
Bring this project to life
Generative intelligence in the computer vision field has gotten quite a focus after the emergence of deep learning-based techniques. After the success of diffusion process-based techniques, generating images with textual data or with any random noise has become more profound. The images generated by diffusion models are photo-realistic and include details based on provided conditioning. But one of the downsides of diffusion models is that it generates the images iteratively using a Markov-chain-based diffusion process. Due to this, the time complexity of generating an image has been a constraint for diffusion models.
Consistency Models by OpenAI is a recently released paradigm to generate the image in a single step. The researchers responsible for this have taken inspiration from the diffusion models and their main objective is to generate images in a single shot rather than iterative noise reduction which is typically used in diffusion models. Consistency models introduce new learning methodologies to map noisy images at any timestep of the diffusion process to its initial noiseless transformation. The methodology is generalizable and the authors argue that the model can perform image editing type of tasks without any retraining.
Consistency Models
The primary objective of consistency models is to enable single-step image generation without losing the advantages of iterative generation (diffusion process). Consistency models try to bring a balance between the sample quality and the computational complexity. The basic idea of the model is to map the latent noise tensor to the noiseless image corresponding to the initial timestep in the diffusion path as shown in the below figure.
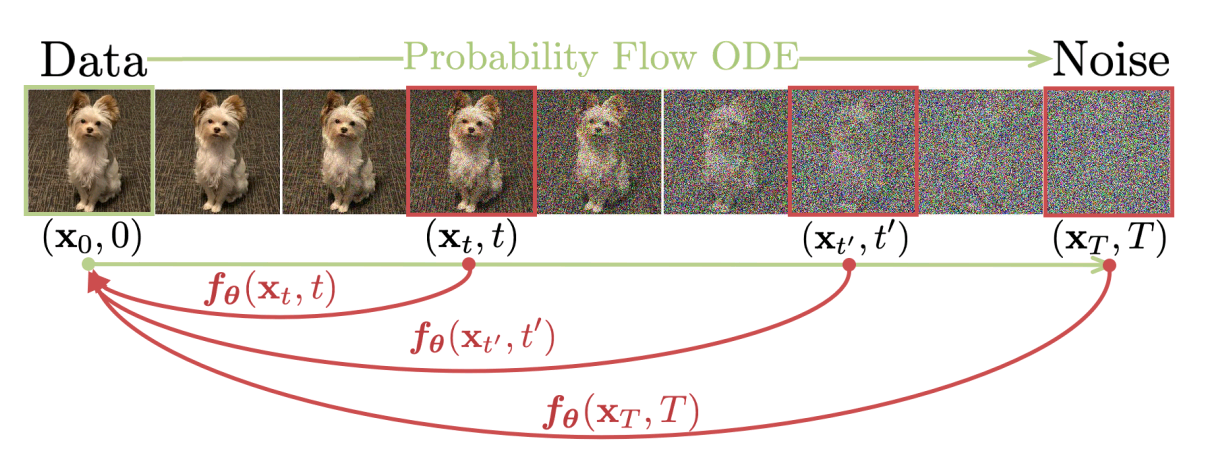
Consistency models have the unique property of being self-consistent. It means that the model maps all latent image tensors in the same diffusion path trajectory to the same initial noiseless image. Though, you can change the path by conditioning the image generation process for image editing tasks. Consistency models take random noise tensor as input and generate the image (starting point of the diffusion path trajectory). Although this workflow looks a lot similar to how adversarial models (GANs) learn, consistency models do not employ any sort of adversarial training scheme.
To train the consistency model, the basic objective is to enforce self-consistency property for image generation. The authors have provided two different methods to train the model.
The first method utilizes the pre-trained diffusion model to generate the pairs of adjacent points on the diffusion path trajectory. It will act as a data generation scheme for training. This method also utilizes Ordinary Differential Equation (ODE) solvers to train the score function used to estimate the probability flow.
The second method avoids using the pre-trained diffusion model and illustrates the process of training the consistency model independently. The training mechanism for this method doesn't assume anything based on a diffusion learning scheme and tries to look at the problem of image generation in an independent way. Let us have a high-level look at the algorithms of both of these methods.
Training Consistency Models via Distillation
This method uses a pre-trained diffusion model to learn self-consistency. In this case, the authors refer to this pre-trained model as the score model. The score model will help us find the exact timestep at which the current noise image tensor is located. For this, we need to discretize the time axis in $N-1$ small intervals in the range $[\epsilon, T]$. The boundaries of these intervals can be defined as $t_1 = \epsilon \lt t_2 \lt \dots \lt t_N = T$. The consistency model tries to estimate intermediate states $x_{t_1}, x_{t_2}, \dots, x_{t_N}$. The larger the value of N, the more accurate output we can get. The below image describes the algorithm to train the consistency model using distillation.

