
Diffusion-based text-to-image models have made great strides at synthesizing photorealistic content from text prompts, with implications for many different areas of study, including but not limited to: content creation; image editing and in-painting; super-resolution; video synthesis; and 3D assets production. However, these models need a lot of computing power, hence high-end GPU-equipped inference platforms on the cloud are usually required. The transmission of personal photos, videos, and prompts to a third-party provider, not only incurs considerable costs, but also poses serious privacy problems.
The inference of text-to-image diffusion models has been optimized for speed on mobile devices using techniques including quantization and GPU-aware optimization. Unfortunately, these techniques have not yet reduced latency to a level that facilitates an excellent user experience. In addition, no previous research has quantitatively explored the generation quality of on-device models.
In this paper, the authors provide the first text-to-image diffusion model that can generate an image in less than 2 seconds on mobile devices. The sluggish inference speed of the UNet is being addressed, as is the need for so many denoising processes.
Latent diffusion model/ Stable diffusion model
Diffusion models are complex and computationally intensive, which has sparked research into ways to optimize their efficiency, such as enhancing the sampling process and looking into on-device solutions.
The Latent Diffusion Model (LDM) is a diffusion model that can be used to convert text to an image. High-quality images are generated in response to textual prompts, making this a potent content creation tool.
The Stable Diffusion model, specifically version 1. 5, is used as the starting point in this study. It's a popular model for generating images from text prompts. The reason it's so popular is because it can make some really impressive, high-quality images. But there's a catch - you need some serious computing power to run it smoothly. That is because of how the model works. It goes through lots of repetitive steps to refine the image which takes up a ton of processing power. The model consists of a Text Encoder, UNet, and VAE Decoder. It also has a crazy amount of parameters, so it's super computationally intensive to run. This means you realistically need an expensive GPU to use it. Trying to run it on something like a phone would be too slow to be usable.
Architecture Optimizations
The authors introduce a new approach for optimizing the architecture of the UNet model, which is a major limitation of the conditional diffusion model. They identify redundant parts of the original model and reduce the image decoder's computation through data distillation.
They propose a more efficient UNet by breaking down the networks at a granular level, providing the basis for redesigning and optimizing the architecture. Comparing latency between Stable Diffusion v1. 5 and their proposed efficient diffusion models (UNet and Image Decoder) on an iPhone 14 Pro shows that, Stable Diffusion v1. 5 has higher latency and more parameters versus their models.
The authors also present an architecture optimization algorithm. This algorithm ensures that the optimized UNet model converges and meets the latency objective. The algorithm performs robust training and evaluates each block in the model. If architecture evolution is needed at some point, it assesses the change in CLIP score for each block to guide the process.
They also introduce a training augmentation to make the network robust to architecture permutations, enabling an accurate assessment of each block and a stable architectural evolution.
Algorithm for Optimizing UNet Architecture: Some explanations
The algorithm requires UNet architecture, a validation set (Dval), and a table for lookup latency(T) with Cross-Attention and ResNet timings. The goal is getting the UNet to converge while meeting the latency target S.

- It uses robust training to optimize the architecture. If this iteration includes architecture evolution, the blocks get evaluated. For each block[i j], it calculates the change in score (∆CLIP) and latency (∆Latency) using the current architecture (ˆεθ), A-block[i,j] Dval or T.
- It sorts the actions by ∆CLIP and ∆Latency and then, it evolves the architecture to try to get the right latency T. If T is not satisfied, it finds the minimum values of ∆CLIP and ∆Latency and evolves the architecture to get { ˆA-}.
- If T is satisfied, it takes the maximum of ∆CLIP and ∆Latency and copies it to get { ˆA+}. Finally, it evolves the architecture using { ˆA} to update ˆεθ.
Step distillation
Step distillation sounds like a fancy technique used by the authors to improve the learning objective during the training of the text-to-image diffusion model. It involves distilling knowledge from a teacher model to a student model in a step-wise manner.
The authors compare a couple of different flavors of step distillation: progressive distillation and direct distillation. Progressive distillation has the teacher model spoon-feeding knowledge to the student model in multiple steps, while direct distillation just does it in a single step. Turns out direct distillation whips progressive distillation's behind in terms of both the FID (Fréchet Inception Distance) doodad and the CLIP score.
Overview of distillation pipeline
The term "Distillation Pipeline" refers to a process of compressing and optimizing a large and complex machine learning model into a smaller and simpler one.
- Step Distillation on SD-v1.5: The first step is to perform step distillation on SD-v1.5, which is a model used as a teacher model. This step aims to obtain a UNet model with 16 steps that matches the performance of the 50-step model.
- Step Distillation on Efficient UNet: Once we've got that 16-step UNet, we use it as the new teacher to train up an efficient 8-step UNet. So, we go from the 50-step model to a medium 16-step one and finally distill it down to a simple 8-step model. The key is using those intermediate models as teachers - their knowledge gets distilled down into the smaller versions.
- CFG Guided Distillation: The paper also introduces a CFG (Context-Free Grammar)-aware step distillation approach, which further improves the performance of the student model. This approach throws in some additional regularization including losses from v-prediction and classifier-free guidance. The CFG-aware step distillation consistently boosts the CLIP score of the student model with different configurations.
Ablation Analysis
The Figure below shows the results of ablation studies in step distillation, which is a process of training a smaller neural network (student model) to mimic the behavior of a larger neural network (teacher model).
