

While certainly overhyped in terms of their immediate impact on businesses' everyday value from being in production, large language models (LLMs) do have many powerful new capabilities that can be built upon to enable previously impossible applications.
Many businesses will want to run out-of-the-box pre-trained large foundation models, and build their products upon them in the form of applications. This is largely an engineering challenge, with input from data science to be sure that the end-to-end dataflow and results make sense.
But others will want to generate value from their own intellectual property (IP) that was not available to these foundation models when they were trained. For example, to enable a doctor to ask an AI about patients' healthcare data. This will require a method to enable the foundation model to correctly utilize the extra information that the company's IP represents.
The field of LLMs continues to rapidly evolve, but a common way to get this information into the model is through fine-tuning. This requires altering the operation of the model in some way so that it has the appropriate effect. Some currently popular methods of fine-tuning include:
- Prompt engineering
- Retrieval-augmented generation (RAG)
- Parameter-efficient fine-tuning (PEFT)
- Fully-shared data-parallel (FSDP) tuning of the whole model
Prompt engineering involves giving better prompts to the model to make it more likely to give the desired result. This is sufficient for many tasks but does not supply the new IP that the company has.
RAG allows new information, e.g., documents, to be passed to the model. But your data still needs to be prepared and so the process is not off-the-shelf.
PEFT allows the original model to be used as-is, but with a new layer added to incorporate the new IP, i.e., the fine-tuning data. The computational requirements and output model are much smaller than the original, and therefore tractable on single, or a few GPUs, as opposed to thousands. The resulting model acts like the original, but fine-tuned.
FSDP is a variation on this, but the whole original model (or some subset of its layers) is tuned, which can give better results but is more computationally intensive.
The experience of fine-tuning on Paperspace by DigitalOcean

In this blogpost, we describe our in-practice experience of fine-tuning on Paperspace by DigitalOcean.
We focus on the LLaMA 2 model by Meta, which at the time of its release was the largest and best performing open source LLM. There have since been some slightly larger ones, such as Falcon 180B, but LLaMA 2 remains among the state-of-the-art, and importantly its online presence provides a viable end-to-end fine-tuning path that does not have to be a research project to get to work.
Licensing
Because fine-tuning begins with an existing model, if considering a production usage of the result, the immediate first question is licensing. Is the model even allowed to be used commercially?
For LLaMA 2, the answer is yes. This is one of its attributes that makes it significant.
While the exact license is Meta's own, and not one of the standard ones, it does clearly state that commercial use is allowed.

So we are good to go. Although, even with that good start, we still have to be careful, as will be seen below when we get to the data.
It's (relatively) easy to get going
One of the hardest parts of using deep learning and now LLMs is getting the compute power: GPUs. Then, if you have that, setting up the AI software stack so that everything works on those GPUs.
Fortunately, as we have seen many times before on this blog, Paperspace solves this.
GPU compute
While fine-tuning doesn't need 1000s of GPUs, it still needs some hefty compute to be able to load the model into GPU memory and perform the matrix operations. Similarly, a few 100 GB of storage is easily filled.
Paperspace provides A100 and H100 GPUs with 80GB memory in configurations of up to 8 per node, making 640GB total memory. Storage of up to 2 TB is also easily selected.
