
Bring this project to life
Recently, large language models (LLMs) have revolutionized the landscape of speech synthesis, offering powerful capabilities in zero-shot scenarios. But still there are challenges like slow inference speed and limited robustness, reminiscent of previous autoregressive speech models, which needs to be overcome. To tackle these challenges, researchers have developed the HierSpeech++ model. According to the authors of the original paper, this model is a self-supervised speech model that adopts the text-to-vec framework for text-to-speech (TTS) generation, and it can also synthesize speech with prosodic features as it is based on F0 representation. This enhances the overall naturalness of the generated speech. The system is like a speech synthesizer that can make a computer sound like a person's voice.
What is HierSpeech++?
HierSpeech++ is a human-level zero-shot speech synthesis model pipeline - it mimics or emulates human speech with a high level of naturalness and authenticity - which consists of a hierarchical speech synthesizer, text-to-vec (TTV), and speech super resolution (SpeechSR) modals.
This model has outperformed large language model (LLM) and diffusion-based models, and HierSpeech++ has proven one of the top performers in terms of robustness, quality and speed. Thus, we can expect expressiveness of synthetic speech and emotion in the synthesized speech in text-to-speech and voice conversion scenarios with this model.
The model takes the following inputs:
- Speech waveform: The model takes the input speech waveform, which is converted into a Mel-spectrogram for further processing.
- Text input: The model also takes a text input, which is used to generate the output speech waveform. This is typically done by converting the text into a sequence of acoustic features or representations using a text-to-speech model.
Datasets used
The research has used the following datasets:
- Open Source Korean speech datasets
- NIKL dataset from the NIA
- Multi-speaker speech synthesis (MSSS) dataset from the AIHub
Applications of HierSpeech++
- Voice Style Adaptation: Generate speech in different styles and adapt to various voices
- Speech Enhancement: Improve speech quality by increasing resolution and details
- Multilingual Speech Synthesis: Generate speech in multiple languages
- Voice Cloning: Mimic the voice characteristics of specific individuals
- Natural-sounding Speech Generation: Create high-quality, realistic speech with nuanced details
- Language Translation: Translate spoken text from one language to another
- Emotional Tone Modification: Modify the emotional tone of generated speech (e.g., from neutral to sad or happy)
- Gender Switching: Generate speech in different gender voices
- Text-to-Speech Conversion: Convert written text into natural-sounding speech
Contributions of the Research
This paper has introduced:
- Interpolation technique, blending style representations from the original and denoised speech
While removing the noise from the audio there could be reduction of reconstruction quality in terms of CER and WER. Character Error Rate (CER) evaluates the accuracy of automatic speech recognition (ASR) systems and Word Error Rate (WER) measures the percentage of incorrectly predicted words in the generated output compared to the reference text.
This introduces interpolation techniques for striking the balance between audio quality and accuracy in metrics. This ensures that the denoising process (noise removal process) enhances the synthesized speech without sacrificing important phonetic details.
- Multilingual speech (MMS)
This paper utilizes a massively multilingual speech (MMS)-cutting-edge automatic speech recognition (ASR) and text-to-speech synthesis (TTS) model by Meta, which is a pre-trained Wav2Vec 2.0 with a massive scale. MMS was trained with 1,406 language speech data and it was observed that MMS performed better than XLS-R.
- Style prompt replication for 1s voice cloning, and noise-free speech synthesis
Introduce a style prompt replication for 1s voice cloning, and noise-free speech synthesis by adopting a denoised style prompt. Style prompt replication for 1s voice cloning is a new technique which teaches a computer to mimic a person's voice very accurately, even if it only hears the person for 1 sec, and it can also make the sound clearer by getting rid of noise.
4. Better prosody adaptation
Imagine the model talks, it's not just saying words; it's telling a story with feelings! So when we say "better prosody adaptation," we mean the robot can now change its voice to match different feelings or situations, like being happy, sad, or excited.
To make the voice sound more natural and easier to understand Transformer based normalizing flow with AdaLN-Zero was introduced. It's like giving the model a superpower to understand and adjust its voice to match different situations.
