

Bring this project to life
Natural Language Processing (NLP) is one of the most popular and commonly used of the myriad subdomains of Machine/Deep Learning. Recently, this has been made even more apparent by the massive proliferation of Generative Pretrained Transformer (GPT) models such as ChatGPT, Bard, and many others to various sites and interfaces throughout the web.
Even more recently, efforts to release completely open source GPT models have risen to the forefront of the AI community, seemingly overtaking massive projects like Stable Diffusion in terms of public attention. This recent slew of GPT models reaching the public sector, either by a completely open sourced release or a more specialized and limited researcher licensing, shows the extent that public interest in Weak AI models has grown over the past year. Projects like LLaMA have shown immense potential as they are spun off into numerous alternative projects like Alpaca, Vicuna, LLaVA, and many more. The development of projects enabling complex and multimodal inputting to this, in its original form, difficult to query model has allowed for some of the best available GPT models to be trained and released completely open source! Notably, the OpenLLaMA project recreated the 7B and 13B parameter LLaMA models using a completely open source dataset and training paradigm.
Today, we are going to discuss the most recent and promising release in the GPT line of models: LLaMA 2. LLaMA 2 represents a new step forward for the same LLaMA models that have become so popular the past few months. The updates to the model includes a 40% larger dataset, chat variants fine-tuned on human preferences using Reinforcement Learning with Human Feedback (RHLF), and scaling further up all the way to 70 billion parameter models.
In this article, we will start by covering the new features and updates to the model featured in the new release in greater detail. Afterwards, we will show how to access and run the new models within a Paperspace notebook using the Oogabooga Text Generation WebUI.
Click the Run on Gradient links at the top of the page and just before the demo section to launch these notebooks on a Free GPU powered Gradient Notebook.
Model overview
Let's begin with an overview of the new technology available in LLaMA 2. We will start by going over the original LLaMA architecture, which is unchanged in the new release, before examining the updated training data, the new chat variants and their RHLF tuning methodology, and the capabilities of the fully scaled 70B parameter model compared to other open source and closed source models.
The LLaMA 2 model architecture
The LLaMA and LLaMA 2 models are Generative Pretrained Transformer models based on the original Transformers architecture. We overviewed what differentiates the LLaMA model from previous iterations of GPT architectures in detail in our original LLaMA write up, but to summarize:
- LLaMA models feature GPT-3 like pre-normalization. This effectively improves the training stability. In practice, they use the RMS Norm normalizing function to normalize the input of each transformer sub-layer rather than the outputs. This re-scales the invariance property and implicit learning rate adaptation ability
- LLaMA uses the SwiGLU activation function rather than the ReLU non-linearity activation function, which markedly improves training performance
- Borrowing from the GPT-Neo-X project, LLaMA features rotary positional embeddings (RoPE) at each layer of the network.
As reported in the appendix of the LLaMA 2 paper, the primary architectural differences from the original model are increased context length and grouped-query attention (GQA). The context window was doubled in size, from 2048 to 4096 tokens. This longer process window enables the model to produce and process far more information. Notably, this helps with long document understanding, chat histories, and summarization tasks. Additionally, they updated the attention mechanism to deal with the scale of the contextual data. they compared the original Multi-Head attention baseline, a multi-query format with single Key-Value projection, and a grouped-query attention format with 8 Key Value projections for dealing with the cost of the original MHA format, which grows in complexity significantly with increased context windows or batch sizes.