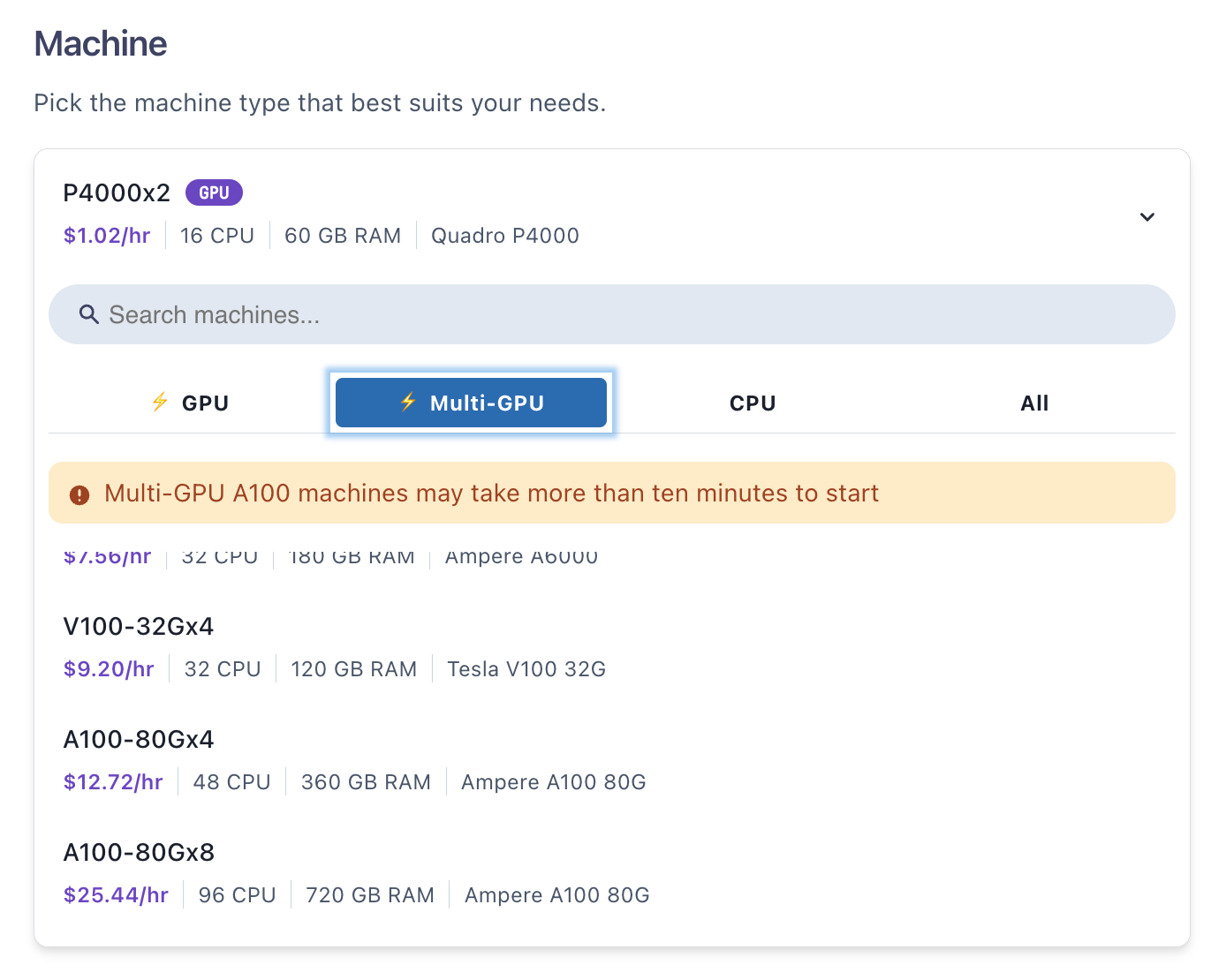
Here, we focus on fine-tuning the 7 billion parameter variant of LLaMA 2 (the variants are 7B, 13B, 70B, and the unreleased 34B), which can be done on a single GPU. We use A100-80Gx4 so that it runs faster.
ML-in-a-Box
ML-in-a-Box is our machine template designed to have the basic software stack to get going with AI on GPUs right away. So you create a machine and it already has bash, CUDA in a useable version, nvidia-smi, python, vi, git, Nvidia Docker, and so on.
The needed installs become just extra things that this particular use case needs, which we will see below.
Llama-recipes is a nice repository for fine-tuning
The other crucial ingredient that makes fine-tuning this particular LLM viable for real use cases and businesses is the GitHub repository that augments the original LLaMA 2 one, Llama 2 Fine-tuning / Inference Recipes and Examples (i.e., llama-recipes).
It contains working end-to-end dataflows that start with some tuning data, tune the base LLaMA 2 model with that data, run inference on the resulting model so that you can see the tuning worked, and shows an example of using an integration to do experiment tracking.
