
We've come a long way as a GPU cloud, supporting over 100k users and continuing to scale rapidly. At times, our growth has imposed a burden on our systems, sometimes in ways we could not predict. In certain cases, this load has had an impact on the overall performance of our product which is something that we take very seriously.
Over the past few releases, we have been making changes to increase the success rate and speed of of our event scheduler, the core mechanism that processes all actions triggered in our web interface and CLI. More broadly, we have made a concerted effort to introduce more resiliency and stability up and down the stack. This involves tighter monitoring, more intelligent alerting, better insight into events and health, and an investment in internal tooling to address issues as they arise. The goal is to increase uptime, be more proactive, and respond quicker to anything that comes up.
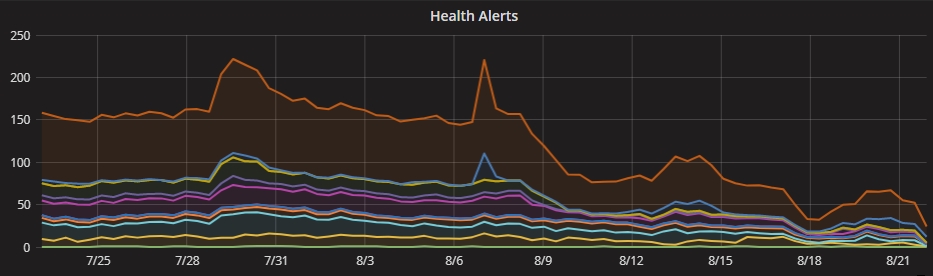
This effort is already starting to pay off: We've seen our scheduler increase in performance by 2x and the number of health alerts has fallen precipitously. The goal is to double-down on these efforts and address any lingering issues as we continue to scale. Most importantly, we are confident that the architecture we have in place is a solid foundation that will support our next phase of growth.
Thank you for bearing with us. We are are extremely grateful for each and every user of our platform.
💗 The PS Engineering Team










