
Bring this project to life
In the past year, we have witnessed the continued advent of text to image models. From DALL-E Mini to Stable Diffusion to DeepFloyd IF, there are now a plethora of open sourced models for users with access to GPUs to play with. These incredible models make it possible to generate images containing objects described in text with astounding accuracy to both detail and physical placement. This is thanks to the wealth of information, in paired text to image format, that these models are trained upon.
The natural next step onward from text-to-image generation is, of course, to generate videos. Videos are really just sequences of images, called frames, played after each other at a rapid pace. We have discussed some of the first models to take on this task here on the Paperspace blog, most notably ModelScope and the Stable Diffusion mov2mov extension. While there are some closed source models that have shown incredible promise, such as Runway ML's Gen-2 model, the open source community's attempts are stuck feeling behind the progress of typical text-to-image modeling. Today we will take a look at one of the latest and greatest open source models to take on the text-to-video task: Show-1.
Show-1 was released earlier this month by the researcher team ShowLab. Their novel methodology involves combining latent video diffusion modeling with pixel-based diffusion modeling to achieve higher quality outputs than either method alone. In practice, this model can create much more realistic looking videos than most competitors to come before.
In this tutorial, we will start by doing a brief overview of the model and the underlying technologies. Afterwards, we will go straight into a demo using Paperspace Notebooks to run the provided Gradio application. Follow along to learn how the model works, and how to generate 3 second videos on any subject, though admittedly limited to the Stable Diffusion knowledge base.
Show-1 Model Overview
Let's discuss the basics of the methods used by and underlying architecture of the Show-1 model.
Method

The key discovery and innovation made by the ShowLab team is their novel methodology for hybridizing pixel-based and latent diffusion modeling. They postulated that the pixel based models generated motion with higher accuracy to the textual prompts, but that came at an exponentially higher cost as resolution increased. Latest based models, however, are more research efficient, as they work in a fewer dimension latent space. Additionally, they noticed that the generations in the small latent space (64x40 pixels) were unable to cover the fine semantic details in the text prompt, but that generating at higher resolutions (256x160 pixels) will cause the latent model to prioritize the spatial appearance more while adding the potential to ignore the text-video alignment. In the image above from the Show-1 project page, we can see some examples of this happening. The pixel based VDM's clearly have a higher degree of expression for the textual inputs, but there is a very apparent drop in photorealism.
As described by the authors, it is challenging for such small latent space (e.g., 64×40 for 256×160 videos) to cover rich yet necessary visual semantic details as described by the textual prompt. Therefore, as shown in above figure, the generated videos often are not well-aligned with the textual prompts. On the other hand, if the generated videos are of relatively high resolution (e.g., 256×160 videos), the latent model will focus more on spatial appearance but may also ignore the text-video alignment.
To ameliorate this problem, the authors developed a process to hybridize these two methods. In practice, this allows them to combine the strengths of both techniques - starting with a low-resolution pixel-based diffusion methodology that is later optimized with the high resolution latent based diffusion modeling to achieve videos at super resolutions. In the next section, we will look at the architecture behind this in more detail.
Architecture & Pipeline
The architecture of the Show-1 model is essentially an interconnected series of latent and pixel based diffusion models. Let's take a closer look at the pipeline.

The graphic above overviews the diffusion pipeline used by Show-1 to generate videos. We start with a text input prompt and noisy, initial frames. Using the low-resolution pixel based diffusion technique, Show-1 follows a typical diffusion modeling pipe structure, but alternates UNet's at different stages at the process to achieve the higher quality. After the Key frames are generated, an interpolation UNet is used to generate frames that "connect" the initial key frames in the video and smooth the video. Next, the low-resolution, pixel-based Super Resolution UNet is used to do an initial upscaling of the frames. Finally, the frames are passed to the high resolution latent-based diffusion model for final upscaling to the desired output resolution.
Text-to-Video demo with Paperspace
Bring this project to life
In this section, we will show how to setup and run the Show-1 application demo on a Paperspace Notebook. We have provided a Run on Paperspace link above that users may click on to easily follow along on a Free GPU. Consider upgrading to a more powerful machine if the process of running the demo is time consuming. We tested the demo on a single A100 (80 GB) GPU, and were able to generate our videos in about 160 seconds.
Setting up the demo
Open up the show-1.ipynb file using the file navigator on the left side of the screen. Once that is opened, we can start by running the first two code cells. These will install all the required packages to run the demo.
!pip install -U transformers accelerate torchvision gradio
!pip install -r requirements.txt
In the following cell, we need to provide our HuggingFace CLI access token. This is required to access DeepFloyd IF, which is a component model in the pipeline. To access this token, go to this link.
# Login to huggingface cli
!python login.py --token <your_huggingface_token>After running these cells, we will have completed setup.
Running the demo
To run the demo, we just need to run the next code cell. This will produce a shared Gradio application link for us to access. Note that this may take a while to spin up, as multiple models will need to be downloaded into the cache. One that process is complete, we receive our links.
