

Bring this project to life
We have been living in a Golden Age of text-to-image generation for the last few years. Since the initial release of Stable Diffusion to the open source community, the capability of the technology has exploded as it has been integrated in a wider and wider variety of pipelines to take advantage of the innovative, computer vision model. From ControlNets to LoRAs to Gaussian Splatting to instantaneous style capture, it's evident that we this innovation is only going to continue to explode in scope.
In this article, we are going to look at the exciting new project "Improving Diffusion Models for Authentic Virtual Try-on" or IDM-VTON. This project is one of the latest and greatest Stable Diffusion based pipelines to create a real world utility for the creative model: trying on outfits. With the incredible pipeline, its now possible to adorn just about any human figure with nearly any piece of clothing imaginable. In the near future, we can expect to see this technology on retail websites everywhere as shopping is evolved by the incredible AI.
Going a bit further, after we introduce the pipeline in broad strokes, we also want to introduce a novel improvement we have made to the pipeline by adding Grounded Segment Anything to the masking pipeline. Follow along to the end of the article for the demo explanation, along with links to run the application in a Paperspace Notebook.
What is IDM-VTON?
At its core, IDM-VTON is a pipeline for virtually clothing a figure in a garment using two images. In their own words, the virtual try-on "renders an image of a person wearing a curated garment, given a pair of images depicting the person and the garment, respectively" (Source).
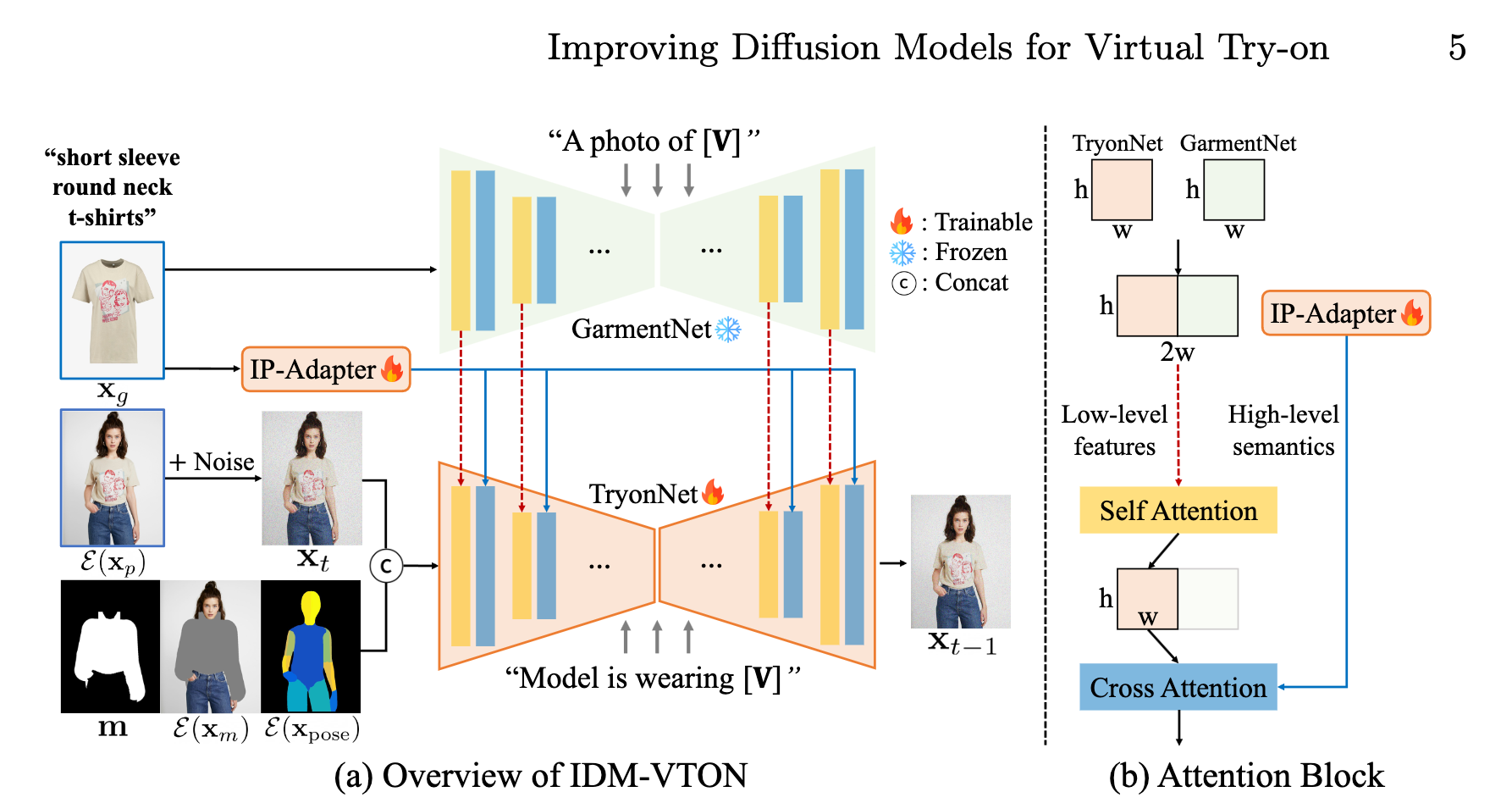
We can see the model architecture in the figure above. It consists of a parallel pipeline of two customized Diffusion UNet's, TyonNet and GarmentNet, and an Image Prompt Adapter (IP-Adapter) module. The TryonNet is the main UNet that processes the person image. Meanwhile, the IP-Adapter encodes the high-level semantics of the garment image, to be used later with the TryonNet. Also simultaneously, the GarmentNet encodes the low-level features of the garment image.
