
Bring this project to life
This blog post presents TripoSR, a novel 3D reconstruction model utilizing transformer architecture to achieve rapid feed-forward 3D image generation introduced by Stability AI.TripoSR is capable of producing a 3D mesh from a single image in less than 0.5 seconds. Built upon the foundation of the Large reconstruction model (LRM) network architecture, TripoSR incorporates significant enhancements in data processing, model design, and training methodologies. Evaluations conducted on publicly available datasets demonstrate that TripoSR outperforms other open-source alternatives both quantitatively and qualitatively. Released under the MIT license, TripoSR aims to equip researchers, developers, and creatives with cutting-edge advancements in 3D generative AI.
This article also provides a TripoSR demo using the Paperspace platform and by using the NVIDIA RTX A6000 GPU. NVIDIA RTX A6000 is known for its powerful visual computing and the New Tensor Float 32 (TF32) precision provides up to 5X the training throughput over the previous generation. This performance accelerates the AI and data science model training without requiring any code changes.
Model Overview
TripoSR is a cutting-edge model for reconstructing 3D objects from single images. It builds upon the transformer architecture, enhanced with novel techniques. The design of TripoSR is based upon Large reconstruction model (LRM). By leveraging a pre-trained vision transformer (DINOv1) for encoding images, TripoSR captures both global and local features crucial for 3D reconstruction. Its decoder transforms these encoded features into a compact 3D representation, adept at handling complex shapes and textures. Notably, TripoSR doesn't rely on explicit camera parameters, allowing it to adapt to various real-world scenarios without precise camera information. This flexibility enhances its robustness during both training and inference. Compared to its predecessor LRM, TripoSR introduces significant advancements, which we'll explore further.

Two of the major data improvements that has been incorporated during the training data collections are:-
1.) Data Curation:- Carefully curated subset of Objaverse dataset, this has led to enhancement of the training data quality.
2.) Data Rendering:- A wide range of data rendering methods were incorporated to better mimic the distribution of real-world images. This approach strengthens the model's capacity to generalize, even when it's trained solely on the Objaverse dataset.
Triplane Channel Optimization.
One of the adjustments made to boost the model's efficiency and the performance was the arrangements of the channels in the triplane-NeRF representation. This step is crucial for efficiently using GPU memory during both training and inference. It's especially important because volume rendering is computationally intensive. The number of channels also affects how well the model can reconstruct detailed and high-quality images. After experimenting, we settled on using 40 channels. This configuration lets us train with larger batch sizes and higher resolutions while keeping memory usage low during inference.
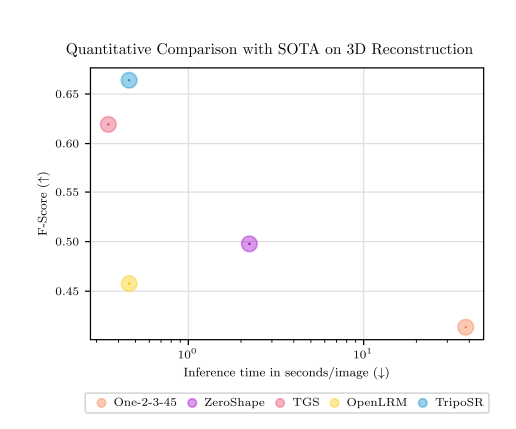
Research Results on TripoSR
TripoSR was evaluated against previous SOTA methods using two datasets and 3D reconstruction metrics. Two public datasets, GSO and OmniObject3D were considered, for evaluations. Further 300 diverse objects were chosen and from each dataset to ensure a fair evaluation. By converting implicit 3D representations into meshes and comparing using metrics like Chamfer Distance and F-score, TripoSR outperformed all previous methods in terms of accuracy.
TripoSR is also fast, taking only about 0.5 seconds to generate a 3D mesh from a single image. Compared to other techniques, it's one of the fastest while maintaining the highest accuracy.
In visual comparisons, TripoSR produces better-shaped and textured reconstructions compared to other methods. While some methods struggle with smoothness or alignment, TripoSR captures intricate details well.
Comparison with Open source LRM (Source)
Visual Results
We further tried TripoSR using few images and here are the results:-
Run TripoSR On Paperspace
Bring this project to life
Let us run the model and use it to generate 3D images. We will start by verifying the GPU specifications:-
!nvidia-smi
- Clone the repository
To begin with clone the repository to get the necessary files
!git clone https://github.com/VAST-AI-Research/TripoSR.git
cd TripoSR/- Upgrade 'setuptools' and install the necessary packages using 'pip'
!pip install --upgrade setuptools
!pip install -r requirements.txt- Once the required libraries are installed, run the gradio app
!python gradio_app.pyThis code block will generate the public URL and local URL, click on the link and you will be redirected to the gradio app.
Furthermore, the code block will generate the Gradio app directly within the notebook itself, showcasing one of the interesting feature of building a Gradio app.
TripoSR Running on Paperspace
Conclusion
In this article we present TripoSR, a cutting edge open-source feedforward 3D reconstruction model. The model is based on a transformer architecture and is developed on the LRM network. This latest image-to-3D model is crafted to meet the increasing needs of professionals in entertainment, gaming, industrial design, and architecture. It offers responsive outputs, enabling detailed 3D object visualization.
We hope you enjoyed reading this article along with the Paperspace demo on the gradio app.