It shows how to add your own custom data, and also includes support for larger scale work if you need it: the 70B model, H100 GPUs, and multi-node machines via Slurm.
Various efficiencies are supported, in particular, the PEFT parameter-efficient fune-tuning mentioned above.
Basic run
Let's start with some basic runs to get an idea of what we are doing.
We will do this on Paperspace Notebooks, and then move on to the full fine-tuning on a cloud Machine.
Setting up
This is where the "relatively" qualifier in the statement above about ease of getting going comes into play. Some manual steps are required to gain access to the model. The requirement for various manual steps is typical in practice of end-to-end work with LLMs and their data.
While some other platforms may allow you to run some particular fine-tuning more quickly, this setup has you running it within a very generic cloud environment that can support a wide range of AI/ML use cases, including on your own custom data, models, and applications in production.
The Paperspace part of the setup is easy:
- Sign up, if you haven't already
- In the console, navigate to Gradient

- Create a Notebook following the usual procedure
- Use the latest PyTorch runtime (1.12 as of writing)
- Select an Ampere GPU type such as A6000 or A100
- In advanced settings, leave the workspace URL on the default https://github.com/gradient-ai/PyTorch . We will clone the llama-recipes repository below
The Notebook is good to go.
In the Notebook, open the terminal using the left-hand navigation bar, then install the llama-recipes code using its pip installer:
python3.9 -m pip install --upgrade pip
pip install --extra-index-url https://download.pytorch.org/whl/test/cu118 llama-recipesWe then clone the repository using
git clone https://github.com/facebookresearch/llama-recipesNow we need to access the model. This requires
- A Hugging Face (HF) account
- Request access to the download from Meta
The request needs to be for the same email as the HF account, and has to be manually approved by them, which in our case involved simply waiting for a few hours.
To see the (optional) experiment tracking requires a Weights & Biases (W&B) account, from which you can generate an API key via your user settings in the GUI to allow the Notebook to log the run to your W&B dashboard.
When your request to Meta to be access the LLaMA 2 model has been approved, you will then need Git Large File System (LFS) and an SSH key to be able to download it to the Notebook.
Git LFS is needed because LLM models are too large for Git (and indeed too large for Git LFS in many cases, being broken into parts). To set it up, in the Notebook terminal, do
curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | sudo bash
sudo apt-get install git-lfs
git-lfs installCreate a directory in which to place the model and navigate to it:
mkdir ~/llama-recipes/examples/models_hf
cd ~/llama-recipes/examples/models_hfTo get the SSH key, do
ssh-keygen -t ed25519 -C "<email>"where the email address is the one for your HF account. Use the default options of saving it to ~/.ssh/id_ed25519.pub, and no passphrase (unless you want a passphrase).
You can then add this key to your HF account under Settings -> SSH and GPG Keys.
Access to HF can be checked by doing
ssh -T git@hf.cowhich should return Hi <your HF username>, welcome to Hugging Face.
Then (finally!) you can download the model
git clone git@hf.co:meta-llama/Llama-2-7b
mv Llama-2-7b 7BThe 7 billion parameter model (LLaMA 2 7B) is 12.6GB in size, so it should download fairly quickly. As always in the cloud, keep in mind your use of storage, and billing expectations.
Running the Notebook
The llama-recipes repository contains a quick start Jupyter notebook, which can now be run. Navigate to the examples/ folder and open quickstart.ipynb.
You can do "Run All" on the notebook, but stepping through each cell is more instructive.
This is especially the case here, because, as supplied when we ran it, the notebook failed due to a ModuleNotFound error in its importing of the dataset utilities (as of repository commit 2e768b1). It was necessary for us to change the lines
from utils.dataset_utils import get_preprocessed_dataset
from configs.datasets import samsum_datasetto
from llama_recipes.utils.dataset_utils import get_preprocessed_dataset
from llama_recipes.configs.datasets import samsum_datasetto avoid the error. This may since have been corrected in the repository.
If all goes well, the notebook will then run and the example shows how to fine-tune the LLaMA 2 7B model to summarize text.
