
Activation functions have been a dominant region of research and discussion in the landscape of modern deep learning. To date, there have been various novel functions proposed which have seemed to work extremely well in different domains of deep learning, and specifically computer vision. However, xUnit offers a new perspective into designing activation units catering to specific tasks, as in the case of image restoration and image denoising. Specifically, in this article, we are going to take an in-depth look at the CVPR 2018 paper by Kligvasser et. al., titled "xUnit: Learning a Spatial Activation Function for Efficient Image Restoration". The paper revolves around introducing a novel block (or let's say a stack) of layers to replace the commonly used ReLU activation function to improve performance in the domain of image restoration and denoising.
First, we will take a look at the motivation behind xUnit and then dive right into analyzing its structure, followed by the results as presented in the paper along with its PyTorch code.
Table of Contents
- Motivation
- xUnit
- Code
- Results
- Conclusion
- References
Bring this project to life
Abstract
In recent years, deep neural networks (DNNs) achieved unprecedented performance in many low-level vision tasks. However, state-of-the-art results are typically achieved by very deep networks, which can reach tens of layers with tens of millions of parameters. To make DNNs implementable on platforms with limited resources, it is necessary to weaken the tradeoff between performance and efficiency. In this paper, we propose a new activation unit, which is particularly suitable for image restoration problems. In contrast to the widespread per-pixel activation units, like ReLUs and sigmoids, our unit implements a learnable nonlinear function with spatial connections. This enables the net to capture much more complex features, thus requiring a significantly smaller number of layers in order to reach the same performance. We illustrate the effectiveness of our units through experiments with state-of-the-art nets for denoising, de-raining, and super resolution, which are already considered to be very small. With our approach, we are able to further reduce these models by nearly 50% without incurring any degradation in performance.
Motivation
Over the years of research into architectural components in deep neural networks, activation functions have been an area of active discussion. ReLU has been by far the most successful activation function across the board, primarily in all tasks in the domain of computer vision. The reason behind this is essentially the simplicity and efficiency of ReLU which allows the activation unit to be as lightweight and straightforward as possible. Along with activation functions, several scaling factors have been an essential component in the exploration of pushing the state-of-the-art in terms of the performance of deep convolutional neural networks (CNNs). In this paper, the authors investigate making activation units more efficient rather than increasing the depth of the network. They do so by introducing a new activation mechanism called an xUnit, which is a layer with spatial and learnable connections. The xUnit computes a continuous-valued weight map, serving as a soft gate to its input.
The beauty of this paper is in the fact that since the novel xUnit activation unit is a learnable stack of layers that has a representative power, it allowed the authors to remove layers from predefined SOTA light-weight CNN models and make them nearly 50% cheaper while maintaining the same performance.
xUnit
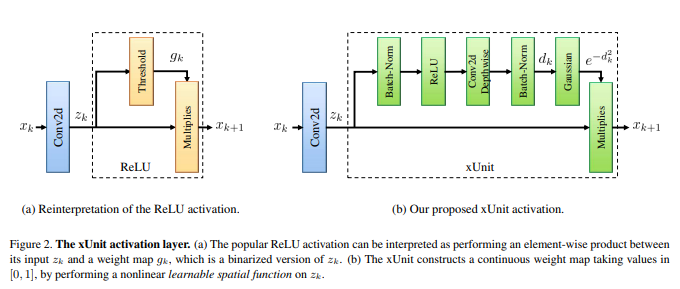
The above diagram shows the structural design of the xUnit activation unit. As discussed earlier, xUnit is a stack of different learnable layers rather than a straightforward replacement to the conventional ReLU activation function. The xUnit layer consists of the following layers (in order):
