
In this tutorial we’ll cover encoder-decoder sequence-to-sequence (seq2seq) RNNs: how they work, the network architecture, their applications, and how to implement encoder-decoder sequence-to-sequence models using Keras (up until data preparation; for training and testing models, stay tuned for Part 2).
Specifically, we'll cover:
- Introduction
- Architecture
- Applications
- Text Summarization Using an Encoder-Decoder Sequence-to-Sequence Model
You can also follow along with the full code in this tutorial and run it on a free GPU from a Gradient Community Notebook.
Let’s get started!
Bring this project to life
Introduction
An RNN typically has fixed-size input and output vectors, i.e., the lengths of both the input and output vectors are predefined. Nonetheless, this isn't desirable in use cases such as speech recognition, machine translation, etc., where the input and output sequences do not need to be fixed and of the same length. Consider a case where the English phrase "How have you been?" is translated into French. In French, you’d say "Comment avez-vous été?". Here, neither the input nor output sequences are fixed in size. In this context, if you want to build a language translator using an RNN, you do not want to define the sequence lengths beforehand.
Sequence-to-sequence (seq2seq) models can help solve the above-mentioned problem. When given an input, the encoder-decoder seq2seq model first generates an encoded representation of the model, which is then passed to the decoder to generate the desired output. In this case, the input and output vectors need not be fixed in size.
Architecture
The idea behind the design of this model is to enable it to process input where we do not constrain the length. One RNN will be used as an encoder, and another as a decoder. The output vector generated by the encoder and the input vector given to the decoder will possess a fixed size. However, they need not be equal. The output generated by the encoder can either be given as a whole chunk or can be connected to the hidden units of the decoder unit at every time step.

The RNNs in the encoder and decoder can be simple RNNs, LSTMs, or GRUs.
In a simple RNN, every hidden state is computed using the equation:
$$H_t (encoder) = \phi(W_{HH} * H_{t-1} + W_{HX} * X_{t})$$
Where $\phi$ is the activation function, $H_t (encoder)$ represents the hidden states in an encoder, $W_{HH}$ is the weight matrix connecting the hidden states, and $W_{HX}$ is the weight matrix connecting the input and the hidden states.
The hidden states in the decoder can be computed as follows:
$$H_t (decoder) = \phi(W_{HH} * H_{t-1})$$
Note: The initial hidden state of the decoder is the final hidden state procured from the encoder.
The output generated by the decoder is given as follows:
$$Y_t = H_t (decoder) * W_{HY}$$
Where $W_{HY}$ is the weights matrix connecting the hidden states with the decoder output.
Applications of Seq2Seq Models
Seq2seq models are useful for the following applications:
- Machine translation
- Speech recognition
- Video captioning
- Text summarization
Now that you’ve got an idea about what a Sequence-to-Sequence RNN is, in the next section you’ll build a text summarizer using the Keras API.
Text Summarization Using a Seq2Seq Model
Text Summarization refers to the technique of shortening long pieces of text while capturing its essence. This is useful in capturing the bottom line of a large piece of text, thus reducing the required reading time. In this context, rather than relying on manual summarization, we can leverage a deep learning model built using an Encoder-Decoder Sequence-to-Sequence Model to construct a text summarizer.
In this model, an encoder accepts the actual text and summary, trains the model to create an encoded representation, and sends it to a decoder which decodes the encoded representation into a reliable summary. As the training progresses, the trained model can be used to perform inference on new texts, generating reliable summaries from them.
Here we’re going to use the News Summary Dataset. It consists of two CSV files: one contains information about the author, headlines, source URL, short article, and complete article, and another which only contains headlines and text. In the current application, you will extract the headlines and text from the two CSV files to train the model.
Note that you can follow along with the full code in this tutorial and run it on a free GPU from a Gradient Community Notebook.