Experiment tracking with Weights & Biases
In the notebook, the optional profiler step is the one to see the Weights & Biases recording of your fine-tuning run.
With this enabled, you can see, for example, model loss versus training step within a given epoch.
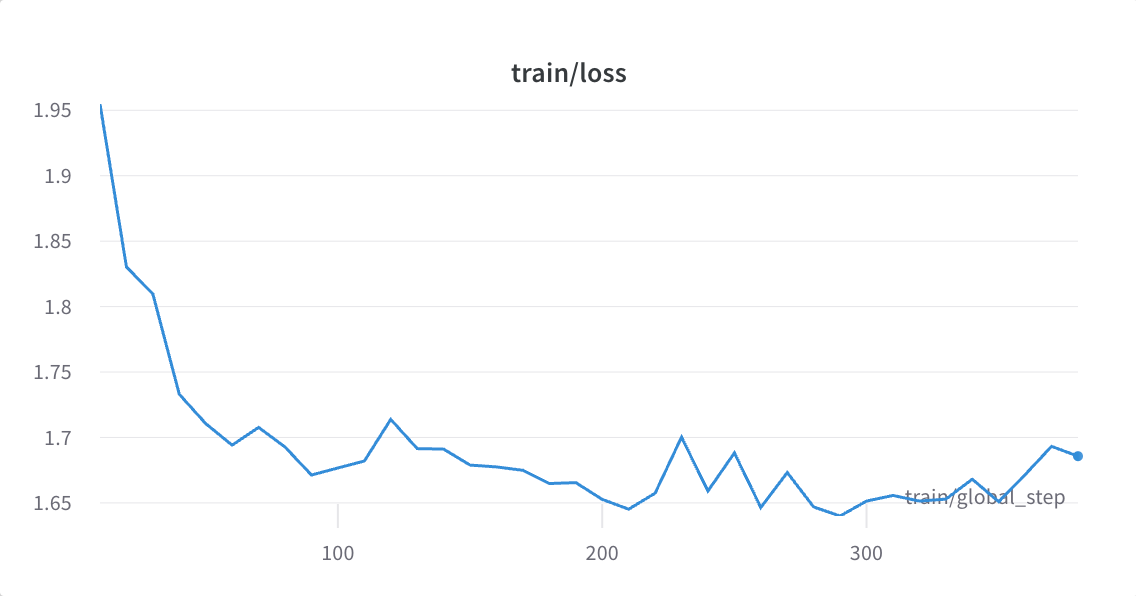
Other metrics, such as perplexity, are also relevant to LLM fine tuning, but (a) here you would have to add it to the default logged metrics to be able to view it on W&B, and (b) this is only a proxy for how well the model is doing in practice, and empirical human evaluation is still needed.
Inference
As with the later examples in this blogpost, we are able to then apply the fine-tuned model to some unseen data (i.e., run inference) to see if it is now better at the task we have fine-tuned it for, in this case summarizing text. The notebook shows that it is.
Full run
Now we have seen a basic quick-start run, let's move to a Paperspace Machine and do a full fine-tuning run.
Fortunately, many of the setup steps are similar to above, and either don't need to be redone (Paperspace account, LLaMA 2 model request, Hugging Face account), or just redone in the same way.
To start, in the console, navigate to Core, go the Machines tab, and select Create a Machine.
Under Select an OS template, choose ML-in-a-Box.
Under Machine, click the dropdown, then the Multi-GPU tab, scroll down, and select A100-80Gx4. If none are available, x2 or x8 should also work, but you will need to change the run command below.
For disk size, 250G should be fine.
You can leave the other options on default, but View advanced options allows you to set a machine name.
When the machine has started up, you can connect to it using the ssh command given on its detail page. With default settings, this is of the form ssh paperspace@<machine's dynamic IP>.
Run the terminal application on your machine (e.g., Utilities->Terminal, or iTerm2, on a Mac), SSH to the machine, and you will be at the machine's command line.
The remaining setup steps are similar to the ones we did above for the Notebook, with a few changes to accommodate this now being terminal-based as opposed to in the browser.
