Fake Bananas - check your facts before you slip on 'em.
Check out our Github repo here!
This year at HackMIT 2017 our team, Fake Bananas, leveraged Paperspace's server infrastructure to build a machine learning model which accurately discerns between fake and legitimate news by comparing the given article or user phrase to known reputable and unreputable news sources. Our project placed in the top 10 (more specific rankings were not disclosed) and won awards for best use of data and best use of machine learning for the common good. Our program is not currently hosted publicly as our backend services carry hefty fees but we hope to change that by working on student pricing with those companies.
Article Outline
- Motivation
- Overview
- Program pipeline
- Parsing input and fetching articles
- Machine Learning for Stance Detection
- Other (worse) methods of Fake News Detection
- Paperspace GPUs
- Source Reputability Database
- Web App Architecture
- Team Members
- References
Motivation
Our goal was to attempt to tackle the growing issue of fake news, which has been exacerbated by the widespread use of social media. For example, many believe fake news on social media to be a large contributing factor to results of the controversial 2016 US election. We wanted to create an easy-to-use system to detect the credibility of a user's claim or article.
Overview
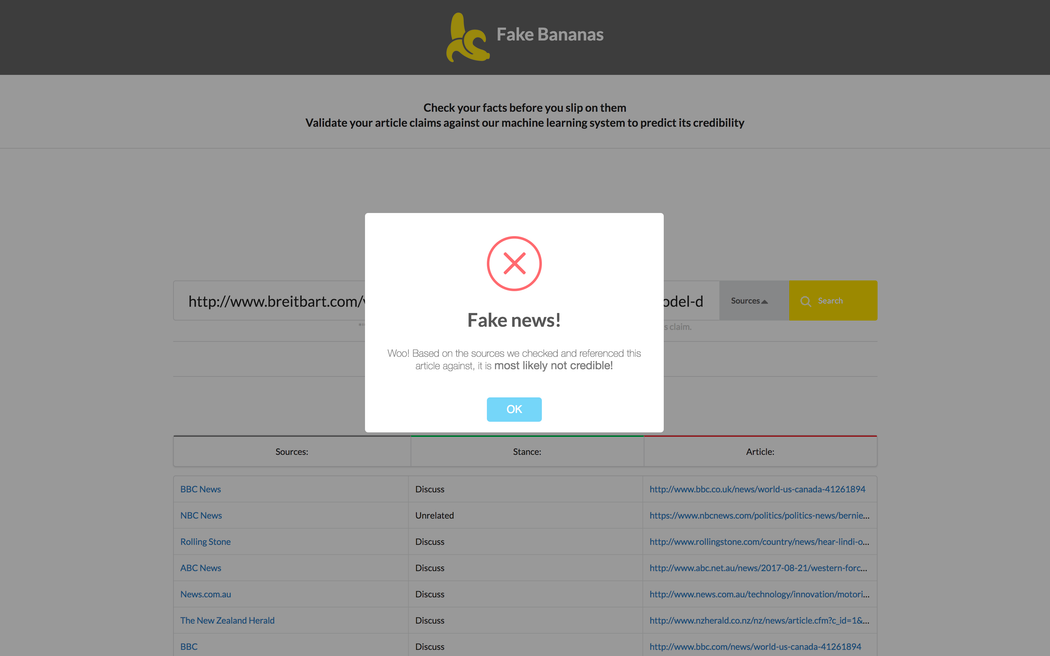
There are many ways one could attempt to detect fake or biased news on the internet. However, we feel our implementation based on stance detection offers the greatest flexibility and are reliability without having to get into the weeds of labeling individual claims as true or false. Rather we aim for a more general approach classifying articles from unknown sources as generally agreeing or generally disagreeing with sources of known (high and low) credibility.
Moreover, our implementation is particularly compelling because we can accept user input as either a link to an article OR as any arbitrary claim to be fact checked like (Obama is not a US citizen). In this way, our program acts as a fact-finding search engine and returns links to relevant articles along with that article's stance (agree/disagree/is-neutral) on that topic! Our program offers tremendous research and discovery potential to users as well as simply checking claims.
We wanted to create an easy-to-use system to detect the credibility of a user's claim or article, based on the concept of stance detection. Fake news is tough to identify. Many 'facts' are highly complex and difficult to check, or exist on a 'continuum of truth' or are compound sentences with fact and fiction overlapping. The best way to attack this problem is not through fact-checking, but by comparing how reputable sources feel about a claim.
Program pipeline
- Users input a claim like "Obama is not a US citizen"
- Our program will search Event Registry's database for thousands of articles related to the keywords.
- We run those articles through our home-grown stance detection machine learning model which will determine each article's relevance to the claim and it's stance on it. We determine if an article agrees/disagrees/is-neutral or is unrelated to the input claim.
- We then access our ever-evolving database of source reputability. If lots of reputable sources all agree with your claim, then it's probably true!
- Then we cite our sources so our users can click through and read more about that topic!
Parsing input and fetching articles
Given a user URL or claim, we used Microsoft's Azure Cognitive and IBM's Natural Language Processing to parse the article or claim and perform keyword extraction. We then used combinations of the keywords to collect up to a few thousand articles from Event Registry's database to pass on to the machine learning model. Here we aired on the side of collecting more rather than fewer articles because the machine learning will accurately determine relevancy further in the pipeline.
