
Bring this project to life
Introduction
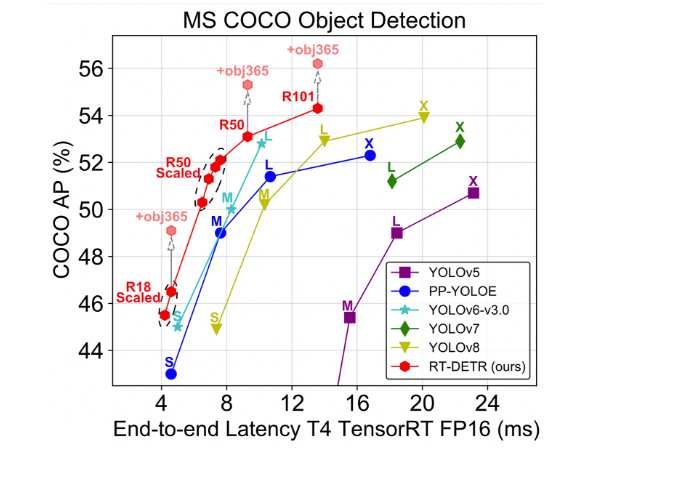
In this article we introduce Real-Time DEtection TRansformer (RT-DETR), the first real-time end-to-end object detector addressing the issue of the high computational cost existing with the DETRs. The recent research paper DETRs Beat YOLOs on Real-Time Object Detection, a Baidu Inc., successfully analyzed the negative impact of non-maximum suppression (NMS) on real-time detectors and proposed an efficient hybrid encoder for multi-scale feature processing. The IoU-aware query selection enhances performance. RT-DETR-L achieves 53.0% AP on COCO val2017 at 114 FPS, outperforming YOLO detectors. RT-DETR-X achieves 54.8% AP at 74 FPS, surpassing YOLO in both speed and accuracy. RT-DETR-R50 achieves 53.1% AP at 108 FPS, outperforming DINO-DeformableDETR-R50 by 2.2% AP in accuracy and 21 times in FPS.
Object detection is a task of identifying or localizing certain objects in an image or video. Object detection models have various practical applications across different domains such as:
- Autonomous Vehicles: Object detection is crucial for enabling autonomous vehicles to identify and track pedestrians, vehicles, traffic signs, and other objects on the road.
- Retail Analytics: In retail, object detection helps track and analyze customer behavior, monitor inventory levels, and reduce theft through the identification of suspicious activities.
- Facial Recognition: Object detection is a fundamental component of facial recognition systems, used in applications such as access control, identity verification, and security.
- Environmental Monitoring: Object detection models can be applied in environmental monitoring to track and analyze wildlife movements, monitor deforestation, or assess changes in ecosystems.
- Gesture Recognition: Object detection is used to interpret and recognize human gestures, facilitating interaction with devices through gestures in applications like gaming or virtual reality.
- Agriculture: Object detection models can assist in crop monitoring, pest detection, and yield estimation by identifying and analyzing objects such as plants, fruits, or pests in agricultural images.
However, these are just a few there are many more use cases where object detection plays a crucial role.
Recently, transformer-based detectors have achieved remarkable performance by utilizing Vision Transformers (ViT) to process the multiscale features effectively by separating intra-scale interaction and cross-scale fusion. It is highly adaptable, allowing for the flexible adjustment of inference speed through various decoder layers without the need for retraining.
What is new in RT-DETR
To enable real-time object detection, a streamlined hybrid encoder substitutes the original transformer encoder. This redesigned encoder efficiently manages the processing of multi-scale features by separating intra-scale interaction and cross-scale fusion, allowing for effective feature processing across different scales.
To further enhance the performance, IoU-aware query selection is introduced during the training phase that offers higher-quality initial object queries to the decoder through IoU constraints. Additionally, the proposed detector allows for the convenient adjustment of inference speed using different decoder layers, leveraging the DETR architecture's decoder design. This feature streamlines the practical application of the real-time detector without requiring retraining. Hence becomes the new SOTA for real-time object detection. Real-time object detectors, which can be roughly classified into two categories: anchor-based and anchor-free.
- Anchor-Based Object Detectors:
- In anchor-based detectors, predefined anchor boxes or regions of interest are used to predict the presence of objects and their bounding boxes.
- These anchor boxes are generated at various scales and aspect ratios across the image.
- The detector predicts two main components for each anchor box: class probabilities (is there an object or not) and bounding box offsets (adjustments to the anchor box to tightly fit the object).