To start, if your terminal application supports it, run tmux so that the upcoming fine-tuning run doesn't get terminated if the connection is lost. In iTerm2 on the Mac, this is supported out-of-the-box.
tmux -CCThis opens a new terminal window, which can later be put in the background by closing it and choosing detach tmux session. To retrieve it, use tmux -CC attach from the original machine command line.
Then we need to install the llama-recipes repository as a package, adding a couple of extra steps to upgrade pip and setuptools. The second command installs the repository, and the third one installs the nightly version of PyTorch, needed at the time of writing to support the PEFT+FSDP methods used below in the fine-tuning.
python3.9 -m pip install --upgrade pip
pip install --extra-index-url https://download.pytorch.org/whl/test/cu118 llama-recipes
pip3 install --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/cu118
pip install -U setuptoolsPaperspace can shield the user somewhat from it by providing a base setup that works, but these issues are still likely to occur when satisfying the needs of a particular use case (which will not be a demo that someone got to work already).
When the installs are complete, we then restart the machine to avoid a GPU driver mismatch that would cause an attempt to view our GPU usage via nvidia-smi to fail. The easiest way is to click Restart in the machine detail page.
SSH back in, run tmux -CC again, and then clone the repository
git clone https://github.com/facebookresearch/llama-recipesA useful additional step here is to note which version of the repository you are using. The commit hash is a unique ID corresponding to each time it is updated, and helps with later reproducibility if needed.
cd ~/llama-recipes
git rev-parse mainIt will output a value with the 0-9 and a-f form of the one we obtained when running this example, 0b2fa40dba83fd625bc0f1119b0172c0575b5a57 . In the GitHub page itself, this would be abbreviated to 0b2fa40.
We can then install Git LFS as before
curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | sudo bash
sudo apt-get install git-lfs
git-lfs installMake some directories in which to store the fine-tuning runs
cd ~/llama-recipes
mkdir -p llama_2_finetuning/checkpoints/7B/samsum
mkdir llama_2_finetuning/checkpoints/7B/alpaca
mkdir llama_2_finetuning/checkpoints/7B/grammar
mkdir -p llama_2_finetuning/logs/7B/samsum
mkdir llama_2_finetuning/logs/7B/alpaca
mkdir llama_2_finetuning/logs/7B/grammar
mkdir llama_2_finetuning/modelsSet up an SSH key to HF as before
ssh-keygen -t ed25519 -C "<your HF email>"Add the key in ~/.ssh/id_ed25519.pub to your HF account settings.
Check it works
ssh -T git@hf.cowhere it should say Hi <your HF username>, welcome to Hugging Face.
And finally, download the model
cd ~/llama_2_finetuning/models
git clone git@hf.co:meta-llama/Llama-2-7b-hf
mv Llama-2-7b-hf 7BWe are now in principle ready to run the full fine-tuning. However, there is still the matter of the data itself.
You still have to prepare the data
Most demonstrations of deep learning, and now LLMs, conveniently have the data already prepared. This causes people to miss or underestimate the reality of working with your own data once you have moved beyond the demo: you can't just throw everything in and the model will sort it out, especially for fine-tuning.
The llama-recipes repository has data ready-prepared too, to some extent. But we will examine it, and fill the gaps, before proceeding with the fine-tuning.
Licensing (again)
As with the usage of the original model, there is again the question of licensing. While the LLaMA 2 model itself is licensed for commercial use, the repository reminds us that "Use of any of the datasets should be in compliance with the dataset's underlying licenses (including but not limited to non-commercial uses)".
The licenses of the datasets here indeed turn out to be for non-commercial use, being variations on Creative Commons NonCommercial 4.0. So to make your own model in production requires your own data, both for the reason that you probably want to use your own IP anyway, but also because of licensing.
Here, we can proceed with the supplied data, since this is a blogpost and not production use.
SamSUM, Alpaca, Grammar
The datasets supplied are real data, and give three use cases of fine-tuning the original base LLaMA 2 7B model.
- SamSUM: ~16,000 dialogs and summaries
- Stanford Alpaca: ~52,000 instruction-response pairs
- JFLEG Grammar: ~1500 sentence pairs with errors and corrected version
We will focus on SamSUM and mention Alpaca and Grammar briefly.