Model Architecture
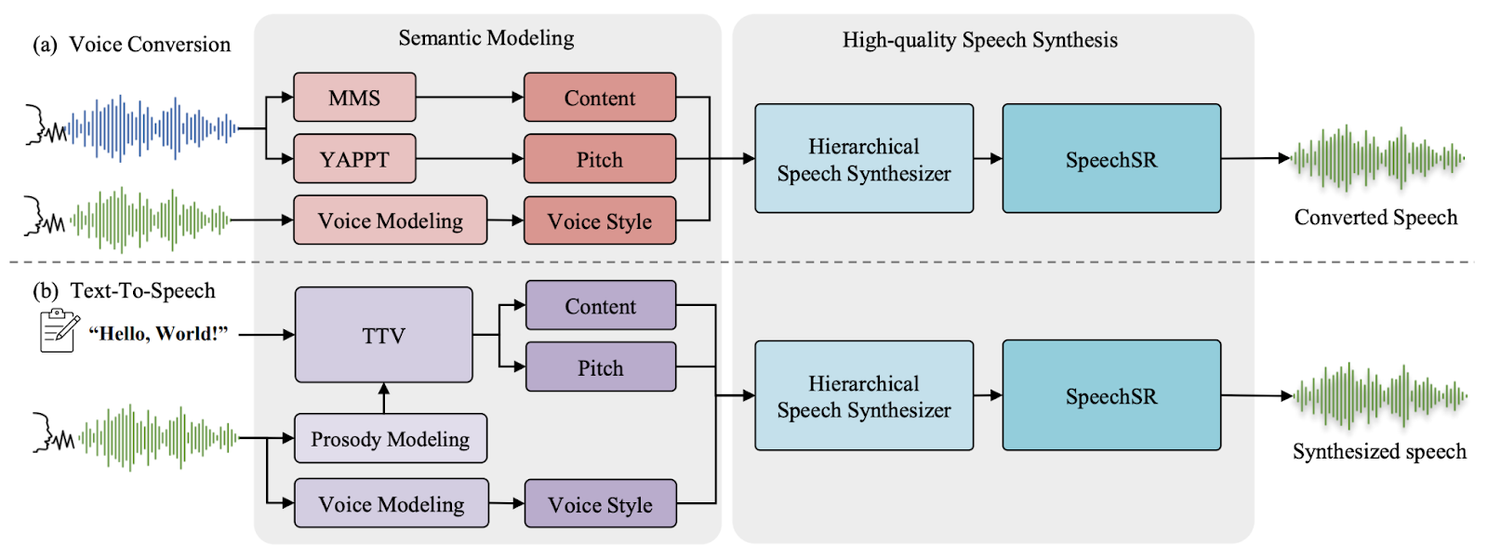
The Hierarchical Speech Synthesis ++ (HSS++) pipeline consists of several components, including a Voice Conversion, Text-to-Speech model, a Speech Synthesis Routine (SpeechSR), and a Hierarchical Speech Synthesizer. The system is designed for various speech synthesis tasks, such as voice conversion, text-to-speech, and style prompt replication. Let’s take a look at each in detail.
1. Voice Conversion
- Semantic Representation: The process of converting the meaning of a text into spoken language. F0 Extraction is done. F0 extraction means figuring out the tone of the voice using a special algorithm called YAPPT
- Normalization and denormalization: Normalization means adjusting the synthesized voice so that it fits well on the original voice characteristics and denormalization means putting the adjusted tone into the new voice style
- Speech Synthesis: Creating a new voice that sounds like the target voice style at 16 kHz
- Upsampling: Now after speech synthesis the next step is to make the synthesized voice even clearer by increasing its quality to 48 kHz. This step can be skipped if the generated voice is clearer
2. Text-to-Speech
- Semantic Representations from Text: Understanding the main ideas from written words
- Generating Semantic Representation with Target Prosody: Making the computer talk in a specific way, like being happy or sad
- Speech Synthesis from Semantic Representations: Creating speech from the understood written ideas at 16 kHz
- Voice modeling: Voice modeling generates speech that sounds natural and authentic, similar to the original speaker
- Prosody Modelling: It is like teaching a computer to understand and imitate the way we express emotions through our voice when we speak. AdaLN-Zero is used for better prosody adaptation
3. SpeechSR
Hierarchical Speech synthesizer synthesis the speech. The Hierarchical Speech Synthesizer is like a team of experts that work together to create the final speech. Now after speech synthesis, the next step is to make the synthesized voice even clearer by increasing its quality to 48 kHz. This step can be skipped if the generated voice is clearer. Here, SpeechSR comes into play. It uses:
- AMP Block: Starts with 32 basic elements (channels) to improve the sound without adding extra details
- NN upsampler: Enhancing the hidden details in the sound and making it more precise and easier to understand
- Discriminator: Discriminator like Multiple Period Discriminator (MPD), Multi-Scale Short-Time Fourier Transform Discriminator (MS-STFTD) and eep Wavelet Transform Discriminator (DWTD) noticing tiny details in the sound and checking the authenticity of sound
Note: SpeechSR can upsample it to a high-resolution from 16 kHz to 48 kHz.
Output: The output of the model is the synthesized speech waveform, which can be compared with the ground truth waveform to evaluate the performance of the model. The model aims to generate natural-sounding speech with the correct prosody and linguistic information, taking into account the input text and Mel-spectrogram.
