (eliminating common words like "the '' or "a '') at this step.
- Vector Embeddings and Retrieval: This involves creating vector representations of the text chunks extracted from the PDFs. These vectors capture the semantic meaning and relationships between words. The chatbot generates a vector for the query and compares it with the stored document vectors during user queries. Documents with the closest vector match are considered the most relevant for the user's question. Libraries like Gensim or Faiss can be used for this approach.
- Language Generation Pipeline: Set up the language generation pipeline using AutoModelForSeq2SeqLM and AutoTokenizer.
- Create a Retriever and Integrate with LLM: Develop a custom retriever using RetrievalQA to fetch relevant documents based on queries.
- Querying the Chain: Test the system by querying the chain with questions related to the PDF content.
Interacting with PDFs Today
Now, it's very easy to understand the contents of PDFs. Just upload the PDF to the LLM application and ask questions about the content in the PDF. It’s the same as chatting with ChatGPT, but users can upload the PDFs directly.
Customized Document Handling
Businesses can now customize the document handling system for more precise interactions with company documents, policies, or reports in PDF format. A vast repository of PDF documents can be prepared for employees, and LLMs can be trained on it. Users can simply upload the document and ask questions in plain language, "What are the company's sick leave policies?", or the sales team can quickly query up-to-date technical specifications or product information from PDF catalogs or manuals.
Dynamic Content Retrieval
RAG (Retrieval Augmented Generation) techniques can incorporate external data in real-time. This means businesses with LLM powered applications can access the most current information from the company database using RAG techniques. This ensures that the generated responses are current and can help decision-making. Imagine a sales team asking about a product's availability. To provide the latest stock status, the LLM not only retrieves information from the PDF manual but also accesses the company's inventory database.
Secure and Efficient Information Extraction
Confidentiality is very important in sectors like financial services and legal services. LLMs can maintain privacy and security by providing information from sensitive PDF documents without exposing the entire context, ensuring only authorized information is accessed.
Application in Knowledge Bases
As new policies or procedures are uploaded as PDFs, an LLM can scan and extract information from PDFs and update the knowledge base by updating FAQs accordingly. LangChain has built in functional integrations with popular storage solutions like Redis.
Improved Customer Satisfaction
Customers can get personalized interaction and quick access to relevant information by integrating PDF interaction chatbots. For example, a chatbot can guide customers in assembling a piece of furniture from IKEA. It can provide step-by-step instructions by referring to the PDF user manual and ensure a smooth customer shopping experience.
We have tried a PDF interaction demo using Langchain below. But why use Langchain?
Lanchain offers pre-built components like retrieval systems, document loaders, and LLM integration tools. LangChain components have already been tested to ensure effective working with documents and alarms. It improves the overall efficiency of the development process and reduces the risk of errors.
Why use Paperspace Gradient for building a PDF Document Interaction Application
Langchain offers several advantages, particularly when combined with Paperspace Gradient. This combination provides a powerful and user-friendly platform for building LLM-powered applications that can interact with documents.
Simplified Development
LangChain provides pre-built components, streamlined workflows, and enables domain-specific customization. Paperspace also provides pre-built libraries like TensorFlow and PyTorch, which are widely used in machine learning and natural language processing tasks, pre-installed on their Notebooks. This allows developers to choose and integrate models with the most advanced PDF analysis and question-answering capabilities.
Integration with HuggingFace Hub
HuggingFace offers many open-source models. Integration with HuggingFace Hub with Paperspace allows implementation and fine-tuning of any model on it according to the use case. Paperspace also presents a user-friendly platform for deployment. Developers can share their trained or fine-tuned models with others on the HuggingFace Hub directly from their Paperspace workspace.
Demo Code
Bring this project to life
This demo used a pre-trained hugging face model, ‘flan-t5-large’. Other open-source models, like FastChatT5 3b Model and Falcon 7b Model, can also be used for this. Start the Gradient Notebook by choosing the GPU and cloning the repository. This repository did not have requirements.txt, so the dependencies were installed separately.
Model and Document Loading
Embedding_Model = "hkunlp/instructor-xl"
LLM_Model = "google/flan-t5-large"
from langchain_community.document_loaders import DirectoryLoader
from langchain_community.document_loaders import PyPDFLoader
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader("/content/langchain/qna_from_pdf_file_with_citation_using_local_Model/pdf_files/TRANSFORMERS.pdf") #path to PDF document
documents = loader.load_and_split()
- ‘hkunlp/instructor-xl’ is the Embedding_Model, and ‘google/flan-t5-large’ is used as LLM_Model defines pre-trained models for text embedding and language generation, respectively. This pre-trained model is taken from HuggingFace.