Step 1: Importing the Dataset
First import the news summary dataset to your workspace using the pandas's read_csv() method.
import pandas as pd
summary = pd.read_csv('/kaggle/input/news-summary/news_summary.csv',
encoding='iso-8859-1')
raw = pd.read_csv('/kaggle/input/news-summary/news_summary_more.csv',
encoding='iso-8859-1')
Combine data from the two CSV files into a single DataFrame.
pre1 = raw.iloc[:, 0:2].copy()
pre2 = summary.iloc[:, 0:6].copy()
# To increase the intake of possible text values to build a reliable model
pre2['text'] = pre2['author'].str.cat(pre2['date'
].str.cat(pre2['read_more'].str.cat(pre2['text'
].str.cat(pre2['ctext'], sep=' '), sep=' '), sep=' '), sep=' ')
pre = pd.DataFrame()
pre['text'] = pd.concat([pre1['text'], pre2['text']], ignore_index=True)
pre['summary'] = pd.concat([pre1['headlines'], pre2['headlines']],
ignore_index=True)Note: To increase the intake of data points to train the model, a new 'text' column is constructed utilizing one CSV file.
Let's get a better understanding of the data by printing the first two rows to the console.
pre.head(2)
Step 2: Cleaning the Data
The data you procured can have non-alphabetic characters which you can remove before training the model. To do this, you can use the re (Regular Expressions) library.
import re
# Remove non-alphabetic characters (Data Cleaning)
def text_strip(column):
for row in column:
row = re.sub("(\\t)", " ", str(row)).lower()
row = re.sub("(\\r)", " ", str(row)).lower()
row = re.sub("(\\n)", " ", str(row)).lower()
# Remove _ if it occurs more than one time consecutively
row = re.sub("(__+)", " ", str(row)).lower()
# Remove - if it occurs more than one time consecutively
row = re.sub("(--+)", " ", str(row)).lower()
# Remove ~ if it occurs more than one time consecutively
row = re.sub("(~~+)", " ", str(row)).lower()
# Remove + if it occurs more than one time consecutively
row = re.sub("(\+\++)", " ", str(row)).lower()
# Remove . if it occurs more than one time consecutively
row = re.sub("(\.\.+)", " ", str(row)).lower()
# Remove the characters - <>()|&©ø"',;?~*!
row = re.sub(r"[<>()|&©ø\[\]\'\",;?~*!]", " ", str(row)).lower()
# Remove mailto:
row = re.sub("(mailto:)", " ", str(row)).lower()
# Remove \x9* in text
row = re.sub(r"(\\x9\d)", " ", str(row)).lower()
# Replace INC nums to INC_NUM
row = re.sub("([iI][nN][cC]\d+)", "INC_NUM", str(row)).lower()
# Replace CM# and CHG# to CM_NUM
row = re.sub("([cC][mM]\d+)|([cC][hH][gG]\d+)", "CM_NUM", str(row)).lower()
# Remove punctuations at the end of a word
row = re.sub("(\.\s+)", " ", str(row)).lower()
row = re.sub("(\-\s+)", " ", str(row)).lower()
row = re.sub("(\:\s+)", " ", str(row)).lower()
# Replace any url to only the domain name
try:
url = re.search(r"((https*:\/*)([^\/\s]+))(.[^\s]+)", str(row))
repl_url = url.group(3)
row = re.sub(r"((https*:\/*)([^\/\s]+))(.[^\s]+)", repl_url, str(row))
except:
pass
# Remove multiple spaces
row = re.sub("(\s+)", " ", str(row)).lower()
# Remove the single character hanging between any two spaces
row = re.sub("(\s+.\s+)", " ", str(row)).lower()
yield rowNote: You can use other data cleaning methods to prepare your data as well.
Call the text_strip() function on both the text and summary.
processed_text = text_strip(pre['text'])
processed_summary = text_strip(pre['summary'])Load the data as batches using the pipe() method provided by spaCy. This ensures that all pieces of text and summaries possess the string data type.
import spacy
from time import time
nlp = spacy.load('en', disable=['ner', 'parser'])
# Process text as batches and yield Doc objects in order
text = [str(doc) for doc in nlp.pipe(processed_text, batch_size=5000)]
summary = ['_START_ '+ str(doc) + ' _END_' for doc in nlp.pipe(processed_summary, batch_size=5000)]The _START_ and _END_ tokens denote the start and end of the summary, respectively. This will be used later to detect and remove empty summaries.