Demo
Bring this project to life
Now we will turn this research into a working model. First we need to do setup in Gradient Notebook. Click the link above to open the Notebook on a Free Paperspace machine.
To run the demo, use the buttons on the left hand side of the window to find the "Terminals" window, open it, and start a new terminal.
In the terminal, we are going to begin pasting in everything needed to run the notebook. So paste the following code in terminal
apt-get update && apt-get install git-lfs
apt-get install festival espeak-ng mbrolaFollow the instructions in the terminal to complete the install by answering yes to each question when prompted. When that's complete, close the terminal using the trash bin icon in the terminal window on the left, and then open a new one. Once we are done, we can just click on the shared Gradio link to see the output. For that, you need to install Gradio.
Next, paste in the following to the terminal:
apt-get update && apt-get install -y git-lfs festival espeak-ng mbrola
cd HierSpeech_TTS
pip install -r requirements.txt
pip install gradio
pip install utils
python app.py
The researchers have already implemented the code and its available online. So get started with the code by cloning the repository in gradient notebook. Open nb.ipynb. This notebook has all the code we need in the first cell.We will also install Gradio for checking the output.
Import necessary libraries
Let's begin by installing the required libraries. In addition to the libraries, we will also install Gradio.
import os
import torch
import argparse
import numpy as np
from scipy.io.wavfile import write
import torchaudio
import utils
from Mels_preprocess import MelSpectrogramFixed
from hierspeechpp_speechsynthesizer import SynthesizerTrn
from ttv_v1.text import text_to_sequence
from ttv_v1.t2w2v_transformer import SynthesizerTrn as Text2W2V
from speechsr24k.speechsr import SynthesizerTrn as AudioSR
from speechsr48k.speechsr import SynthesizerTrn as AudioSR48
from denoiser.generator import MPNet
from denoiser.infer import denoiseText to Speech
def tts(text, a, hierspeech):
net_g, text2w2v, audiosr, denoiser, mel_fn = hierspeech
os.makedirs(a.output_dir, exist_ok=True)
text = text_to_sequence(str(text), ["english_cleaners2"])
token = add_blank_token(text).unsqueeze(0).cuda()
token_length = torch.LongTensor([token.size(-1)]).cuda()
# Prompt load
audio, sample_rate = torchaudio.load(a.input_prompt)The given Python function, tts, is part of a text-to-speech synthesis using the Hierarchical Speech Synthesizer (Hierspeech) model. It processes input text, converts it to a sequence, manipulates tensors, and loads an audio prompt for subsequent synthesis.
# support only single channel
audio = audio[:1,:]
# Resampling
if sample_rate != 16000:
audio = torchaudio.functional.resample(audio, sample_rate, 16000, resampling_method="kaiser_window")
if a.scale_norm == 'prompt':
prompt_audio_max = torch.max(audio.abs())
# We utilize a hop size of 320 but denoiser uses a hop size of 400 so we utilize a hop size of 1600
ori_prompt_len = audio.shape[-1]
p = (ori_prompt_len // 1600 + 1) * 1600 - ori_prompt_len
audio = torch.nn.functional.pad(audio, (0, p), mode='constant').data
file_name = os.path.splitext(os.path.basename(a.input_prompt))[0]
# If you have a memory issue during denosing the prompt, try to denoise the prompt with cpu before TTS
# We will have a plan to replace a memory-efficient denoiser
if a.denoise_ratio == 0:
audio = torch.cat([audio.cuda(), audio.cuda()], dim=0)
else:
with torch.no_grad():
denoised_audio = denoise(audio.squeeze(0).cuda(), denoiser, hps_denoiser)
audio = torch.cat([audio.cuda(), denoised_audio[:,:audio.shape[-1]]], dim=0)
audio = audio[:,:ori_prompt_len] # 20231108 We found that large size of padding decreases a performance so we remove the paddings after denosing.
src_mel = mel_fn(audio.cuda())
src_length = torch.LongTensor([src_mel.size(2)]).to(device)
src_length2 = torch.cat([src_length,src_length], dim=0)This code snippet processes the loaded audio prompt for text-to-speech synthesis. It ensures:
- Single-channel audio support
- Resamples the audio to 16kHz if needed
- Handles normalisation based on the maximum amplitude if specified
The audio is then padded to accommodate the denoiser's hop size (interval between consecutive frames in a spectrogram) and undergoes denoising. Finally, you can compute the mel spectrogram of the processed audio for subsequent use in the text-to-speech synthesis model.
Denoising is not mandatory and depends on the requirements of the specific application or the quality of the input audio.