- Batch Normalization
- ReLU
- Conv 2D Depthwise
- Batch Normalization
- Gaussian
As seen here, ReLU is still retained in the xUnit, however it is embedded in a pipeline consisting of other learnable layers. The gaussian layer present in xUnit is more relevant to image denoising since it acts on an abstract level like a Gaussian blur filter. This can be removed when xUnit is needed to be used in other tasks like image classification or segmentation, however, it can be assumed that the Gaussian filter also has a favorable effect in terms of robustness and anti-aliasing.
Code
The following snippet is the structural definition of the three variants of xUnits, namely vanilla xUnit, slim xUnit, and dense xUnit, as defined in the official github repository of the paper:
import torch.nn as nn
class xUnit(nn.Module):
def __init__(self, num_features=64, kernel_size=7, batch_norm=False):
super(xUnit, self).__init__()
# xUnit
self.features = nn.Sequential(
nn.BatchNorm2d(num_features=num_features) if batch_norm else Identity(),
nn.ReLU(),
nn.Conv2d(in_channels=num_features, out_channels=num_features, kernel_size=kernel_size, padding=(kernel_size // 2), groups=num_features),
nn.BatchNorm2d(num_features=num_features) if batch_norm else Identity(),
nn.Sigmoid()
)
def forward(self, x):
a = self.features(x)
r = x * a
return r
class xUnitS(nn.Module):
def __init__(self, num_features=64, kernel_size=7, batch_norm=False):
super(xUnitS, self).__init__()
# slim xUnit
self.features = nn.Sequential(
nn.Conv2d(in_channels=num_features, out_channels=num_features, kernel_size=kernel_size, padding=(kernel_size // 2), groups=num_features),
nn.BatchNorm2d(num_features=num_features) if batch_norm else Identity(),
nn.Sigmoid()
)
def forward(self, x):
a = self.features(x)
r = x * a
return r
class xUnitD(nn.Module):
def __init__(self, num_features=64, kernel_size=7, batch_norm=False):
super(xUnitD, self).__init__()
# dense xUnit
self.features = nn.Sequential(
nn.Conv2d(in_channels=num_features, out_channels=num_features, kernel_size=1, padding=0),
nn.BatchNorm2d(num_features=num_features) if batch_norm else Identity(),
nn.ReLU(),
nn.Conv2d(in_channels=num_features, out_channels=num_features, kernel_size=kernel_size, padding=(kernel_size // 2), groups=num_features),
nn.BatchNorm2d(num_features=num_features) if batch_norm else Identity(),
nn.Sigmoid()
)
def forward(self, x):
a = self.features(x)
r = x * a
return rResults
Although the paper's results are primarily focused on the domain of super-resolution and image denoising, one can use xUnits to replace the conventional standard ReLU activation units in their deep neural network architectures and observe a steady performance improvement – however, at the cost of increased computational requirements. The results shown below highlight the efficiency and capabilities of xUnits as showcased in the paper.
xUnits Efficiency Analysis
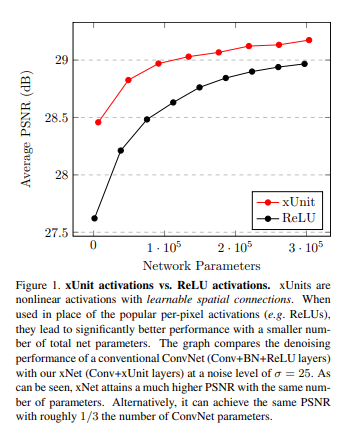
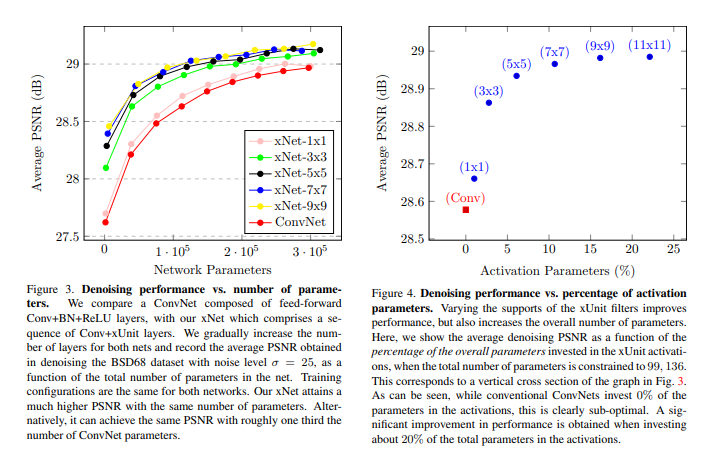
Image Denoising

Image Reconstruction via Artifacts Removal
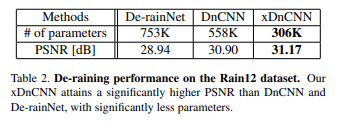

Super-Resolution

Ablation studies based on design and activation maps visualization
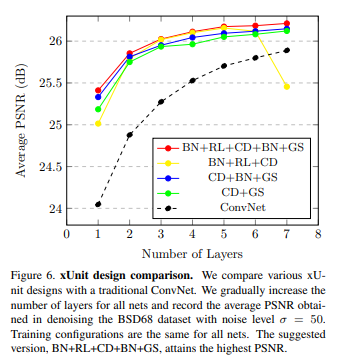

Conclusion
xUnits are a solid substitute for conventional activation functions for image reconstruction tasks, however they lack a clear identity and sort of feel like an impostor in the pool of natural activation functions, since they're not a native non-linear function but rather a sequential stack of different layers and components commonly used in deep neural networks. xUnits also add a significantly higher amount of compute, but the verdict on whether that extra computational overhead is justified with the performance boost that xUnit can obtain lies with the users.