- Popular examples of anchor-based detectors include Faster R-CNN, R-FCN (Region-based Fully Convolutional Networks), and RetinaNet.
- Anchor-Free Object Detectors:
- Anchor-free detectors do not rely on predefined anchor boxes. Instead, they directly predict bounding boxes and object presence without the need for anchor boxes.
- These detectors often employ keypoint-based or center-ness prediction methods.
- Keypoint-based methods identify key points (corners, center, etc.) and use them to estimate object bounding boxes.
- Center-ness prediction focuses on determining the likelihood of a pixel being the center of an object, and bounding boxes are constructed based on these centers.
- Popular examples of anchor-free detectors include CenterNet and FCOS (Fully Convolutional One-Stage).
End to end object detectors first proposed by Carion et al.an object detector based on Transformer, named DETR (DEtection TRansformer) has successfully attracted significant attention due to its distinctive features. DETR removes the need for hand-designed anchor and Non-Maximum Suppression (NMS) components found in traditional detection pipelines. Instead, it utilizes bipartite matching and directly predicts one-to-one object sets. This approach simplifies the detection pipeline, addressing the performance bottleneck associated with NMS. However, DETR faces challenges, including slow training convergence and difficulties in optimizing queries.
Use of NMS
Non-Maximum Suppression (NMS) is a widely used post-processing algorithm in object detection. It addresses overlapping prediction boxes by filtering out those with scores below a specified threshold and discarding lower-scored boxes when their Intersection over Union (IoU) exceeds a second threshold. NMS iteratively processes all boxes for each category, making its execution time dependent on the number of input prediction boxes and the two hyperparameters: score threshold and IoU threshold.
Model Architecture
The RT-DETR model comprises a backbone, a hybrid encoder, and a transformer decoder with auxiliary prediction heads. The architecture leverages features from the last three stages of the backbone {S3, S4, S5} as input to the encoder, which uses a intra-scale interaction and cross-scale fusion to transform multi-scale features into an image feature sequence. IoU-aware query selection is then applied to choose a fixed number of image features from the encoder output as initial queries for the decoder. The decoder, along with auxiliary prediction heads, iteratively refines these queries to generate object boxes and confidence scores.
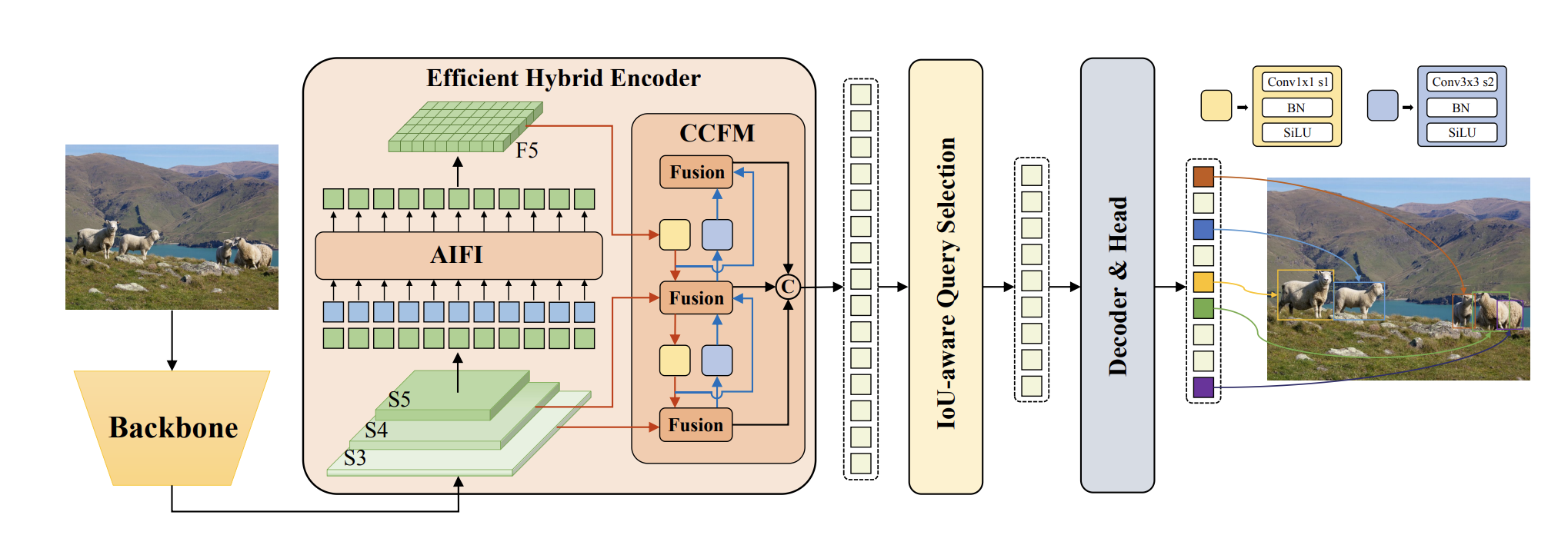
A novel Efficient Hybrid Encoder is proposed for RT-DETR. This encoder consists of two modules, the Attention-based Intrascale Feature Interaction (AIFI) module and the CNN based Cross-scale Feature-fusion Module (CCFM). Further, to generate a scalable version of RT-DETR , the ResNet backbone was replaced with HGNetv2.