Initially, the image $x$ is sampled from data randomly. The number $n$ is selected from a uniform random distribution. Now, the Gaussian noise is being added to $x$ corresponding to timestep $t_{n+1}$ on the diffusion path to get the noisy image tensor $x_{t_{n+1}}$. Using the one-step ODE solver function (and diffusion model), we can estimate the $\hat{x}_{t_n}^{\phi}$ which is the estimated image noise tensor. The loss function tries to minimize the distance between the model predictions of $(\hat{x}_{t_n}^{\phi}, x_{t_{n+1}})$ pair. Parameter of the consistency model updates based on the gradient computed by the loss function. Note here that there are two networks being employed here: $f_{\theta^-}$ (target network) and $f_{\theta}$ (online network). The target network carries out the prediction for $\hat{x}_{t_n}^{\phi}$ whereas the online network carries out the prediction for $x_{t_{n+1}}$. The authors have argued that using this two-network scheme greatly contributes to stabilizing the training process.
Training Consistency Models Independently
In the previous method, we use a pre-trained score model to estimate the ground truth score function. In this method, we don't use any pre-trained models. To train the model independently, we have to find a way to estimate the underlying score function without any pre-trained model. The authors of the paper argue that the Monte Carlo Estimation of the score function using the original and noisy images is sufficient to replace the pre-trained model in the training function. The below image describes the algorithm to train the consistency model independently.

Initially, the image $x$ is sampled from data randomly. The number $n$ is selected from a uniform random distribution using the scheduled step function. Now, a random noise tensor $z$ is sampled from the normal distribution. The loss is calculated which minimizes the distance between model predictions of $(x+ t_{n+1}z, x+t_nz)$ pair. The rest of the algorithm remains the same as the previous method. The author argues that substituting $x+ t_{n+1}z$ in place of $x_{t_{n+1}}$ and $x+t_nz$ in place of $\hat{x}_{t_n}^{\phi}$ suffices. They base this argument on the fact that the loss function here only depends upon the model parameters $(\theta, \theta^-)$ and is independent of the diffusion model.
Comparison with other models
The authors of the paper have used ImageNet (64 x 64), LSUN Bedroom (256 x 256), and LSUN Cat (256 x 256) datasets for evaluation. The model is compared with other existing models according to the metrics Fréchet Inception Distance (lower is better), Inception Score (higher is better), Precision & Recall (higher is better). The comparison of one of the above-mentioned datasets is shown below. Please head over to the paper to see the comparison of all datasets.
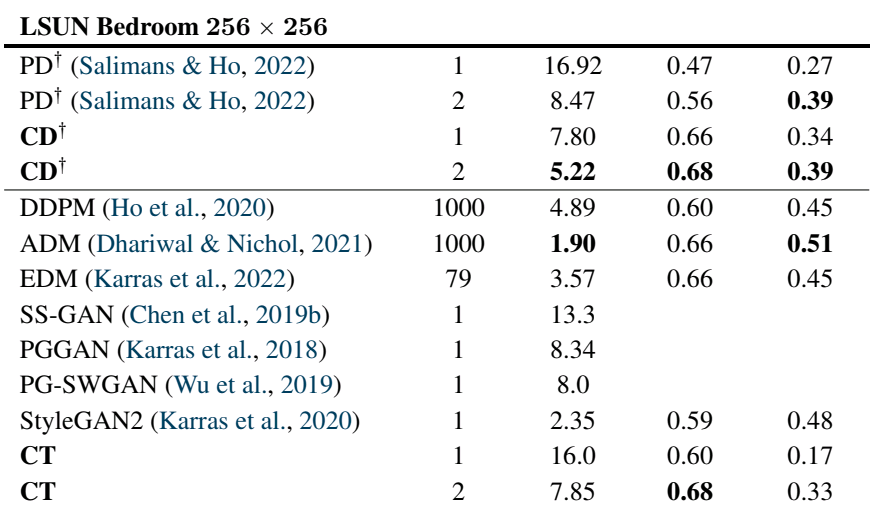
As shown above, the Consistency Training (CT) model is compared with many popular image generation models like DDPM, StyleGAN2, PGGAN, etc. The Consistency Distillation (CD) model is compared with Progressive Distillation (PD) which is the only similar technique to CD researched till now.
We can notice in the comparison table that the consistency models (CD & CT) have comparable & sometimes better accuracy as compared to other models. The authors argue that the intention behind introducing consistency models is not primarily to get better accuracy but to establish the trade-off between the image quality and the time complexity of generation.