After combing through numerous newspaper and natural language processing APIs, we discovered that the best way to find related articles is by searching for keywords. The challenge was implementing a natural language processing algorithm that extracted the most relevant keywords that were searchable, and to extract just the right number of keywords. Many algorithms were simply summarizers and would return well over 50 keywords, which would be too many to search with. On top of that, many algorithms were resource exhaustive and would sometimes take up to a minute to parse a given text.
In the end, we implemented both Microsoft’s Azure and IBM’s Watson to process, parse, and extract keywords given the URL to a news article or a claim. We passed the extracted keywords to Event Registry’s incredible database of almost 200 million articles to find as many related articles as possible.
With more time, we would love to implement Event Registry’s data visualization capabilities which include generating tag clouds and graphs showing top news publishers given a topic.
--Spearheaded by Henry Han
Machine Learning for Stance Detection
Watch a detailed rundown of our machine learning pipeline from this video we created (~4 min) https://www.youtube.com/watch?v=j0n-0-3XhWc.
We created and implemented a machine learning model in Tensorflow that's based on several research papers in the field of stance detection[1][2][3]. Our model uses a combination of Bag-of-Words, Google's word-2-vec, TF, TF-IDF (Term Frequency, Inverse Document Frequency), and 'stopwords' inside Scikit-learn to vectorize our input. That is run through a single hidden layer with ReLU activation, a fully connected layer, and a softmax activation function to produce one of 4 outputs. We are comparing an arbitrary body of text to an arbitrary claim. So our ML outputs whether or not our body of text is 'related' or 'unrelated' to the claim. If it's related, then it outputs if the body 'agrees', 'disagrees' or 'is neutral towards' our claim. Our model achieved 82% accuracy on our test data (for pure stance detection.. not necessarily 'fake news' detection) [4].
One challenge we faced was the slow (~30 second) loading time of a Tensorflow session.
--Spearheaded by Kastan Day
Other (worse) methods of Fake News Detection
1. 'Fake News Style' Detection
Some teams try to train machine learning models on sets of 'fake' articles and sets of 'real' articles. This method is terrible because fake news can appear in well-written articles and vice versa! Style is not equal to content and we care about finding true content.
2. Fact checking
Some teams try to granularly check the truth of each fact in an article. This is interesting, and may ultimately be a part of some future fake news detection system, but today this method is not feasible. The truth of facts exists on a continuum and relies heavily on the nuance of individual words and their connotations. The nuances of human language are difficult to parse into true/false dichotomies.
Human language is nuanced. Determining a single statement as true or false
No databases of what's true or false
Many facts in a single article existing on all sides of the truth spectrum -- is that article true or false?
Paperspace's GPUs
We chose to use paperspace to train and run our machine learning model primarily because of how quick and easy it was to get a paperspace machine up and running for machine learning. This project was completed for HackMIT under a 24-hour deadline. Therefore, speed was of the essence and the MLL-in-a-box preset saved us a significant amount of time while trying to get our TensorFlow moel up and running.
I love Paperspace because it is:
- Fast to setup
- ML in a box eliminates the nightmare that setting up CUDA can become.
- Graphical mode is very useful when first setting up a computer
- Easy to use
- With Windows app terminals are dead simple to access
- Plentiful V-RAM for a bargain
- Our model required roughly 12 GB of V-RAM which made simply the quantity of V-RAM required our biggest limiting factor when choosing a GPU.
- As of posting this article, they're way cheaper than the competition (AWS, Azure) for more V-ram and faster cards.
Source Reputability Database
In order for our application to work, we needed to be able to compare new stances to our ever-improving database of source reputability. We wrote a python script to keep track of all encountered sources along with a reputation score of calculated weight. As a start, we hard-coded reputations based off of nationwide research studies, and then every time we ran our algorithm we added any new encountered sources to our database. In order to do this, we calculated a reputation score for each new article by comparing its stance towards the input claim with the stances of sources with known reputation and averaging the result. In the future, we hope to incorporate more accurate data-science technique's to improve our database. As a smaller project, we also hope to figure out a more streamlined approach than keeping track of the database with csv's by having a copy of the database exist outside of a single run of the application.
--Spearheaded by Josh Frier
Web App Architecture
We used ReactJS for our front end and a Flask dev server as our backend. The Flask server starts our scraping & machine learning prediction script with the parameters of the user's URL or claim when it receives a POST request at an specific endpoint. Our dependencies include two open-source libraries: Semantic-Ui-React and SweetAlerts. We used Facebook's “Create-React-App” tool to create our web application's structure.
--Spearheaded by Jason Jin
Team Members
We're all currently sophmores at Swarthmore College.

References
[1] The University of College London's short paper on the topic:
@article{riedel2017fnc,
author = {Benjamin Riedel and Isabelle Augenstein and George Spithourakis and Sebastian Riedel},
title = {A simple but tough-to-beat baseline for the {F}ake {N}ews {C}hallenge stance detection task},
journal = {CoRR},
volume = {abs/1707.03264},
year = {2017},
url = {http://arxiv.org/abs/1707.03264}
}
[2] Cisco-Talos' work on the Fake News Challenge
https://github.com/Cisco-Talos/fnc-1
[3] The Athene Team for the Fake News Challenge.
Their Github repo
Their Blog Post
Their technical paper
[4] Our training data came from the FakeNewsChallenge.org where in 2016 teams competed to develop stance detection models, and only stance detection models, which we built upon in order to do fake news detection.









