
Bring this project to life
In this blog, we will be doing a deep dive into the paper Dense Passage Retrieval for Open-Domain Question Answering. We will try and understand the theoretical aspect of it followed by a quick pseudo-code implementation of the same.

Open-domain question answering systems heavily rely on efficient passage retrieval methods. This step helps in selecting the relevant candidate contexts for answering any question. Open-domain question answering systems usually follow a 2 step pipeline: (Step 1) Context Retriever (Step 2) Machine Reader. Context retriever is responsible for getting in a small subset of passages that are relevant to the question and may contain answers. The machine reader is responsible for then identifying the correct answer from those sets of passages. In this blog, we majorly discuss the improvements in the Context retriever part of the pipeline.
Traditional systems model some logic of TF-IDF and BM25 into their retrievers, which generally works pretty well, but the question is: "Can we do better"?
We won't be going into the detail of how TF-IDF and BM25 work, feel free to check out this and this for the same. In short, they perform some sort of sparse vector similarity between the weighted bag-of-words representation of two text pieces. The obvious limitation that comes with such systems is not being able to retrieve context where words don't match as it is. Recently with all the hype and impact around modeling the semantics in natural language processing which is contrary to bag-of-words representation, this work from Facebook AI/Meta Labs, University of Washington, and Princeton University shows that retrieval can be efficiently implemented based on dense vector representations and is also seen to surpass traditional techniques by considerable margins.
The authors propose a method to learn these dense representations a.k.a embeddings with just a small number of question and gold passage pairs via a simple dual-encoder framework.
Let's see an example directly as mentioned in the paper to understand what are we exactly trying to solve. Consider the question “Who is the bad guy in Lord of the Rings?”, which can be answered from the context “Sala Baker is best known for portraying the villain Sauron in the Lord of the Rings trilogy.” A term-based system would have difficulty retrieving such a context, while a dense retrieval system would be able to better match the phrase “bad guy” with the word “villain”, and hence fetch the correct context. As we progress more in the blog, we will come to the specifics of the method but let's see some of the results first.
The below image shows the trend of top-k accuracy as we scale the value of k for models trained on ground truth datasets of varying sizes. So here top-k accuracy means, that for a given query (q) how many of the top scoring passages are correct and can deliver the right answer.
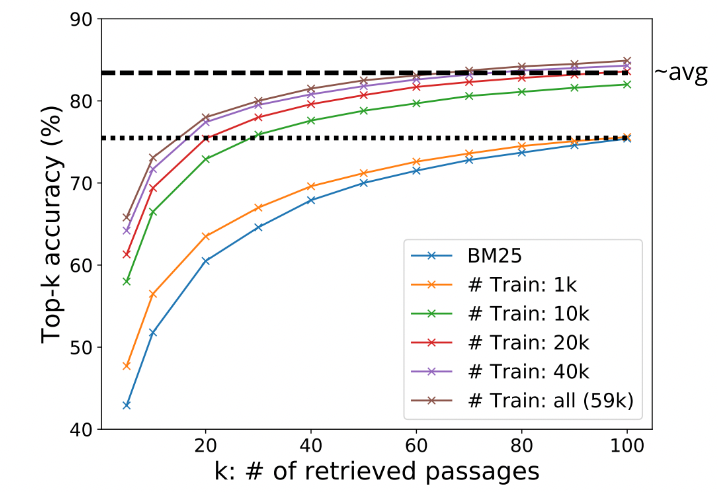
It is clearly visible that with just 10k training samples of question and passage gold pairs, the proposed method can get almost 7-9% improvement in top-k accuracy numbers against the BM25 technique. Here the value of k can range from very less like 5 to significantly high like 100. Surprisingly, if you are interested in getting only 10-20 passages for a given question then even training with just 1k gold samples shows an improvement of close to 2-4% in top-k accuracy over the BM25 technique.