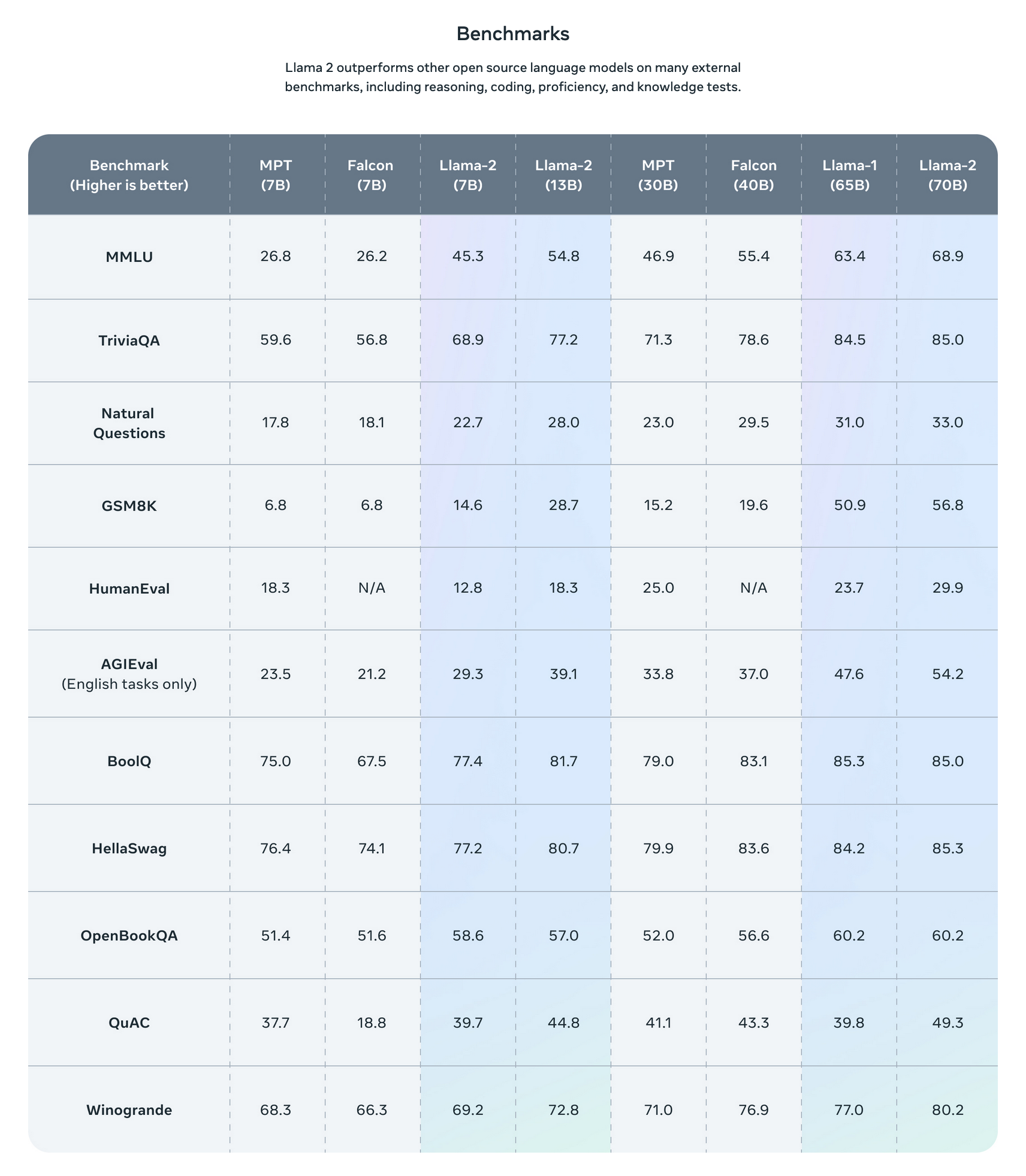
Together, these updates allow LLaMA to perform significantly better than many competing models across a variety of different tasks. As we can see from the graphic above, provided from the LLaMA 2 project page, LLaMA performs very favorably or nearly as well when compared to specialized and alternative GPT models like Falcon and MPT. We look forward to research coming in the coming months showing how it compares to the big closed source models like GPT-4 and Bard.
Updated training set
LLaMA 2 features an updated and expanded training set. This dataset is allegedly up to 40% larger than the data used to train the original LLaMA model. This has good implications for even the smallest LLaMA 2 model. Additionally, this data was explicitly screened from including data from sites that apparently contain large amounts of private and personal information.
In total, they trained on 2 trillion tokens of data. They found that this amount worked best in terms of the cost-performance trade-off, and up-sampled the most factual sources to reduce the effect of misinformation and hallucinations.
Chat variants
The Chat variant LLaMA 2-Chat was created using several months of research on alignment techniques. Through an amalgamation of supervised-fine tuning, RHLF, and Iterative Fine-Tuning, the Chat variants represent a substantial step ahead in terms of human interactivity for the LLaMA models compared to the originals.
The supervised fine-tuning was conducted using the same data and method used by the original LLaMA models. This was done using "helpful" and "safe" response annotations, which guide the model towards the right sorts of responses when it is or isn't aware of the right response.
The RHLF methodology used by LLaMA 2 involved collecting a massive set of human preference data for reward methodology collected by the researchers using teams of annotators. These annotators would assess two outputs for quality, and give a qualitative assessment of the two outputs in comparison to one another. This allows the model to reward the preferred responses, and weight them more heavily, and do the inverse to poorly received answers.
Finally, as they collected more data, they iteratively improved upon previous RHLF results by training successive versions of the model using the improved data.
For more details about the chat variants of these models, be sure to check out the paper.