- A PyPDFLoader loads the PDF file by giving the path to the PDF document. Here, only one PDF document is loaded. Multiple PDF documents can be loaded into the folder, and a path to the folder can also be given.
- The
load_and_splitmethod of the loader reads and splits the PDF content into individual sections or documents for processing.
Testing the Embeddings Mechanism
from langchain_community.embeddings import HuggingFaceInstructEmbeddings
instructor_embeddings = HuggingFaceInstructEmbeddings(model_name=Embedding_Model)
text = "This is a test document."
query_result = instructor_embeddings.embed_query(text)Testing the embedding generation process is common practice before integrating it into a larger system, such as a question-answering system that processes PDF documents. With the selected embedding model, an instance of HuggingFaceInstructEmbeddings is created.
3. Language Generation Pipeline
import torch
import transformers
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
from transformers import pipeline
from langchain.llms import HuggingFacePipeline
tokenizer = AutoTokenizer.from_pretrained(LLM_Model)
model = AutoModelForSeq2SeqLM.from_pretrained(LLM_Model, torch_dtype=torch.float32)
pipe = pipeline(
"text2text-generation",
model=model,
tokenizer=tokenizer,
max_length=512,
temperature=0,
top_p=0.95,
repetition_penalty=1.15
)
llm = HuggingFacePipeline(pipeline=pipe)AutoTokenizer.from_pretrained(LLM_Model)-This convert text into a format that the model can understand.
AutoModelForSeq2SeqLM.from_pretrained(LLM_Model, torch_dtype=torch.float32): This line of code is likely used in a Python script employing the Transformers library for Natural Language Processing (NLP) tasks.AutoModelForSeq2SeqLM: This part of the code refers to a pre-trained model architecture specifically designed for sequence-to-sequence learning tasks. It's used for tasks like machine translation, summarization, and text generation..from_pretrained(LLM_Model): This section loads a pre-trained LLM (Large Language Model) from the transformers library's model hub.torch_dtype=torch.float32:torch.float32indicates that the model will use 32-bit floating-point precision.pipe = pipeline: Creates a text-to-text generation pipeline for generating text with the model.
Parameters for the pipeline:
- model, tokenizer: Specify the model and tokenizer to use.
- max_length: Limits the maximum length of the generated text to 512 tokens.
- temperature (0): Controls randomness in generation (0 means deterministic).
- top_p (0.95): Filters potential next tokens for more likely responses.
- repetition_penalty (1.15): Discourages repetitive text generation.
4. Create a retriever from the index and integrate it with LLM
from langchain_core.retrievers import BaseRetriever
from langchain_core.callbacks import CallbackManagerForRetrieverRun
from langchain_core.documents import Document
from typing import List
class CustomRetriever(BaseRetriever):
def _get_relevant_documents(
self, query: str, *, run_manager: CallbackManagerForRetrieverRun
) -> List[Document]:
return [Document(page_content=query)]
retriever = CustomRetriever()
retriever.get_relevant_documents("bar")
from langchain.chains import RetrievalQA
qa = RetrievalQA.from_chain_type(llm=llm,
chain_type="stuff",
retriever=retriever,
return_source_documents=True)
question = "explain Power Transformers?"This code retrieves relevant documents based on a query and generates answers to questions using those documents. It integrates the retrieved component with a QA pipeline in the LangChain framework.
5. Query the Chain
question = "Ideal transformers can be characterized as?"
generated_text = qa(question)
Generated_textqa(question) call in real-time or interact with the LangChain framework directly and will generate the output.
Closing Thoughts
The fusion of LangChain, and Paperspace Gradient will help developing chatbots for PDFs chatting. Integrating RAG techniques, will streamline chatbot conversations and ensure secure and up-to-date information retrieval from PDF documents. The collaborative environment provided by Paperspace Gradient offers a robust platform for training, deploying and managing LLMs. More enhancements could be made to the PDF analysis. For example, leveraging OCR technology for scanning PDFs or handwritten documents effectively, telling about the source citations. So, the Paperspace platform is perfect for future innovations in this field.
Dive into the world of advanced PDF analysis and chatbot interactions. Explore our pre-built templates, leverage the powerful HuggingFace Hub integration, and experiment with the latest LLM models on the robust, scalable infrastructure provided by Paperspace Gradient.