As the input for the TryonNet UNet, the model concatenates the noised latents for the human model with a mask extracted of their garments and a DensePose representation. The TryonNet uses the now concatenated latents with the user provided, detailed garment caption [V] as the input for the TryonNet. In parallel, the GarmentNet takes the detailed caption alone as its input.
To achieve the final output, halfway through the diffusion steps in TryonNet, the pipeline concatenates the intermediate features of TryonNet and GarmentNet to pass them to the self-attention layer. The final output is then received after fusing it the features from the text encoder and IP-adapter with the cross-attention layer.
What does IDM-VTON let us do?
In short, IDM-VTON let's us virtually try on clothes. This process is incredibly robust and versatile, and is able to essentially apply any upper-torso clothing (shirts, blouse, etc.) to any figure. Thanks to the intricate pipeline we described above, the original pose and general features of the input subject are retained underneath the new clothing. While this process is still quite slow thanks to the computational requirements of diffusion modeling, this still offers and impressive alternative to physically trying clothes on. We can expect to see this technology proliferate in retail culture as the run cost goes down over time.
Improving IDM-VTON
In this demo, we want to showcase some small improvements we have added to the IDM-VTON Gradio application. Specifically, we have extended the model's ability to clothe the actors beyond the upper body to the entire body, barring shoes and hats.
To make this possible, we have integrated IDM-VTON with the incredible Grounded Segment Anything project. This project uses GroundingDINO with Segment Anything to make it possible to segment, mask, and detect anything in any image using just text prompts.
In practice, Grounded Segment Anything let's us automatically clothe people's lower bodies by extending the coverage of the automatic-masking to all clothing on the body. The original masking method used in IDM-VTON just masks the upper body, and is fairly lossy with regard to how closely it matches the outline of the figure. Grounded Segment Anything masking is significantly higher fidelity and accurate to the body.
In the demo, we have added Grounded Segment Anything to work with the original masking method. Use the Grounded Segment Anything toggle at the bottom left of the application to turn it on when running the demo.
IDM-VTON Demo
Bring this project to life
To run the IDM-VTON Demo with our Grounded Segment Anything updates, all we need to do is click the link here or with the Run on Paperspace buttons above or at the top of the article. Once you have clicked the link, start the machine to begin the demo. This is defaulted to run on an A100-80G GPU, but you can manually change the Machine code to any of the other available GPU or CPU machines.
Setup
Once your machine is spun up, we can begin setting up the environment. First, copy and paste each line individually from the following cell into your terminal. This is necessary to set the environment variables.
export AM_I_DOCKER=False
export BUILD_WITH_CUDA=True
export CUDA_HOME=/usr/local/cuda-11.6/Afterwards, we can copy the entire following code block, and paste into the terminal. This will install all the needed libraries for this application to run, and download some of the necessary checkpoints.
## Install packages
pip uninstall -y jax jaxlib tensorflow
git clone https://github.com/IDEA-Research/Grounded-Segment-Anything
cp -r Grounded-Segment-Anything/segment_anything ./
cp -r Grounded-Segment-Anything/GroundingDino ./
python -m pip install -e segment_anything
pip install --no-build-isolation -e GroundingDINO
pip install -r requirements.txt
## Get models
wget https://huggingface.co/spaces/abhishek/StableSAM/resolve/main/sam_vit_h_4b8939.pth
wget -qq -O ckpt/densepose/model_final_162be9.pkl https://huggingface.co/spaces/yisol/IDM-VTON/resolve/main/ckpt/densepose/model_final_162be9.pkl
wget -qq -O ckpt/humanparsing/parsing_atr.onnx https://huggingface.co/spaces/yisol/IDM-VTON/resolve/main/ckpt/humanparsing/parsing_atr.onnx
wget -qq -O ckpt/humanparsing/parsing_lip.onnx https://huggingface.co/spaces/yisol/IDM-VTON/resolve/main/ckpt/humanparsing/parsing_lip.onnx
wget -O ckpt/openpose/ckpts/body_pose_model.pth https://huggingface.co/spaces/yisol/IDM-VTON/resolve/main/ckpt/openpose/ckpts/body_pose_model.pthOnce these have finish running, we can begin running the application.
IDM-VTON Application demo
Running the demo can be done using the following call in either a code cell or the same terminal we have been using. The code cell in the notebook is filled in for us already, so we can run it to continue.
!python app.py Click the shared Gradio link to open the application in a web page. From here, we can now upload our garment and human figure images to the page to run IDM-VTON! One thing to note is that we have changed the default settings a bit from the original release, notably lowering the inference steps and adding the options for Grounded Segment Anything and to look for additional locations on the body to draw on. Grounded Segment Anything will extend the capability of the model to the entire body of the subject, and allow us to dress them in a wider variety of clothing. Here is an example we made using the sample images provided by the original demo and, in an effort to find an absurd outfit choice, a clown costume:

Be sure to try it out on a wide variety of poses and bodytypes! It's incredibly versatile.
Closing thoughts
The massive potential for IDM-VTON is immediately apparent. The days where we can virtually try on any outfit before purchase is rapidly approaching, and this technology represents a notable step towards that development. We look forward to seeing more work done on similar projects going forward!