Try it yourself
Bring this project to life
Let us now walk through how you can download the dataset & train your own consistency models. For the demo purpose, you don't need to train the model. Instead, you can download pre-trained model checkpoints to try. For this task, we will get this running in a Gradient Notebook here on Paperspace. To navigate to the codebase, click on the "Run on Gradient" button above or at the top of this blog.
Setup
The file installations.sh contains all the necessary code to install the required dependencies. Note that your system must have CUDA to train Consistency models. Also, you may require a different version of torch based on the version of CUDA. If you are running this on Paperspace, then the default version of CUDA is 11.6 which is compatible with this code. If you are running it somewhere else, please check your CUDA version using nvcc --version. If the version differs from ours, you may want to change versions of PyTorch libraries in the first line of installations.sh by looking at the compatibility table.
To install all the dependencies, run the below command:
bash installations.sh
The above command also clones the original Consistency-Models repository into consistency_models directory so that we can utilize the original model implementation for training & inference.
Downloading datasets & Start training (Optional)
Once we have installed all the dependencies, we can download the datasets and start training the models.
datasets directory in the codebase contains the necessary scripts to download the data and make it ready for training. Currently, the codebase supports downloading ImageNet and LSUN Bedroom datasets that the original authors used.
We have already set up bash scripts for you which will automatically download the dataset. datasets contains the code which will download the training & validation data to the corresponding dataset directory. To download the datasets, you can run the below commands:
# Download the ImageNet dataset
cd datasets/imagenet/ && bash fetch_imagenet.sh
# Download the LSUN Bedroom dataset
cd datasets/lsun_bedroom/ && bash fetch_lsun_bedroom.sh
Moreover, we have provided scripts to train different types of models as the authors have discussed in the paper. scripts directory contains different bash scripts to train the models. You can run scripts with the below commands to train different models:
# EDM Model on ImageNet dataset
bash scripts/train_edm/train_imagenet.sh
# EDM Model on LSUN Bedroom dataset
bash scripts/train_edm/train_lsun_bedroom.sh
# Consistency Distillation Model on ImageNet dataset (L2 measure)
bash scripts/train_cd/train_imagenet_l2.sh
# Consistency Distillation Model on ImageNet dataset (LPIPS measure)
bash scripts/train_cd/train_imagenet_lpips.sh
# Consistency Distillation Model on LSUN Bedroom dataset (L2 measure)
bash scripts/train_cd/train_lsun_bedroom_l2.sh
# Consistency Distillation Model on LSUN Bedroom dataset (LPIPS measure)
bash scripts/train_cd/train_lsun_bedroom_lpips.sh
# Consistency Training Model on ImageNet dataset
bash scripts/train_ct/train_imagenet.sh
# Consistency Training Model on LSUN Bedroom dataset
bash scripts/train_ct/train_lsun_bedroom.sh
These bash scripts are compatible with the Paperspace workspace. But if you are running it elsewhere, then you will need to replace the base path of the paths mentioned in the corresponding training script.
Note that you will need to move checkpoint.pt file to checkpoints directory for inference at the end of training.
Don't worry if you don't want to train the model. The below section illustrates downloading the pre-trained checkpoints for inference.
Running Gradio Demo
Python script app.py contains Gradio demo which lets you generate images using pre-trained models. But before we do that, we need to download the pre-trained model checkpoints into checkpoints directory.
To download existing checkpoints, run the below command:
bash checkpoints/fetch_checkpoints.sh
Note that the latest version of the code has the pre-trained model checkpoints for 12 different model types. You can update fetch_checkpoints.sh whenever you have new checkpoints.
Now, we are ready to launch the Gradio demo. Run the following command to launch the demo:
gradio app.py
Open the link in the browser and now you can generate inferences from any of the available models in checkpoints directory. Moreover, you can generate images by modifying different parameters like dropout, generator, and steps.
You should be able to generate images using different pre-trained models as shown in the below video:
Generating Images Using Consistency Models
Hurray! 🎉🎉🎉 We have created a demo to generate images using different pre-trained consistency models.
Conclusion
Consistency Models is an entirely new technique introduced by researchers at OpenAI. The primary objective of these types of models is to overcome the time complexity constraint of diffusion models due to iterative sampling. Consistency Models can be trained either by distilling the diffusion models or can be trained independently. In this blog, we walked through the motivation behind Consistency Models, the two different methods to train such models, and a comparison of these models with other popular models. We also discussed how to set up the environment, train your own Consistency Models & generate inferences using the Gradio app on Gradient Notebook.
Be sure to check out our repo and consider contributing to it!











