
When choosing a platform, instance type, or GPU for conducting machine learning, it is important to optimize your hardware based on the situation at hand. Primarily, most of those reading this are concerned with three factors: power, accessibility, and cost.
Getting an adequately powerful GPU is essential for completing many tasks involving big data, machine learning, and deep learning. Having consistent and easy access to those powerful GPU's ensures that users can complete the tasks they need the GPUs for. Cost is the balance all users must consider when they plan out a task requiring high computational expense and ease of access.
This is also true on Gradient. By giving our free tier users access to the Quadro M4000 at no cost, many users can get the power they need. Our Pro plan users, who pay 8 USD per month, have even better benefits: instances with RTX4000, P4000, RTX5000, and P5000 GPUs are available to all Pro plan users at no additional cost. Finally, users can access even more powerful GPU instances like those with an A100 at both the cost of the subscription and an additional per hour fee (in this case $3.09/hr).
This article was created to serve as a guide for users seeking to best strike that balance. Use the insights and facts about the available machines below to help you create an informed decision about what instance you need for your Gradient project.
Quick Facts:
Above is a breakdown of the previously listed GPUs available for free users, as well as the benchmark data for the most powerful single GPU available, the A100.
As you can see by comparing the RAM and number of CUDA cores for each unit, the underlying architecture affects the overall speed of the processing for each GPU. The most obvious place to see this is in the CUDA core count and memory bandwidth: the RTX series GPUs have significantly higher numbers of CUDA cores that enable faster memory bandwidths at the same level of memory as the corresponding Pascal series GPU.
Now that we have an idea as to how the hardware available to us varies, let's look at how they perform in practice on a series of benchmark tests
Bring this project to life
Benchmark Tests
The Test itself
tf-metal-experiments is a GitHub repo created by user tlkh designed to facilitate their comparison of the Apple M1 series chip's performance against conventional GPU's for machine learning. The tests themselves are designed to assess the time it takes for a TensorFlow CNN or HuggingFace Transformer model to successfully train, and the results are output as a measure of the number of samples that can be processed per second.
Those seeking to make use of this test need to ensure that the environment under which they are doing about the testing has both TensorFlow and HuggingFace's Transformers library installed. These will be used to perform the baseline tests.
For this benchmarking example below, I am going to use the same 4 testing model frameworks as the original author: ResNet50, MobileNetv2, DistilBert, and BertLarge. Due to the relatively weak performance of the weakest GPU we are testing, the Quadro M4000, we must restrict the batch size for all testing so that each machine is capable of completing each benchmark without running out of memory.
All tests were completed in succession of one another, and all free and free for Pro instance types were analyzed in addition to the most powerful single GPU available, the A100.
Note: These results are my own, and were carried out using Gradient. If you seek to replicate these results, follow the guide at the bottom of this article.
To see what other GPU types we have available at Paperspace, check out the guide in our Docs page.
The Results
As expected, the results for the training rate varied across each type of instance. The worst performing was unsurprisingly the M4000, the oldest and weakest GPU in our listing. As the lowest performer in each category, we can also use it as a good point of comparison. For example, the A100 performs ~16 times faster than the M4000 on both of the two BERT transformer benchmarks despite only having 5 times the memory available. This is largely a result of advances in the underlying architecture from generation to generation and the subsequent increase in CUDA cores.
Of the GPUs available for no additional cost to Pro tier users, the RTX5000 was the clear winner in each category. Despite the significant difference in CUDA cores and RAM, the RTX5000 even performed comparably to the A100 on the MobileNetV2 benchmark. This indicates that our pro tier users can, in certain scenarios with particularly light models like MobileNetv2, can get nearly the same level of power as an A100 at no cost besides their subscription to Paperspace. This makes some intuitive sense; the RTX GPUs are based on the Turing microarchitecture, the direct predecessor to Ampere.
All in all, the RTX5000 performs extremely well for its price point, and I recommend our Pro tier users use this unit whenever possible.
Replicate these benchmarks
While the metrics above offer good insights about what GPU a user should select for Gradient, it is always better to test these results ourselves. If you would like to recreate the results of the tests above, please use the following guide.
First, log in to Paperspace Gradient and create a notebook. For your runtime, select TensorFlow.