SamSUM, the default, is fully present in the repository and ready to go for both fine-tuning and inference.
In the HF dataset viewer, it looks like this
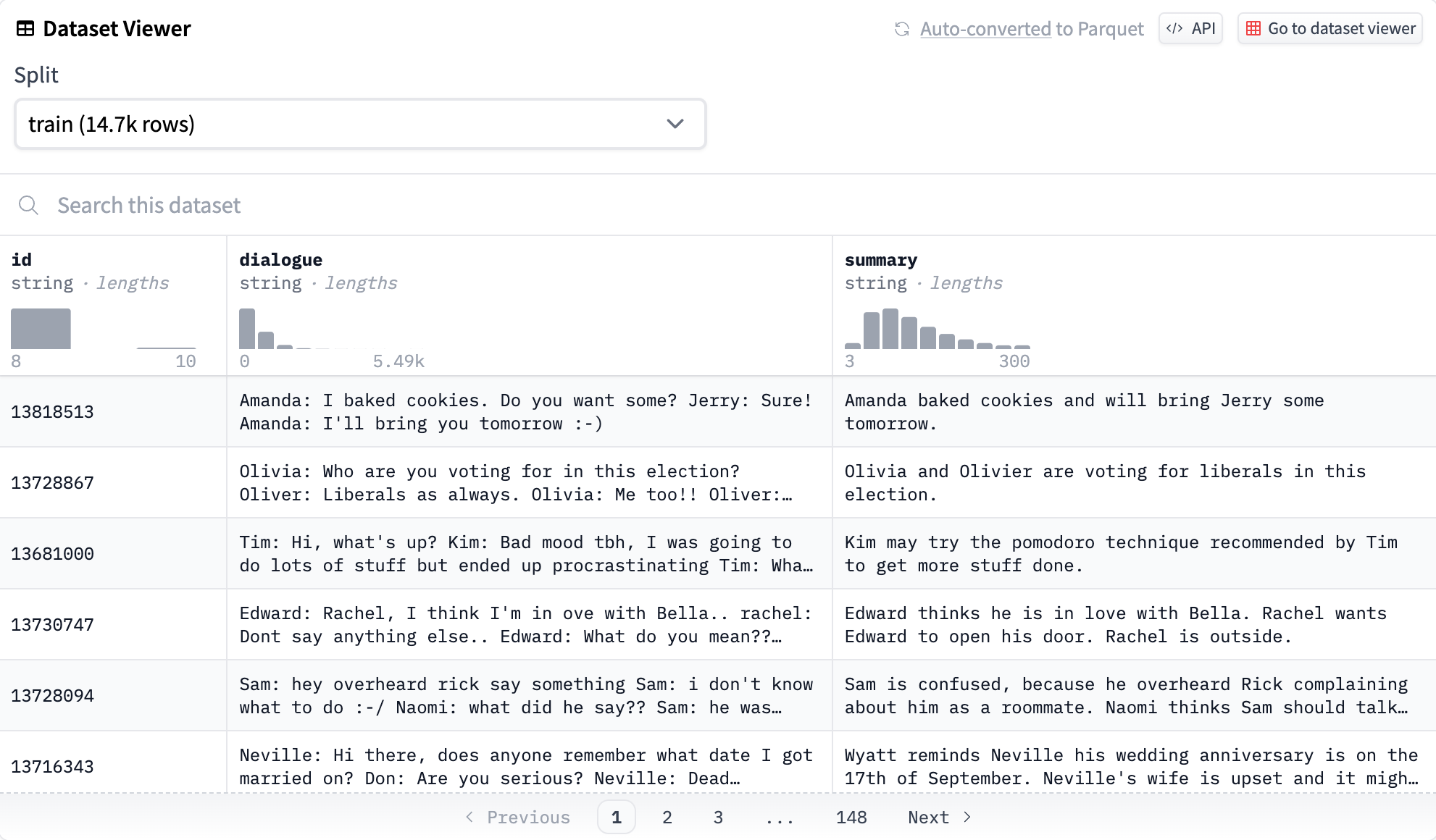
where we can see an ID column, a dialogue column containing strings of varying lengths, and a summary column. Most of the data (14.7k rows) is in the training set, and there are also validation (818 rows) and testing sets (819 rows) in the same format.
