
Working with text data requires investing quite a bit of time in the data pre-processing stage. After that, you will need to spend more time building and training the natural language processing model. With Hugging Face, you don't have to do any of this.
Thanks to the Transformers library from Hugging Face, you can start solving NLP problems right away. The package provides pre-trained models that can be used for numerous NLP tasks. Transformers also supports over 100 languages. It also provides the ability to fine-tune the models with your data. The library provides seamless integration with PyTorch and TensorFlow, enabling you to easily switch between them.
In this article, we'll take a look at how you can use the Hugging Face package for:
- Sentiment analysis
- Question and answering
- Named-entity recognition
- Summarization
- Translation
- Tokenization
Bring this project to life
Sentiment analysis
In sentiment analysis, the objective is to determine if a text is negative or positive. The Transformers library provides a pipeline that can applied on any text data. The pipeline contains the pre-trained model as well as the pre-processing that was done at the training stage of the model. You ,therefore, don't need to perform any text preprocessing.
Let's kickoff by importing the pipeline module.
from transformers import pipelineThe next step is to instantiate the pipeline with a sentiment analysis pre-trained model. This will then download and cache the sentiment analysis model. In future requests, the cache model will be used. The other models work in a similar manner. The final step is to use the model to evaluate the polarity of some text.
classifier = pipeline("sentiment-analysis")
classifier("that was such bad movie")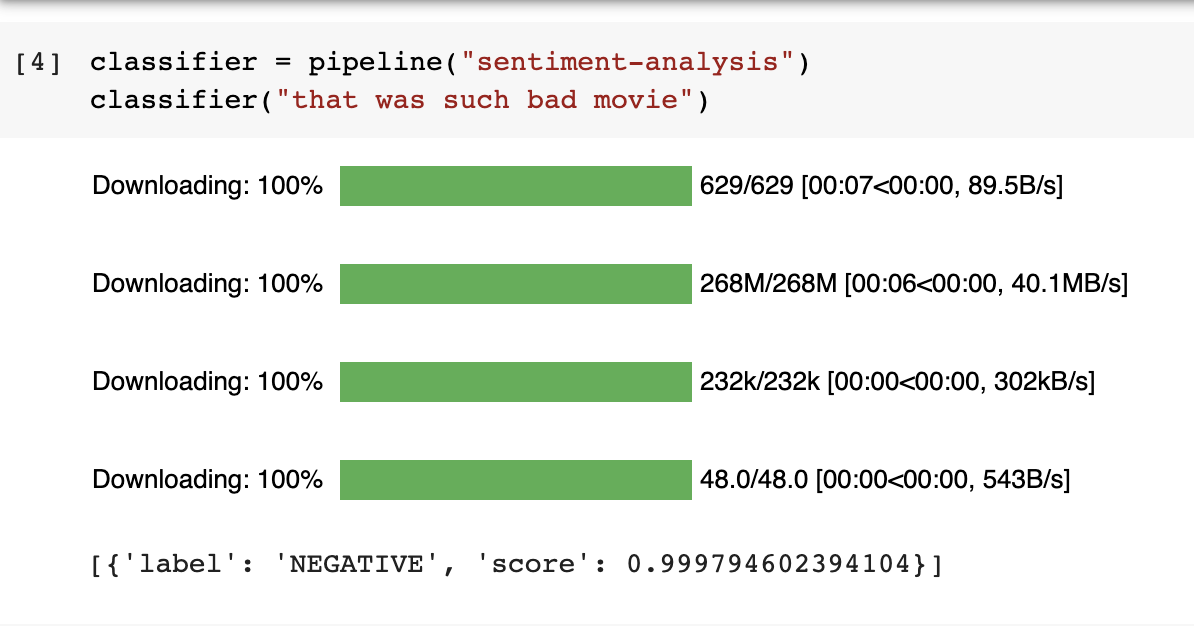
The model also returns the confidence score of the label. Most of the other models in the Transformers package also return a confidence score.