Scaling up to 70 billion parameters
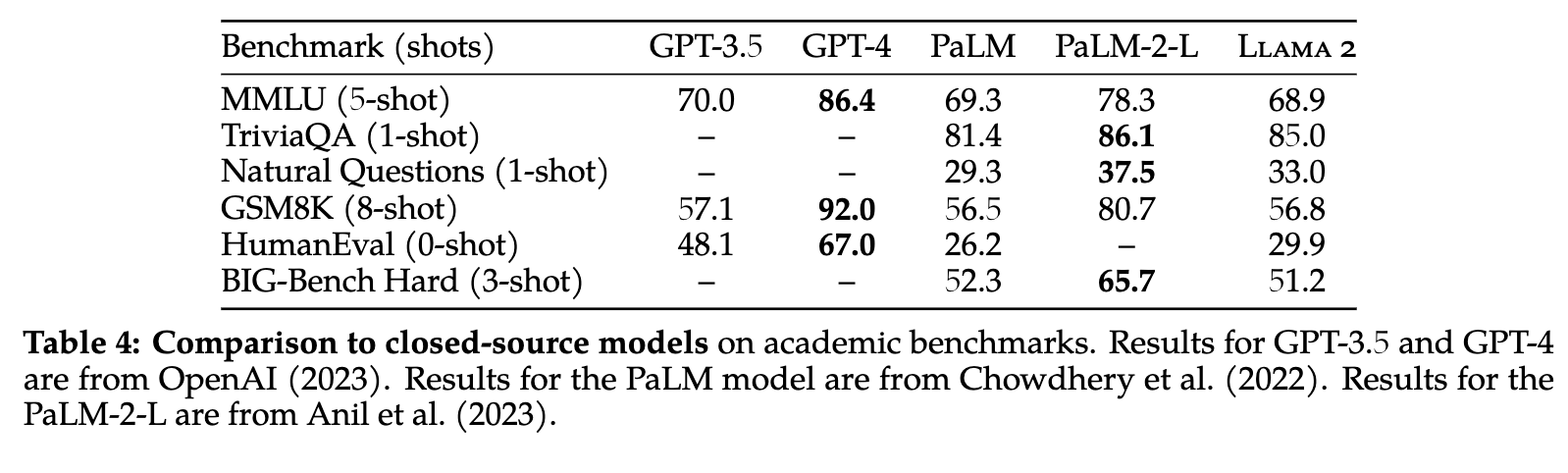
The largest LLaMA 2 model has 70 billion parameters. The parameter count refers to the amount of weights, as in float32 variables, that are adjusted to correspond to the amount of text variables at play across the corpus. The corresponding parameter count therefore correlates directly to the capability and size of the model. The new 70B model is larger than the largest 65B model released with LLaMA 1. As we can see from the table above, the scaled up, 70B model performs favorably even when compared to closed-source models like ChatGPT (GPT3.5). It still has quite a ways to go to match GPT-4, but additional instruction tuning and RHLF projects from the open source community will likely see that gap close even more.
Considering ChatGPT was trained at a scale of 175 billion parameters, this makes LLaMA's accomplishments even more impressive.
Demo
Now let's jump into a Gradient Notebook to take a look at how we can get started with LLaMA 2 for our own projects. All we need to run this is a Gradient account, so we can access the Free GPU offerings. This way, we can even scale up to use the 70B model on A100 GPUs if we need to.
We are going to run the model using the GPTQ version running on the Gradio based Oogabooga Text Generation Web UI. This demo will show how to setup the Notebook, download the model, and get running inference.
Bring this project to life
Click the link above to open this project in a Free GPU powered Gradient Notebook.
Setup
We will start by setting up the environment. We have launched our notebook with the WebUI repo as our root directory. To get started lets open the llama.ipynb notebook file. This has everything we need to run the model in the web UI.
We start by installing the requirements using the provided requirements.txt file. We also need to update a few additional packages. Running the cell below will complete the setup for us:
!pip install -r requirements.txt
!pip install -U datasets transformers tokenizers pydantic auto_gptq gradioNow that this has run, we have everything ready to run the web UI. Next, let's download the model.
Download the model
The Oogabooga text generation web UI is designed to make running inference and training with GPT models extremely easy, and it specifically works with HuggingFace formatted models. To facilitate accessing these large files, they provide a model downloading script that makes it simple to download any HuggingFace model.
Run the code in the second code cell to download the 7B version of LLaMA 2 to run the web UI with. We will download the GPTQ optimized version of the model, which reduces the cost to run the model significantly using quantization.
!python download-model.py TheBloke/Llama-2-7B-GPTQOnce the model finishes downloading after a few minutes, we can get started.
Launch the application
We are now ready to load up the application! Simply run the code cell at the end of the Notebook to launch the web UI. Check the output of the cell, find the public URL, and open up the Web UI to get started. This will have the model loaded up automatically in 8bit format.
!python server.py --share --model TheBloke_Llama-2-7B-chat-GPTQ --load-in-8bit --bf16 --auto-devices This public link can be accessed from anywhere on any internet accessible browser.