Dense Passage Retriever (DPR)
A dense passage retriever (DPR) is responsible for fetching relevant passages with regards to the question asked based on the similarity between the high-quality low-dimensional continuous representation of passages and questions. Also, since the entire system has to be reasonably fast in serving the user's requests, an index containing these representations is pre-computed and maintained. Now during inference time, for any new query/question that comes up, we can efficiently retrieve some top k passages and later run our reader component on this smaller subset only. The authors in the paper used Facebook AI Similarity Search(FAISS), a library that allows us to quickly (approximate nearest neighbors) search for multimedia documents that are similar to each other. Here, the size of k is dependent on a couple of factors like expected delay in the pipeline, compute available, recall, etc. But generally speaking, any value of k between 10-50 serves the purpose.
The similarity between the question and passage embeddings is represented by calculating the dot product between them. Authors experimented with other similar methods as well but eventually chose dot product because of its simplicity. The higher the similarity score (or less the distance), the more relevant the passage is to the question. The mathematical representation is shown below -
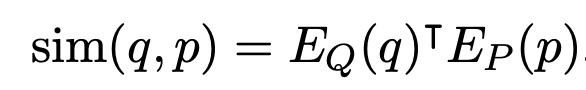
Here, q, p, Eq, and Ep correspond respectively to the question text, passage text, BERT model that outputs question representation, and BERT model that outputs passage representation. Authors use the 768 dimension representation of the CLS token as the final representation of the input text piece.
For training the model, the dataset is represented as $D={<q1,p1,p2,p3..pn>,<q2,p2,p1,p3..pn>...}$, here qi is the ith question and each question is paired with its positive example and some negative examples. For simplicity, the 1st index of each example above is the positive passage to the question qi, and the rest are negative ones. And they optimize the loss function as the negative log-likelihood of the positive passage. The below image shows the mathematical representation of the same -
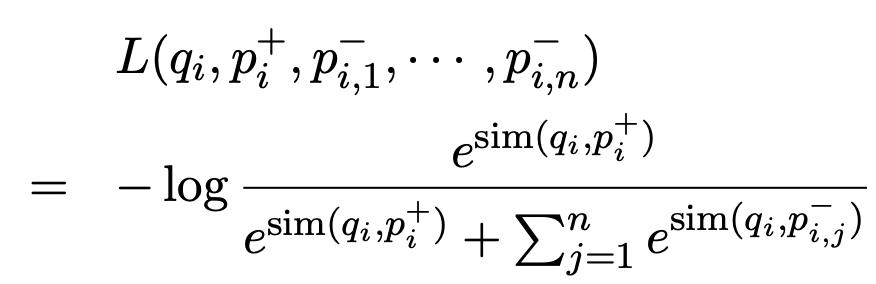
Here, qi, pi(+), and pi(-) are ith question, ith passage that is relevant (positive sample), and ith passage that is irrelevant (negative sample) respectively. The goal of optimization is to maximize the similarity between qi and pi(+) and decrease the similarity between non-relevant ones i.e. qi and pi(-).
Often in retrieval scenarios, getting positive examples is straightforward (as seen with training data where question and relevant passage is given), while one might have to give a thought to efficiently selecting negative examples. Authors in the paper experiment with three kinds of negative generation methods:
- (1) Random: any random passage from the corpus
- (2) BM25: top passages returned by BM25 which might not necessarily contain the answer but match most question tokens
- (3) Gold: positive passages paired with other questions which appear in the training set (specifically the ones present in the same mini-batch). And found some mix of points 3 and 2 to work the best.
With this, we wrap the theoretical understanding of the proposed model. Next, we move to writing the template that you can use to train the DPR model on your dataset.
Code Template
Bring this project to life
We will be using the Simple Transformers python library for setting up the template for implementing the DPR model. Simple Transformers is designed to simplify the usage of Transformer models without having to compromise on utility. It is built on the amazing work of Hugging Face and its Transformers library. It has support for various tasks in NLP, feel free to check out the entire list here.