To fine-tune on the SamSUM data, we need to load the pre-trained model, create a new layer to add to it whose weights are trained with the new data, then output that trained layer such that it can then be deployed with the original model to perform inference. This is done in the next section, below.
The Alpaca and Grammar data need to be downloaded, and in Grammar's case, preprocessed. Inference data also needs to be created for both.
For Alpaca, this can be done by
wget -P src/llama_recipes/datasets https://raw.githubusercontent.com/tatsu-lab/stanford_alpaca/main/alpaca_data.jsonand inference data is in the simple form of a text file with a prompt, e.g., Give three tips for staying healthy.
For Grammar, there is an .ipynb Jupyter notebook that can be run to download and preprocess the data. While Paperspace has the option to remotely display the desktop of a Machine, here it is easier to run the notebook directly on the terminal as a Python script:
cd ~/llama-recipes/src/llama_recipes/datasets/grammar_dataset
jupyter nbconvert --to script grammar_dataset_process.ipynb
python grammar_dataset_process.pyYour own data / custom
A nice part of the llama-recipes repository is it then shows you how to use your own data, as a custom dataset. We don't run this here, but the idea is to help in formatting your own data correctly to pass to the LLaMA 2 model for fine-tuning.
Fine-tuning works
Now the data are correctly formatted and set up, we are ready to pass it to the fine-tuning.
Assuming everything is working correctly, the only other hurdle to clear is to make sure all the model and other ancillary settings are correct. A typical LLM fine-tuning run has a lot of these, as can be see by the following fragments from the various settings files. Often settings are done via YAML, but this repository does them via Python .py.
datasets.py describes the particular fine-tuning dataset to be used, which here is SamSUM:
@dataclass
class samsum_dataset:
dataset: str = "samsum_dataset"
train_split: str = "train"
test_split: str = "validation"
input_length: int = 2048peft.py describes the settings for the parameter-efficient fine-tuning that we are doing, i.e., tuning a single extra layer to add to the base model, and using the default low-rank adaptation (LoRA) method of doing this:
@dataclass
class lora_config:
r: int=8
lora_alpha: int=32
target_modules: List[str] = field(default_factory=lambda: ["q_proj", "v_proj"])
bias= "none"
task_type: str= "CAUSAL_LM"
lora_dropout: float=0.05
inference_mode: bool = FalseThen training.py describes the settings of the model and its training. We show this in full so you get a sense of what can be changed:
@dataclass
class train_config:
model_name: str="PATH/to/LLAMA/7B"
enable_fsdp: bool=False
low_cpu_fsdp: bool=False
run_validation: bool=True
batch_size_training: int=4
gradient_accumulation_steps: int=1
num_epochs: int=3
num_workers_dataloader: int=1
lr: float=1e-4
weight_decay: float=0.0
gamma: float= 0.85
seed: int=42
use_fp16: bool=False
mixed_precision: bool=True
val_batch_size: int=1
dataset = "samsum_dataset"
peft_method: str = "lora" # None , llama_adapter, prefix
use_peft: bool=False
output_dir: str = "PATH/to/save/PEFT/model"
freeze_layers: bool = False
num_freeze_layers: int = 1
quantization: bool = False
one_gpu: bool = False
save_model: bool = True
dist_checkpoint_root_folder: str="PATH/to/save/FSDP/model" # will be used if using FSDP
dist_checkpoint_folder: str="fine-tuned" # will be used if using FSDP
save_optimizer: bool=False # will be used if using FSDP
use_fast_kernels: bool = False # Enable using SDPA from PyTroch Accelerated Transformers, make use Flash Attention and Xformer memory-efficient kernelsWe generally found it practical to leave most values on the defaults given here, and change any needed via passing them as arguments to the fine-tuning command.