## TTV (Text --> W2V, F0)
with torch.no_grad():
w2v_x, pitch = text2w2v.infer_noise_control(token, token_length, src_mel, src_length2, noise_scale=a.noise_scale_ttv, denoise_ratio=a.denoise_ratio)
src_length = torch.LongTensor([w2v_x.size(2)]).cuda()
## Pitch Clipping
pitch[pitch<torch.log(torch.tensor([55]).cuda())] = 0
## Hierarchical Speech Synthesizer (W2V, F0 --> 16k Audio)
converted_audio = \
net_g.voice_conversion_noise_control(w2v_x, src_length, src_mel, src_length2, pitch, noise_scale=a.noise_scale_vc, denoise_ratio=a.denoise_ratio)
## SpeechSR (Optional) (16k Audio --> 24k or 48k Audio)
if a.output_sr == 48000 or 24000:
converted_audio = audiosr(converted_audio)
converted_audio = converted_audio.squeeze()
if a.scale_norm == 'prompt':
converted_audio = converted_audio / (torch.abs(converted_audio).max()) * 32767.0 * prompt_audio_max
else:
converted_audio = converted_audio / (torch.abs(converted_audio).max()) * 32767.0 * 0.999
converted_audio = converted_audio.cpu().numpy().astype('int16')
file_name2 = "{}.wav".format(file_name)
output_file = os.path.join(a.output_dir, file_name2)
if a.output_sr == 48000:
write(output_file, 48000, converted_audio)
elif a.output_sr == 24000:
write(output_file, 24000, converted_audio)
else:
write(output_file, 16000, converted_audio)This code snippet do the following:
- Handles the Text-to-Waveform (TTV) conversion and voice synthesis using the Hierarchical Speech Synthesizer
- Infers waveform and fundamental frequency (F0) from the input text
- Clips the pitch values, and then utilizes the Hierarchical Speech Synthesizer to generate 16k audio.pitch clipping is done by setting pitch values below a certain threshold i.e (log(55)) to zero
Using the SpeechSR module, the audio is processed for super-resolution. This is optional. The resulting audio is normalized and saved as a WAV file based on the specified output sample rate (16k, 24k, or 48k). The final output is stored in the specified output directory.
Run the application from the notebook
%cd HierSpeech_TTS
!python app.pyYou will see the output in Gradio like this:
Here you can give input in the form of text or you can upload the audio file or can record your own voice and then submit it and check the output.
Code Summary
This table summarizes all functions we implemented above with description:
Function | Description |
|---|---|
Main Function (tts) | Takes text, configuration (a), and models (hierspeech). Loads input audio, processes, and generates converted audio. |
Input Audio Processing | Load, resample, preprocess input audio. Add/remove padding. Optional denoising with a denoiser model |
Mel Spectrogram Extraction | Extract mel spectrogram representing spectral content. |
Text-to-W2V and F0 Inference (TTV) | Convert text to waveform (W2V) and fundamental frequency (F0). Pitch clipping based on a threshold. |
Voice Conversion & Noise Control | Hierarchical Speech Synthesizer converts W2V and F0 to 16k audio. Optional super-resolution for 24k or 48k output |
Saving Output | Save converted audio to a WAV file in the specified directory. |
Future directions
- This research work can be extended to speech-to-speech translation systems by introducing non-autoregressive generation as well as pre trained models can be used to introduce cross-lingual and emotion-controllable speech synthesis models
- Slow training speed and Relatively large model size (Compared with VITS) --> Future work: Light-weight and Fast training pipeline and much larger model...
- Could not generate realistic background sound --> Future work: adding audio generation part by disentangling speech and sound
- Could not generate a speech from a too long sentence because of the training setting. You can use GPUs with 80 GB for this
Closing thoughts
In this article we have learnt the contributions of HierSpeech++, and detailed how it has solved some of the problems facing speech generation in practice. We concluded that HierSpeech++ is a groundbreaking zero-shot speech synthesizer that not only addresses the drawbacks of LLM-based and diffusion-based models, but also operates efficiently and accuratel. To generate human-level quality synthetic speech, this model uses a text-to-vec framework, coupled with a highly-efficient speech super-resolution framework. The text-to-vec framework transforms textual inputs into a vectorized format. This enables a comprehensive and context-rich understanding of the linguistic content. This vectorized representation captures nuances related to prosody. This at last brings out more expressive and natural synthetic speech output.
F0 representation enriches the synthesized speech with prosodic feature (pitch, duration, loudness, speech rate, pauses). When a model understands these features well then it will enhance the naturalness of the speech where emotions can also be experienced in the speech.
This article has included the future directions which can help other researchers to enhance this model. So researchers or developers have an opportunity to experiment with HierSpeech++ and enhance its functionality.