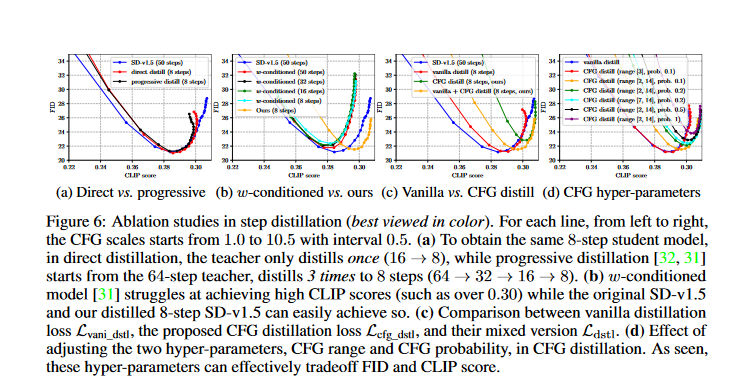
- Each line in the figure shows a different way of setting up the distillation process. The settings for the hyper-parameters start at 1. 0 and go up to 10. 5, increasing by 0. 5 each time.
- Part (a) compares two methods for getting to 8-step student model: direct distillation versus progressive distillation. The results show that progressive distillation works better.
- Part (b) looks at how well a w-conditioned model does, compared to the original SD-v1. 5 and the distilled 8-step SD-v1. 5 models at getting high CLIP scores. The w-conditioned model struggles to achieve high CLIP scores, while the other two models can easily achieve them.
- Part(c) compares the performance of vanilla distillation loss (Lvani_dstl) versus the proposed CFG distillation loss (Lcfg_dstl) and their mix version(Ldstl). The results show that the mixed version achieves a better tradeoff between FID and CLIP score.
- Part (d) shows how to optimize the two settings for CFG distillation - CFG range and CFG probability . It looks like higher CFG probability and bigger CFG range increases the CFG loss's impact, that lead to better CLIP score but makes the FID worse. So these settings give a good way to balance FID and CLIP score during training.
Applications in the industry
Real-time image generation:Real-time image generation is a big deal these days. That new SnapFusion diffusion model can whip up pretty images from just a few words of text in two seconds flat. It's all optimized to work that fast on mobile devices. Could be a game changing for social media, chatbots, virtual assistants - anything that needs quick custom images on the fly.
On-device solutions: The research explores on-device image generation, which is particularly useful in scenarios where internet connectivity is limited or privacy concerns restrict cloud-based image generation. This makes the proposed text-to-image diffusion model applicable in industries that require offline or privacy-preserving image synthesis.
Mobile applications and improved user experience: Beyond social media and all that, there's a ton of industries and applications that can benefit from fast on-device image generation: advertising, e-commerce, entertainment, augmented reality, virtual reality - the possibilities are endless. Any app that recommends personalized content or tells interactive stories could be leveled up with this tech.
Some potential limitations
- The paper talks about a new way to run text-to-image diffusion models on mobile devices, so they take less than 2 seconds. That's cool, but, we are not sure how well it would perform on different different types of mobile devices, especially older or less powerful ones.
- It seems that the authors only conducted experiments on the MS-COCO dataset. Therefore, the robustness and generalizability of the model to other datasets or real-world scenarios are unknown.
- The authors state that the model gets better FID and CLIP scores than Stable Diffusion 1. 5 with fewer denoising steps. But how does it stack up against other models out there? It would be good to compare it to others models in different situations.
- One thing they don't mention is privacy when running this on mobiles devices. They state that, it avoids privacy issues with cloud computing, but don't explain how they managed or protected user data in their proposed model. That's an important thing to address.
Some steps to apply the paper
To apply the SnapFusion text-to-image diffusion model, you can follow these steps:
- Install the necessary dependencies and libraries for text-to-image synthesis, such as PyTorch and torchvision.
- To prepare your text prompts or captions for further analysis, it is necessary to perform preprocessing steps. These steps include tokenizing the text, which means breaking it down into individual words or subwords, and then translating them into numerical representations. This may be achieved by techniques like word embeddings, which map words to dense vectors in a continuous space, or one-hot encodings, which represent words as binary vectors.
- Load the pre-trained SnapFusion model weights and architecture, which can be obtained from the authors.
- Use the text prompts to feed into the SnapFusion model's input layer and start generating images through the text-to-image diffusion process. The model will generate images that correspond to the provided text prompts in mere seconds.
- Apply any necessary post-processing tasks on the generated images, like resizing or applying extra image refinement methods if needed.
- Display or save the generated images for further analysis or use in your application.
Conclusion
The authors did a great job showing a new way to run text-to-image diffusion models on moble devices in under two seconds. That's crazy fast, considering how much number crunching those models usually need and how slow they normally are. They came up with an efficient UNet architecture by identifying redundancies in the original model and simplifying the computation of the image decoder using data distillation. They also improved the step distillation process by trying new training strategies and adding regularization from classifier-free guidance.
The authors tested the crap out of their model on the MS-COCO dataset. The model with only 8 denoising steps performed better on FID and CLIP scores compared to the Stable Diffusion v1. 5 model with 50 steps. Finally, they argue that, their work makes creating content more accessible to users by making powerful text-to-image diffusion models work on normal mobile devices without requiring expensive GPUs or cloud services. This also reduces privacy issues associated with sending user data to outside companies.
Reference