Now let's print some of the data to understand how it’s been loaded.
text[0]
# Output
'saurav kant an alumnus of upgrad and iiit-b s pg program in ...'
Print the summary as well.
summary[0]# Output
'_START_ upgrad learner switches to career in ml al with 90% salary hike _END_'
Step 3: Determining the Maximum Permissible Sequence Lengths
Next, store the text and summary lists in pandas objects.
pre['cleaned_text'] = pd.Series(text)
pre['cleaned_summary'] = pd.Series(summary)Plot a graph to determine the frequency ranges tied to the lengths of text and summary, i.e., determine the range of length of words where the maximum number of texts and summaries fall into.
import matplotlib.pyplot as plt
text_count = []
summary_count = []
for sent in pre['cleaned_text']:
text_count.append(len(sent.split()))
for sent in pre['cleaned_summary']:
summary_count.append(len(sent.split()))
graph_df = pd.DataFrame()
graph_df['text'] = text_count
graph_df['summary'] = summary_count
graph_df.hist(bins = 5)
plt.show()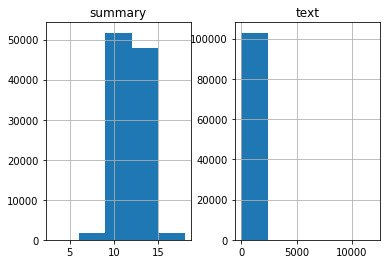
From the graphs, you can determine the range where the maximum number of words fall into. For summary, you can assign the range to be 0-15.
To find the range of text which we aren't able to clearly decipher from the graph, consider a random range and find the percentage of words falling into that range.
# Check how much % of text have 0-100 words
cnt = 0
for i in pre['cleaned_text']:
if len(i.split()) <= 100:
cnt = cnt + 1
print(cnt / len(pre['cleaned_text']))# Output
0.9578389933440218As you can observe, 95% of the text pieces fall into the 0-100 category.
Now initialize the maximum permissible lengths of both text and summary.
# Model to summarize the text between 0-15 words for Summary and 0-100 words for Text
max_text_len = 100
max_summary_len = 15Step 4: Selecting Plausible Texts and Summaries
Select texts and summaries which are below the maximum lengths as defined in Step 3.
# Select the Summaries and Text which fall below max length
import numpy as np
cleaned_text = np.array(pre['cleaned_text'])
cleaned_summary= np.array(pre['cleaned_summary'])
short_text = []
short_summary = []
for i in range(len(cleaned_text)):
if len(cleaned_summary[i].split()) <= max_summary_len and len(cleaned_text[i].split()) <= max_text_len:
short_text.append(cleaned_text[i])
short_summary.append(cleaned_summary[i])
post_pre = pd.DataFrame({'text': short_text,'summary': short_summary})
post_pre.head(2)
Now add start of the sequence (sostok) and end of the sequence (eostok) to denote start and end of the summaries, respectively. This shall be useful to trigger the start of summarization during the inferencing phase.
# Add sostok and eostok
post_pre['summary'] = post_pre['summary'].apply(lambda x: 'sostok ' + x \
+ ' eostok')
post_pre.head(2)
Step 5: Tokenizing the Text
First split the data into train and test data chunks.
from sklearn.model_selection import train_test_split
x_tr, x_val, y_tr, y_val = train_test_split(
np.array(post_pre["text"]),
np.array(post_pre["summary"]),
test_size=0.1,
random_state=0,
shuffle=True,
)Prepare and tokenize the text data.