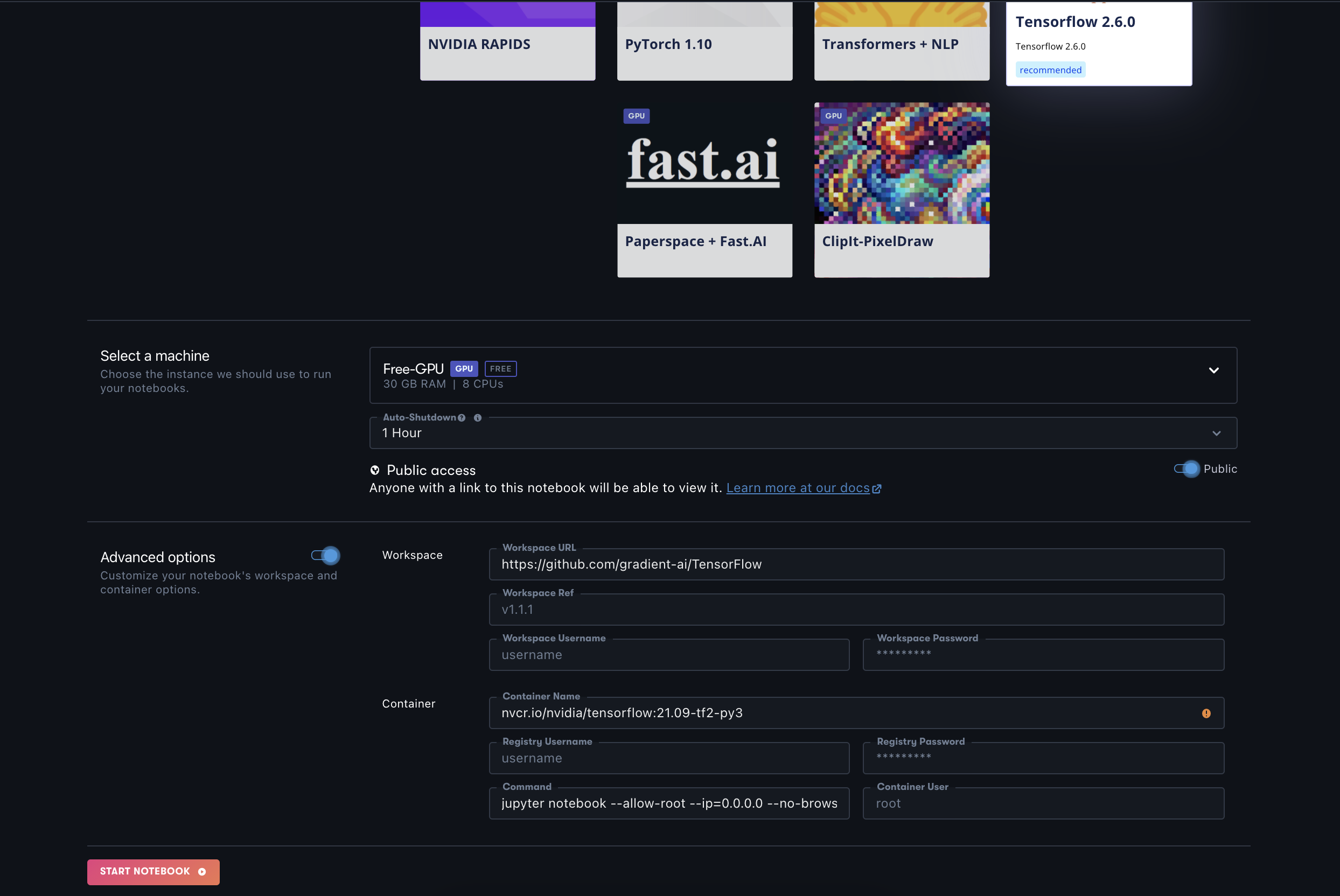
Second, select the instance you are interested in testing. Seeing as the results above are available for comparison, I suggest you start off with one of those listed like the "Free GPU" (M4000).
Third, toggle the advanced options at the bottom of the page, and paste "https://github.com/tlkh/tf-metal-experiments" as the workspace URL.
Fourth, launch the notebook.
Fifth, when the instance is running, create a new iPython notebook in your Gradient Notebook. Note, the following steps are being conducted in the ipynb cells themselves for ease of recording the scores for the benchmarks, but they can also be run in the terminal directly.