When tuning on multiple GPUs, there is a fourth settings file, fsdp.py that describes the implementation of fully-sharded data parallelism (FSDP), a method of saving GPUs resources by providing both data parallelism and sharding the model states across the GPUs. This can be seen, along with the other repository configuration files, in their configs directory.
Beyond these settings, there are also various generic arguments that can be passed to the libraries the fine-tuning is run on (Hugging Face Transformers, PyTorch, CUDA, etc.), but here they are OK on the default values.
Run it
To run fine-tuning of LLaMA 2 on the SamSUM dataset on our A100-80Gx4 machine, the command is
cd ~/llama-recipes
time torchrun \
--nnodes 1 \
--nproc_per_node 4 \
examples/finetuning.py \
--enable_fsdp \
--model_name /home/paperspace/llama_2_finetuning/models/7B \
--use_peft \
--peft_method lora \
--dataset samsum_dataset \
--output_dir /home/paperspace/llama_2_finetuning/checkpoints/7B/samsum \
2>&1 | tee /home/paperspace/llama_2_finetuning/logs/7B/samsum/fine_tuning.logHere, we are using PyTorch's distributed computing command torchrun, prefixed by the bash command time to get the wallclock runtime, and appended with tee to capture the terminal output (stdout and stderr) to a log file. PEFT, FSDP, and LoRA are enabled, we are on one node, and there are 4 processes (4 GPUs).
We found that the fine-tuning completed in under 2 hours, and changing the training batch size and adding the repository's --use_fast_kernels option to include Flash Attention didn't make much difference.
The Alpaca and Grammar datasets can be similarly run by changing the --dataset argument to the command. Because these datasets are already defined in datasets.py, the other settings can remain the same.
Run inference too
One your model is fine-tuned, you want to be sure that it is working correctly and producing improved output compared to the base model. While it is possible to view various quantitative metrics such as loss or perplexity, for LLMs that produce text output there is no substitute for qualitative human evaluation of typical outputs.
For this tuning, we see the same result as in the repository's example, where the base LLaMA 2 before the fine-tuning does not summarize the text, but the fine-tuned model does.
Before
The model just repeats the dialog.
After
Summarize this dialog:
A: Hi Tom, are you busy tomorrow’s afternoon?
B: I’m pretty sure I am. What’s up?
A: Can you go with me to the animal shelter?.
B: What do you want to do?
A: I want to get a puppy for my son.
B: That will make him so happy.
A: Yeah, we’ve discussed it many times. I think he’s ready now.
B: That’s good. Raising a dog is a tough issue. Like having a baby ;-)
A: I'll get him one of those little dogs.
B: One that won't grow up too big;-)
A: And eat too much;-))
B: Do you know which one he would like?
A: Oh, yes, I took him there last Monday. He showed me one that he really liked.
B: I bet you had to drag him away.
A: He wanted to take it home right away ;-).
B: I wonder what he'll name it.
A: He said he’d name it after his dead hamster – Lemmy - he's a great Motorhead fan :-)))
---
Summary:
A wants to get a puppy for his son. He took him to the animal shelter last Monday. He showed him one that he really liked. A will name it after his dead hamster - Lemmy.
So we are good to go! Our model can now summarize inputs supplied to it.
Models can be deployed as apps
So that's great, we have a working model. The last step is to deploy it and add an interface, since your users probably don't want to send inference.py commands from their terminal.
Fortunately, Paperspace + Digital Ocean can help here too. For Deployments, Paperspace makes it easy to put your model into production in the cloud. Models can be instantiated as API endpoints, which can then be called by applications that use their output.
This works for pre-existing models too.
Conclusions
While various products online have setups that get to a fine-tuned model with fewer steps than shown here, the result here is a generic setup that enables you to tune any model with any data, and hence solve your business problem.
The number of steps is then a realistic example of how this generic approach goes in practice, so that as a user you have a better idea of how it's likely to go.
Run your fine-tuning on Paperspace by Digital Ocean
Some useful links to put LLM fine-tuning into practice on Paperspace:
- Sign up for Paperspace by Digital Ocean
- Documentation: Notebooks, Machines, Deployments
- Paperspace Blog












{kind=link}