Question and answering
The Transformers package can also be used for a question answering system. This requires a context and a question. Let's start by downloading the question-and-answer model.
q_a = pipeline("question-answering")
The next move is to define a context and a question.
context = "paperspace is the cloud platform built for the future"
question = "Which is the cloud platform of the future?"The final step is to pass the question and the context to the question answering model.
q_a({"question": question, "context": context})
The model will return the answer and its start and end position in the provided context.

Named-entity recognition
Named-entity recognition involves extracting and locating named entities in a sentence. These entities include people's names, organizations, locations, etc. Let's start by downloading the named-entity recognition model.
ner = pipeline("ner")
Next, pass in a text and the model will extract the entities.
text = "Paperspace is located in the USA"
ner(text)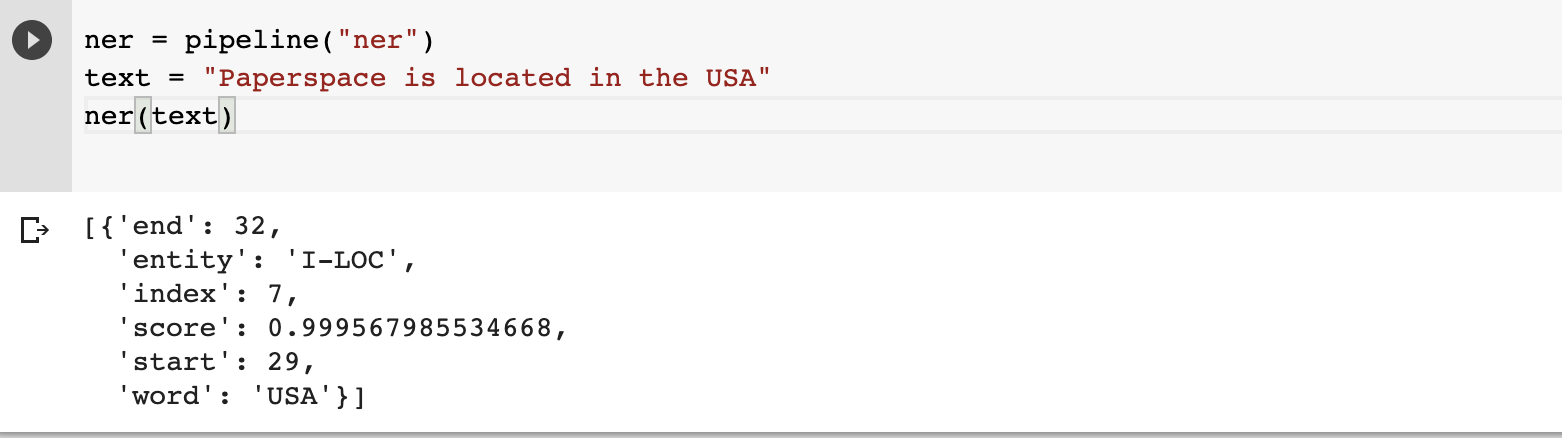
The model can also detect multiple entities in a sentence. It returns the ending point and the confidence score for each recognized entity.
ner = pipeline("ner")
text = "John works for Google that is located in the USA"
ner(text)
Summarization
Given a large piece of text, the summarization model can be used to summarize that text.
summarizer = pipeline("summarization")
The model requires the:
- text to be summarized
- maximum length of the summary
- minimum length of the summary
article = "The process of handling text data is a little different compared to other problems. This is because the data is usually in text form. You ,therefore, have to figure out how to represent the data in a numeric form that can be understood by a machine learning model. In this article, let's take a look at how you can do that. Finally, you will build a deep learning model using TensorFlow to classify the text."
summarizer(article, max_length=30, min_length=30)
Translation
Translation is a very important task when you have a product that is targeting people with different languages. For instance, you can use the Transformers package to translate from English to German and English to French. Let's start with the latter.
translator = pipeline("translation_en_to_fr")
After downloading the model, the next step is to pass the text to be translated.