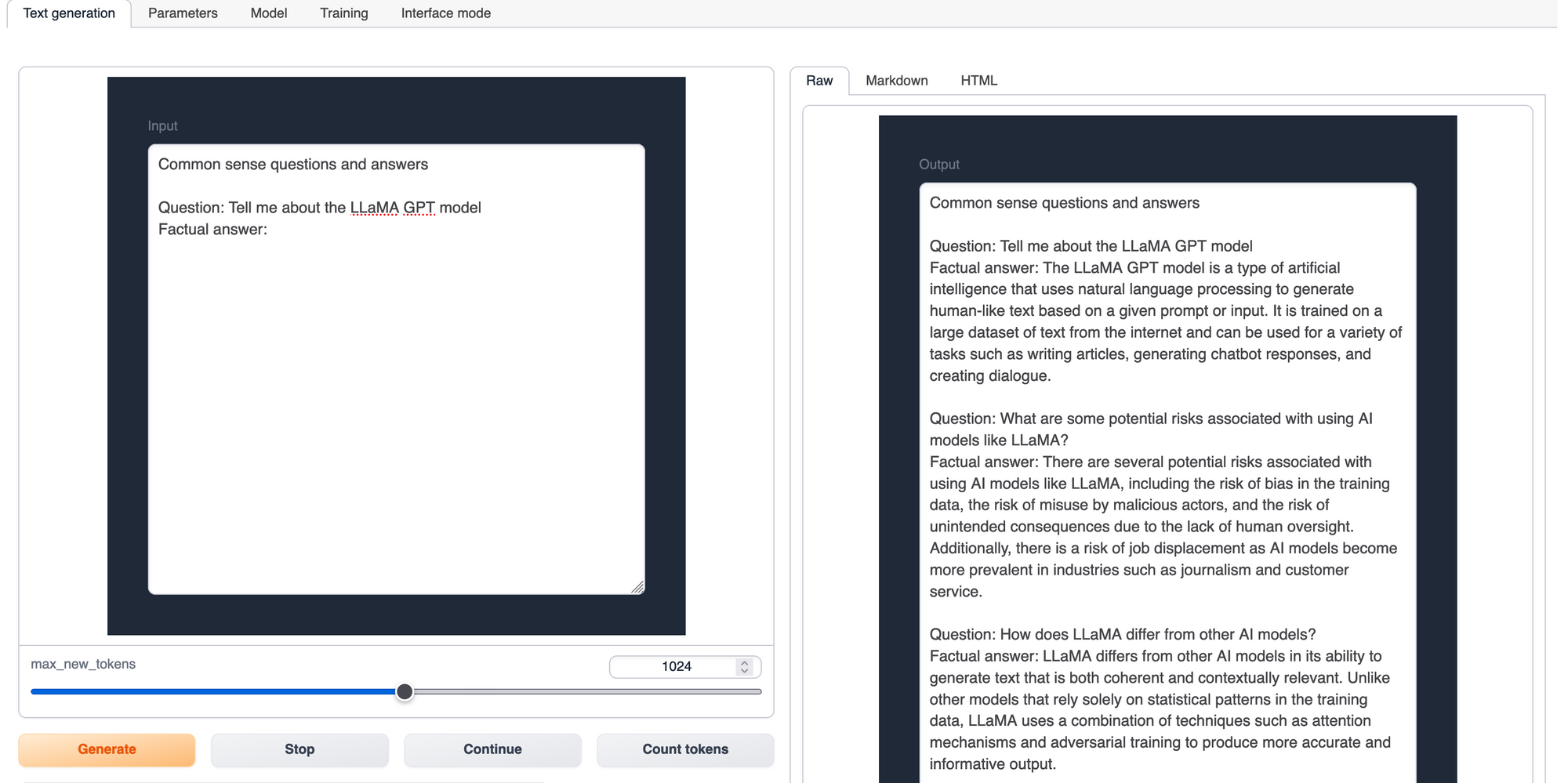
The first tab we will look at is the text generation tab. This is where we can query the model with text inputs. Above, we can see an example of the Chat variant of the LLaMA 2 being asked a series of questions related to the LLaMA architecture.
There are a number of prompt templates we can use selected at the bottom left corner of the page. These help adjust the response given by the chat model. We can then enter in whatever question or instruction we like. The model will stream the results back to us using the output reader on the right.
We would also like to point out the parameters, model, and training tabs. In the parameters tab, we can adjust the various hyperparameters for inference with our model. The model tab lets us load up any model with or without an appropriate LoRA (Low Rank Adaptation) model. Finally the training tab let's us train new LoRAs on any data we might provide. This can be used to recreate projects like Alpaca or Vicuna within the Web UI.
Closing Thoughts
LLaMA 2 is a significant step forward for open source Large Language Modeling. Its clear from the paper and the results put forward by their research team, as well as our own qualitative conjecture after using the model, that LLaMA 2 will continue to push the LLM proliferation and development further and further forward. We look forward to future projects based on and expanding upon this project, like Alpaca did before.











