
Bring this project to life
As we strive to create AI agents that can plan, reflect, and think ahead, it is becoming clear that large language models alone are not enough. We need a robust memory system similar to the human brain to mimic human intelligence and have cognitive abilities. This storage system should be able to record and retrieve memory traces using context, in this case embeddings, allowing the AI agent to process the information and make informed decisions effectively. In this article, we will learn about MemGPT with real-life examples. We will also learn about its architecture through a Paperspace MemGPT Demo.
What is MemGPT?
MemGPT (short for Memory GPT) is a system that aims to remove the limitations of context windows in language models. MemGPT takes inspiration from the memory systems of traditional operating systems and introduces the concept of virtual context management. The system intelligently manages different storage levels and provides enhanced context within the LLM's limited context window. By effectively using memory resources, MemGPT enabled
- Richer inferences
- Improved memory retention
- Improved language production
Example:

Datasets used:
- Expanded Multi-Session Chat (MSC) Dataset (originally by Xu et al., 2021).
- Liu et al. (2023a) tasks for question answering and key-value retrieval.
- A new nested key-value retrieval dataset.
- A dataset of embeddings for 20 million Wikipedia articles.
Datasets used in the paper can be downloaded at Hugging Face.
Applications of MemGPT
- Document Analysis
MemGPT enabled comprehensive document analysis, in practice facilitating
- Intelligent information extraction
- Summarization
- Contextual understanding
This makes it suitable for in-depth analysis of extensive documents in legal, academic, or business contexts.
- Multi-Session Chat Interactions
It can be employed in conversational AI for multi-session chat interactions, maintaining context and consistency over long conversations. This benefits customer service bots, virtual assistants, and other applications requiring sustained interaction.
- Generative Tasks
MemGPT's enhanced context management suits generative tasks like creative writing, content generation, and more complex generative AI applications.
- Natural Language Processing Tasks
Its capabilities extend to various NLP tasks, potentially including sentiment analysis, language translation, and summarisation, where understanding and maintaining context is crucial.
- Multimodal Capabilities
Unlike ChatGPT, MemGPT capabilities suggest the potential for integrating multimodal inputs and outputs. This enables interactions with different forms of media.
Understanding MemGPT with Real-life Example

Let's imagine you're reading a book, and your memory is like a sliding context window that can only capture a few words at a time. In traditional language models, this reading window is limited, making it challenging to understand the full story if it's too long.
Now, think of MemGPT as a smart reading assistant (almost an LLM OS) with a unique ability. Instead of just having a fixed window, it can intelligently decide what parts of the book to keep in its reading window and what to store separately, like a bookmark. This gives the illusion of an unlimited reading window, allowing it to understand and remember more of the story, without the computational expense of actually holding the entire book in context.
For example, if the book mentions a character on page 10 and refers back to them on page 50, MemGPT can retrieve the relevant information as if flipping back to an earlier page. It's like having a super-smart bookmark that remembers the current page and helps recall important details from different parts of the book.
So, MemGPT manages its reading "context" cleverly, creating a continuous flow of information, similar to how you would handle reading a complex novel with many plot twists and characters. This flexibility helps it handle tasks like understanding long conversations or analyzing extensive documents by adjusting what it keeps in its "reading window" during different stages of a task.
Contributions of this Research
- OS-Inspired LLM System
The paper presents MemGPT as an operating system-inspired LLM system. This novel approach makes language models capable of managing and utilizing long-term memory of user inputs, which is crucial for applications like complex data analysis and conversational agents.
- Introduction of Interrupts
An interrupt system is introduced in MemGPT to manage the control flow between itself and the user. This interrupt system works the same as in traditional OS.
- The illusion of ‘unlimited amount of context.’
MemGPT allows the LLM to retrieve relevant historical data that might be missing from the current in-context information, similar to an OS handling a page fault. This means the model's capability of handling longer sequences of text or information was enhanced by using virtual memory management.
- Function Calling Abilities
The MemGPT framework has functions like sending messages, reading messages, writing messages, and pausing interrupts. The function calling abilities are crucial in enhancing operational efficiency and flexibility. With function calls, control is requested in advance. This chains together multiple functions sequentially, enhancing the system's ability to handle complex tasks and workflows.