Below is the code used to run the application:
# Launch the application, be patient as it will take a few minutes to donwload the models to the HuggingFace Cache
!python app.pyGenerating videos with the demo
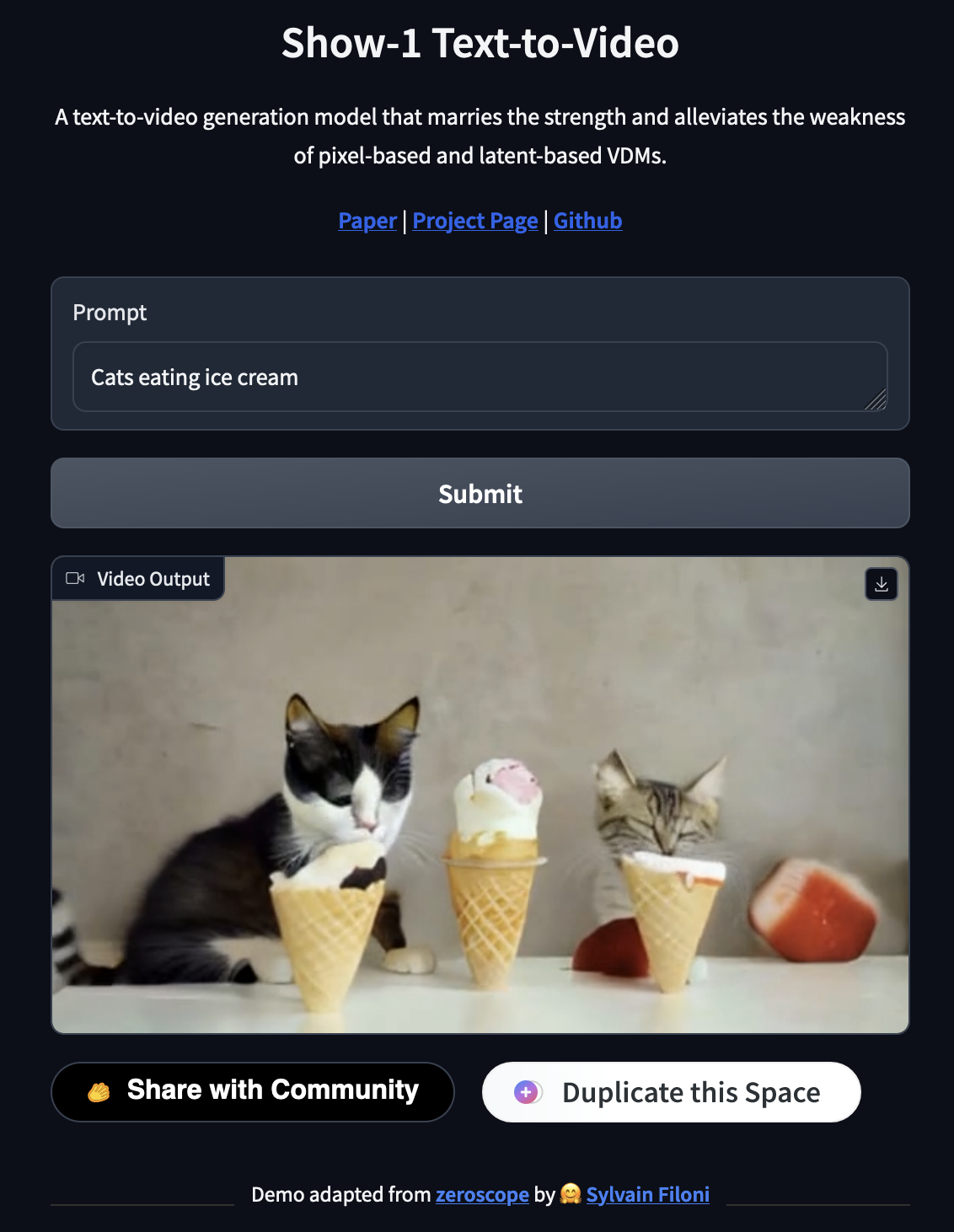
To generate videos with the model, all we need to do now is come up with our prompt. This prompting structure should feel familiar to users of Stable Diffusion or Deep Floyd IF, and it responds best to simple prompts without too many extraneous details. That being said, this model is markedly better at doing so than comparable models. Below are a few examples we made using the demo application:
prompt: Cats eating ice cream
prompt: Goku fighting Vegeta, super saiyana
prompt: "a robot shakes a mans handa robot shakes a mans hand"
Take a moment to examine the examples we show here. These were not curated in any particular way, so that we could call attention to the apparent strengths and weaknesses on display.
As we discussed in the methodology sections, the videos show, qualitatively, a strong understanding of both the variety of inputted details and the objects within are displaced with attention to spatial awareness. For example, the cats faces are digging into the ice cream, the anime characters move in an admirable imitation of punches in fight choreography, and the human and robot appear to clasp hands without fusing together. This clearly demonstrates the hybrid methods efficacy with regards to both details and spatial awareness.
Though the model is clearly a step forward, it is worth mentioning that typical artifacts of diffusion modeling are present throughout. Notably, the model struggles with humanoid and animal features like faces, eyes, and hands, particularly with regard to realistic positioning and some blended features. Additionally, while the interpolation and attention to physical position makes for smooth videos, the objects within are mostly stationary. Other models like ModelScope, though far uglier and harder to control with prompts, have far more motion.
Closing thoughts
Show-1 is a powerful open source model. This much is abundantly clear from our experimentation. Only walled garden models such as Gen-2 outperform the model in our qualitative observations. It's clear that this project is one to keep an eye on as development continues. Notably, the pipeline structure has incredible potential for implementation with the plethora of Stable Diffusion models available on the net. We have visions of using more fantastical models as initial pixel-based models, and combining ultrarealistic, XL models for the latent-based diffusion later in the process. Hopefully, in coming months, this opens the floodgates for some incredible AI art projects to begin being created.
Please be sure to test out this tutorial! Thank you for reading.