# Tokenize the text to get the vocab count
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
# Prepare a tokenizer on training data
x_tokenizer = Tokenizer()
x_tokenizer.fit_on_texts(list(x_tr))Find the percentage of occurrence of rare words (say, occurring less than 5 times) in the text.
thresh = 5
cnt = 0
tot_cnt = 0
for key, value in x_tokenizer.word_counts.items():
tot_cnt = tot_cnt + 1
if value < thresh:
cnt = cnt + 1
print("% of rare words in vocabulary: ", (cnt / tot_cnt) * 100)# Output
% of rare words in vocabulary: 62.625791318822664Tokenize the text again by considering the total number of words minus the rare occurrences. Convert text to numbers and pad them all to the same length.
# Prepare a tokenizer, again -- by not considering the rare words
x_tokenizer = Tokenizer(num_words = tot_cnt - cnt)
x_tokenizer.fit_on_texts(list(x_tr))
# Convert text sequences to integer sequences
x_tr_seq = x_tokenizer.texts_to_sequences(x_tr)
x_val_seq = x_tokenizer.texts_to_sequences(x_val)
# Pad zero upto maximum length
x_tr = pad_sequences(x_tr_seq, maxlen=max_text_len, padding='post')
x_val = pad_sequences(x_val_seq, maxlen=max_text_len, padding='post')
# Size of vocabulary (+1 for padding token)
x_voc = x_tokenizer.num_words + 1
print("Size of vocabulary in X = {}".format(x_voc))# Output
Size of vocabulary in X = 29638Do the same for the summaries as well.
# Prepare a tokenizer on testing data
y_tokenizer = Tokenizer()
y_tokenizer.fit_on_texts(list(y_tr))
thresh = 5
cnt = 0
tot_cnt = 0
for key, value in y_tokenizer.word_counts.items():
tot_cnt = tot_cnt + 1
if value < thresh:
cnt = cnt + 1
print("% of rare words in vocabulary:",(cnt / tot_cnt) * 100)
# Prepare a tokenizer, again -- by not considering the rare words
y_tokenizer = Tokenizer(num_words=tot_cnt-cnt)
y_tokenizer.fit_on_texts(list(y_tr))
# Convert text sequences to integer sequences
y_tr_seq = y_tokenizer.texts_to_sequences(y_tr)
y_val_seq = y_tokenizer.texts_to_sequences(y_val)
# Pad zero upto maximum length
y_tr = pad_sequences(y_tr_seq, maxlen=max_summary_len, padding='post')
y_val = pad_sequences(y_val_seq, maxlen=max_summary_len, padding='post')
# Size of vocabulary (+1 for padding token)
y_voc = y_tokenizer.num_words + 1
print("Size of vocabulary in Y = {}".format(y_voc))# Output
% of rare words in vocabulary: 62.55667945587723
Size of vocabulary in Y = 12883Step 6: Removing Empty Texts and Summaries
Remove all empty summaries (which only have START and END tokens) and their associated texts from the data.
# Remove empty Summaries, .i.e, which only have 'START' and 'END' tokens
ind = []
for i in range(len(y_tr)):
cnt = 0
for j in y_tr[i]:
if j != 0:
cnt = cnt + 1
if cnt == 2:
ind.append(i)
y_tr = np.delete(y_tr, ind, axis=0)
x_tr = np.delete(x_tr, ind, axis=0)Repeat the same for the validation data as well.
# Remove empty Summaries, .i.e, which only have 'START' and 'END' tokens
ind = []
for i in range(len(y_val)):
cnt = 0
for j in y_val[i]:
if j != 0:
cnt = cnt + 1
if cnt == 2:
ind.append(i)
y_val = np.delete(y_val, ind, axis=0)
x_val = np.delete(x_val, ind, axis=0)We'll continue this in Part 2, where we build the model, train it, and do inference.
Conclusion
So far in this tutorial, you've seen what an Encoder-Decoder Sequence-to-Sequence model is along with its architecture. You've also prepared the news summary dataset to train your own seq2seq model in order to summarize given pieces of text.
In the next part of this two-part series, you'll build, train, and test the model.