Model Architecture
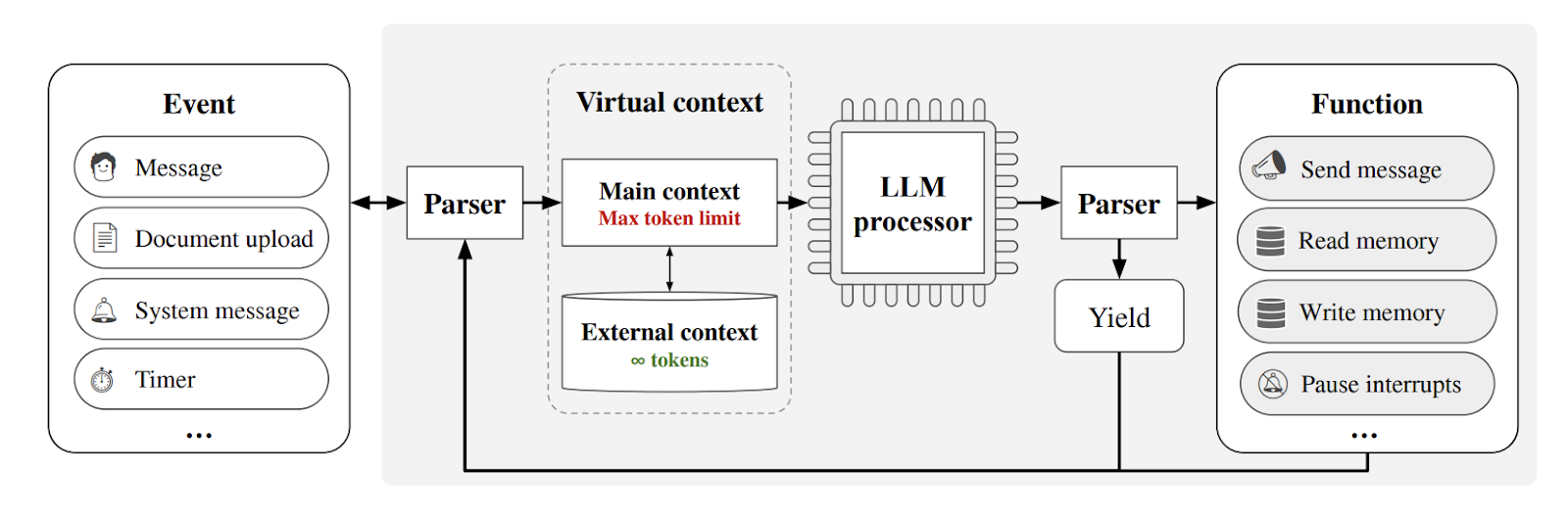
Input is given as a message, document, or system message. The parser parses it.
- Main Context
Just recall the purpose of main memory or RAM in an operating system.’The main context’ is analogous to the concept of RAM. The main context is used to store instructions.
- External Context
This is a secondary, larger memory store analogous to disk storage in a computer system. In the case of long conversations, the AI might start forgetting earlier parts. MemGPT solves this by storing older parts of the conversation in the ‘external context.’ This is done by storing the entire history of events processed by the LLM processor. This information can be brought into context memory from the external context through paginated function calls.
- LLM Processor
The LLM processor is the core part of MemGPT that processes language and understands what to do with it. It processes the main context as input. LLM processes the data, and the parser now interprets this data. Papers understand the data and decide the next step. This can result in two things:
- Yield: This is like hitting the pause button. The processor waits until something new happens (like getting a message from the user). The processor is on standby mode while yielding. It waits if there is any new external event, like a new message from the user, and then it will be active again.
- Function Call: This is an action command. The processor can ask to perform certain functions, especially to manage memory.
- Self-Directed Editing and Retrieval
The data is moved between the main and external contexts. Special instructions and functions are used to manage this memory movement.
Demo/Experiments
Bring this project to life
Launching the demo on Paperspace is straightforward. To begin with, initiate a Paperspace Notebook with your preferred GPU. Clone the repository to the Notebook. Next, open the project on Paperspace; the repository will serve as your primary workspace.
Now run this code for cloning:
!apt-get update && apt-get install -y git-lfs festival espeak-ng mbrola
!git clone https://github.com/cpacker/MemGPT.gitRunning MemGPT locally
First install MemGPT
!pip install -U pymemgpt`
Now, you can run MemGPT and start chatting with a MemGPT agent with:
memgpt runNote that this has to be done in a Terminal. Below, We have pictured a basic interaction with MemGPT after we tried checking its performance.
Future Directions
- Limited memory: Researchers have tried to develop an efficient memory management system, but MemGPT has token budget constraints. This is because some portion of memory is consumed by the system instructions, limiting the amount of contextual data that can be processed at a given time. So, the number of documents that can be held in content at a particular time will be less.
Solution:
- Enhance MemGPT memory by incorporating various memory tier technologies like databases or caches.
- Memory allocation systems can be optimised.
- Lower accuracy: MemGPT have lower accuracy than GPT 4.
Solution:
- Enhance MemGPT's accuracy by fine-tuning.
- Optimize the model's architecture and parameters. This could involve adjusting layers, neurons, or learning rates to improve performance.
- Improve the prompts used to interact with MemGPT.
- Increased Complex: Integrating memory in LLMs has added complexity to the system. This could potentially impact the framework's adaptability and ease of use in various applications.
- Exploration: MemGPT has not yet been explored in various applications with massive or unbounded contexts. Explore MemGPT in other domains with massive or unbounded contexts.
Solution: Exploration in large-scale data analysis, complex interactive systems, and more sophisticated AI agents is a promising direction.
- Reliance on closed model: According to researchers, MemGPT reference implementation leverages Open AI GPT 4 for finetuning function calling, but the inner workings of OPenAI’s model are not disclosed publicly. So, it relies on closed-source models like GPT 3, GPT 4 and Llama 2 70B. So, in short, researchers could not finetune this model much.
Solution:
- Using open-source Large Language Models (LLMs) can provide more transparency and control.
- Establishing collaboration or partnerships with the developers of proprietary models (like OpenAI for GPT-4)
- Developing hybrid systems that combine the strengths of both open-source and proprietary models could offer a balanced solution.
Closing Thoughts
MemGPT tries to solve this by giving the AI a way to "jot down notes" (external context) of the conversation to which it can refer back. This way, even if the AI focuses on complex instructions, it can still handle long conversations effectively, much like an actor referring to their script and notes during a long play.