text = "The process of handling text data is a little different compared to other problems. This is because the data is usually in text form. You ,therefore, have to figure out how to represent the data in a numeric form that can be understood by a machine learning model. In this article, let's take a look at how you can do that. Finally, you will build a deep learning model using TensorFlow to classify the text."
translator(text)
The English to German translation can be done in a similar manner.
translator = pipeline("translation_en_to_fr")
text = "The process of handling text data is a little different compared to other problems. This is because the data is usually in text form. You ,therefore, have to figure out how to represent the data in a numeric form that can be understood by a machine learning model. In this article, let's take a look at how you can do that. Finally, you will build a deep learning model using TensorFlow to classify the text."
translator(text)
Tokenization
Apart from using Hugging Face for NLP tasks, you can also use it for processing text data. The processing is supported for both TensorFlow and PyTorch. Hugging Face's tokenizer does all the preprocessing that's needed for a text task. The tokenizer can be applied to a single text or to a list of sentences.
Let's take a look at how that can be done in TensorFlow. The first step is to import the tokenizer.
from transformers import AutoTokenizer
text = "The process of handling text data is a little different compared to other problems. This is because the data is usually in text form. You ,therefore, have to figure out how to represent the data in a numeric form that can be understood by a machine learning model. In this article, let's take a look at how you can do that. Finally, you will build a deep learning model using TensorFlow to classify the text."
The next step is to instantiate the tokenizer from a pre-trained model vocabulary.
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
You can then use this tokenizer on the text. If you would like to return PyTorch tensors instead of TensorFlow's pass return_tensors="pt".
inputs = tokenizer(text, return_tensors="tf")

The tokenized sentence can also be converted to its original form using the decode function.
tokenizer.decode(inputs['input_ids'][0])
Hugging Face also allows padding of sentences to make them of the same length. This is done by passing the padding and truncation arguments. The sentences will be truncated to the maximum that the model can accept.
sentences = ["sentence one here",
" this is sentence two",
"sentence three comes here"]
tokenizer(sentences, padding=True, truncation=True, return_tensors="tf")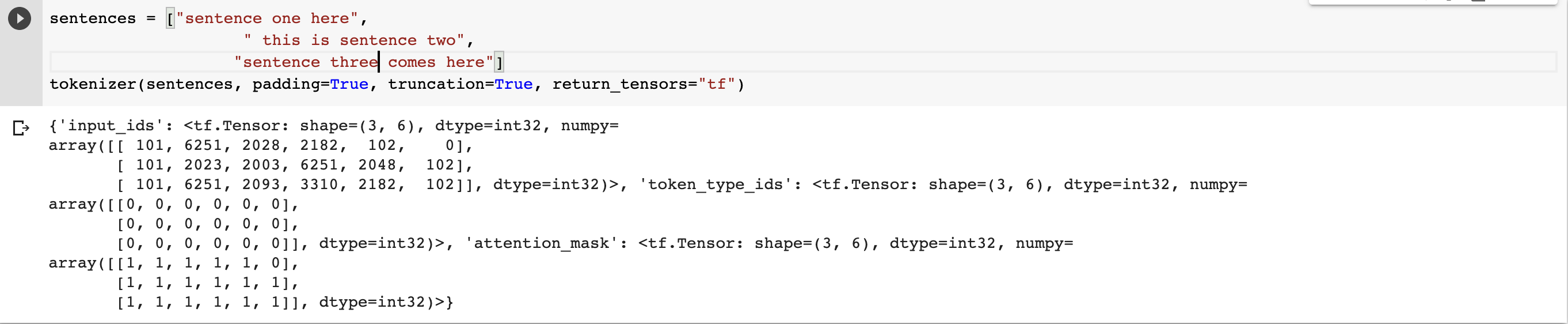
Final thoughts
In this article, you have seen how fast it is to use Hugging Face for various natural language processing tasks. You have also seen that the Transformer models achieve high accuracy on a variety of NLP tasks. You can also train the model on custom data. The Hugging Face platform can be used to search for new models as well as to share yours.
You can start playing with the library right away by making a copy of this notebook.