Sixth, in a new cell paste the following:
# run each time you make a new instance
!python3 -m pip install --upgrade regex --no-use-pep517
!pip install transformers ipywidgetsFinally, select which test you would like to run and paste it into a cell to run. If you would like to exactly recreate my tests, run the following in individual cells:
!python tf-metal-experiments/train_benchmark.py --type cnn --model resnet50 --bs 32
!python tf-metal-experiments/train_benchmark.py --type cnn --model mobilenetv2 --bs 32
!python tf-metal-experiments/train_benchmark.py --type transformer --model distilbert-base-uncased --bs 8
!python tf-metal-experiments/train_benchmark.py --type transformer --model bert-large-uncased --bs 4Your results will output like so in samples/second:
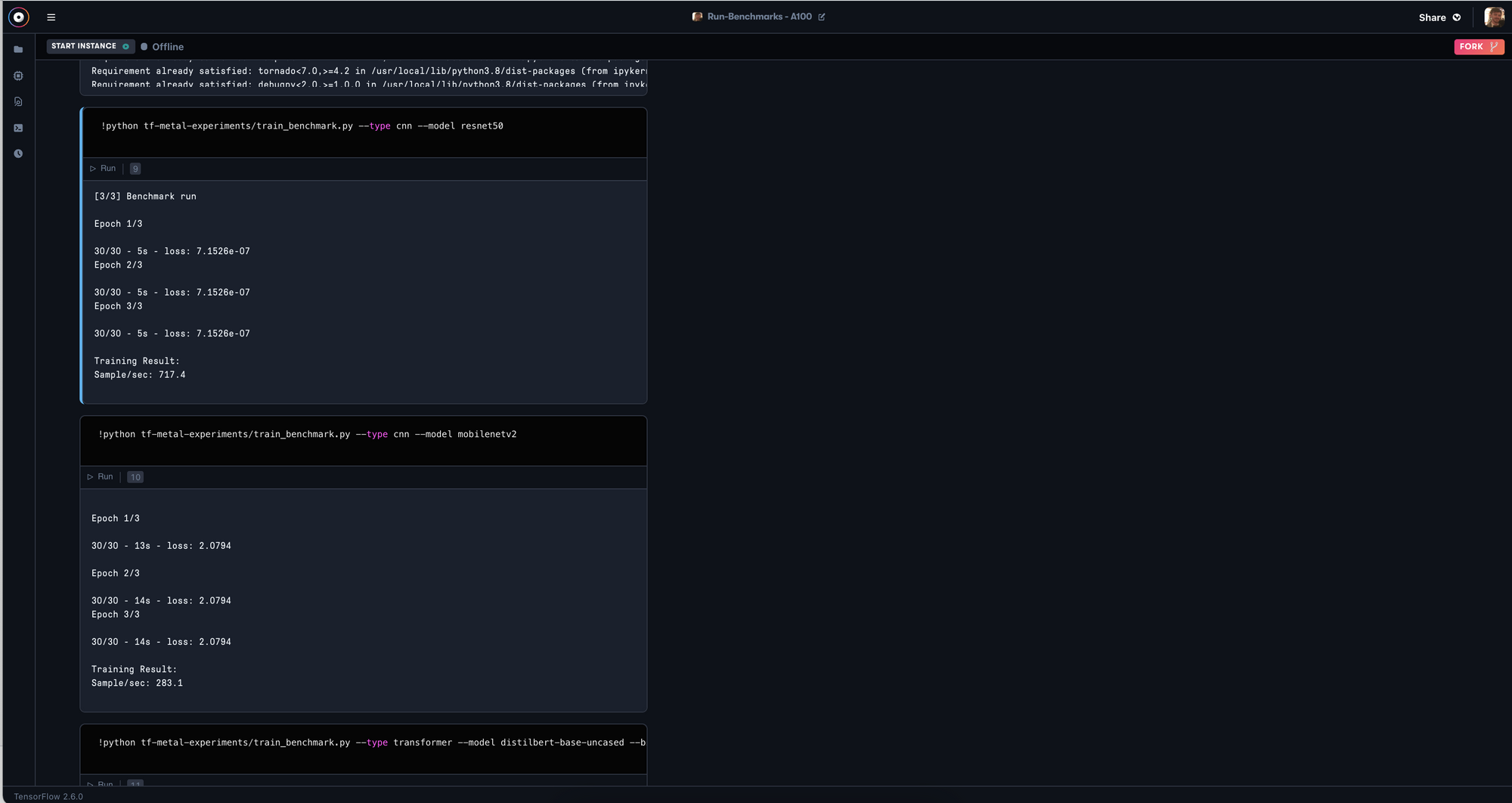
Conclusion
Even the GPUs available for free on Gradient are sufficiently powerful to run even large and complex training for ML/DL such as that required for the BertLarge architecture. The cost of running such an expensive training process is obvious with such a task: the M4000 will take nearly 16 times as long as the A100 to train, but the training was nonetheless completed.
This benchmarking exercise was created to show how much of an advantage it is to have access to faster GPUs, not by showing that they are required for suitably complex tasks, but instead by showing just how much faster the right hardware can make tackling a computationally costly assignment. I encourage readers of this article to therefore consider the value of their time compared to the cost of the GPU. An hour spent waiting for a model to train on your GPU is far less valuable than an hour validating and testing that model.