To get started, we can install the same using the below command -
pip install simpletransformersNext, we need to define all the configurations that we will use to train our model, and import the two packages we will be using for this experiment. The simpletransformers library provides you the option of defining configurations either using dataclass or python dictionaries. We will be using the dataclass: RetrievalArgs for the purpose of this blog. Feel free to check dictionary option as well from this source.
from simpletransformers.retrieval import RetrievalModel, RetrievalArgs
import torch
### loading pre-trained weights of passage and question encoder ###
Eq = "bert-base-uncased"
Ep = "bert-base-uncased"
model_args = RetrievalArgs()
#model_args.retrieve_n_docs
#model_args.hard_negatives
#model_args.max_seq_length
#model_args.num_train_epochs
#model_args.train_batch_size
#model_args.learning_rateHere Eq and Ep hold the model that will be used for encoding the questions and passages. We could also start with some openly available pre-trained DPR encoder for both context and passage (an example of one being context: "facebook/dpr-question_encoder-single-nq-base", passage: "facebook/dpr-ctx_encoder-single-nq-base"). The hard_negatives when set to True help the model to also learn from negative examples generated using techniques like BM25, etc on top of in-batch negatives. As discussed above, the paper also proposes the concept of in-batch negatives and fetching negative samples based on BM25 or a similar method.
For more information, the library authrors provides a code snippet for generating these hard negatives. Please feel free to check it here in their docs.
Next, we load our dataset, and for simplicity purposes we will be manually defining some data points (source). We will import the Pandas library to facilitate this, and will give us as idea of how we can also transform our actual data to fit the pipeline.
import pandas as pd
train_data = [
{
"query_text": "Who is the protaganist of Dune?",
"gold_passage": 'Dune is set in the distant future amidst a feudal interstellar society in which various noble houses control planetary fiefs. It tells the story of young Paul Atreides, whose family accepts the stewardship of the planet Arrakis. While the planet is an inhospitable and sparsely populated desert wasteland, it is the only source of melange, or "spice", a drug that extends life and enhances mental abilities. Melange is also necessary for space navigation, which requires a kind of multidimensional awareness and foresight that only the drug provides. As melange can only be produced on Arrakis, control of the planet is a coveted and dangerous undertaking.',
},
{
"query_text": "Who is the author of Dune?",
"gold_passage": "Dune is a 1965 science fiction novel by American author Frank Herbert, originally published as two separate serials in Analog magazine.",
}
...
]
train = pd.DataFrame(
train_data
)With this, we are good to go ahead and train the DPR model. In the case that we had set the hard_negatives to be True, we'll have to have another key (hard_negative) per data point in the above-mentioned format.
cuda_available = torch.cuda.is_available()
model = RetrievalModel(
model_type = "dpr",
context_encoder_name = Ep,
query_encoder_name = Eq,
args = model_args,
use_cuda = cuda_available
)
model.train_model(train, eval_data = eval, \
output_dir = 'model/', \
show_running_loss = True)
model.eval_model(test, verbose=True)Next, we pass all the necessary parameters to our model and train by specifying the output directory where the model will be saved. The format of the eval and test data frame is also exactly the same as that of the train. Here, train, eval and test are pandas DataFrame that contain 2-3 columns - query_text, gold_passage, hard_negative(optional)
query_text: The query/question text sequencegold_passage: The gold passage text sequencehard_negative: The hard negative passage text sequence from BM25 (optional)
Inferencing with trained DPR model
Once the training is done and you have got your model saved. You can now just pass the question to your model specifying the number of documents to return and you should be good.
questions = [
'What year did Dune release?'
]
predicted_passages, _, _, _ = model.predict(questions, retrieve_n_docs=2)Concluding thoughts
It's super interesting to see the adoption of emerging technology and it being put to use for such practical use cases. In this article, we talked about what DPR is, how it works, and its uses. We also did implement it using the Simple Transformers python library. Feel free to checkout other specifications that you can use to train an efficient model.
I hope you enjoyed the article. Also, if you prefer watching videos over reading text, you can check out the video paper explanation here. Although you'll not find the exclusive implementation found in this blog there ;)