Dataset Used
The model was trained using the COCO train2017 and validated on COCO val2017 dataset. Further ResNet and HGNetv2 series pretrained on ImageNet with SSLD from PaddleClas1 as the backbone was used in the model. For IoU-aware query selection, the top 300 encoder features are chosen to initialize the object queries of the decoder. The training strategy and hyperparameters of the decoder closely aligns with the DINO approach. The detectors were trained using AdamW optimizer and data augmentation was conducted with random {colour distort, expand, crop, flip, resize} operations.
Comparisons with other SOTA model
The RT-DETR, when compared to other real-time and end-to-end object detectors, successfully demonstrates superior performance. Specifically, RT-DETR-L achieves 53.0% Average Precision (AP) at 114 Frames Per Second (FPS), and RT-DETR-X achieves 54.8% AP at 74 FPS. These results outperform current state-of-the-art YOLO detectors in terms of both speed and accuracy. Additionally, RT-DETR-R50 achieves 53.1% AP at 108 FPS, and RT-DETR-R101 achieves 54.3% AP at 74 FPS, surpassing the state-of-the-art end-to-end detectors with the same backbone in both speed and accuracy. RT-DETR allows for flexible adjustment of inference speed by applying different decoder layers, all without requiring retraining. This feature enhances the practical applicability of the real-time detector.
Ultralytics RT-DETR Pre-trained Model
Ultralytics is committed to the development of top-notch artificial intelligence models globally. Their open-source projects on GitHub showcase state-of-the-art solutions across a diverse array of AI tasks, encompassing detection, segmentation, classification, tracking, and pose estimation.
Ultralytics Python API provides pre-trained RT-DETR models with different scales:
- RT-DETR-L: 53.0% AP on COCO val2017, 114 FPS on T4 GPU
- RT-DETR-X: 54.8% AP on COCO val2017, 74 FPS on T4 GPU
The below example code snippet offers straightforward training and inference illustrations for RT-DETRR using ultralytics pre-trained model. For comprehensive documentation on these modes and others, refer to the pages dedicated to Predict, Train, Val, and Export in the documentation.
Use pip to install the package.
Bring this project to life
!pip install ultralyticsfrom ultralytics import RTDETR
# Load a COCO-pretrained RT-DETR-l model
model = RTDETR('rtdetr-l.pt')
# Display model information (optional)
model.info()
# Train the model on the COCO8 example dataset for 100 epochs
results = model.train(data='coco8.yaml', epochs=100, imgsz=640)
# Run inference with the RT-DETR-l model on the 'bus.jpg' image
results = model('path/to/bus.jpg')
Let us check the inference on an image and video saved in the local folder!
results = model.predict('https://m.media-amazon.com/images/I/61fNoq7Y6+L._AC_UF894,1000_QL80_.jpg', show=True)
results = model.predict(source='input_video/input_video.mp4', show=True)Conclusions
In this article we discussed Baidu's Real-Time Detection Transformer (RT-DETR), the model stands out for its advanced end-to-end object detection, delivering real-time performance without the compromise in the accuracy. RT-DETR harnesses the capabilities of vision transformers to effectively handle multiscale features. The model's key features includes Efficient Hybrid Encoder, IoU-aware Query Selection, and Adaptable Inference Speed. We use the pre-trained model from ultralytics to demonstrate the performance of the model on images and videos. We recommend our readers to click the link and get a hands on experience of this model using the Paperspace platform.
We hope you enjoyed reading the article!
References

 lyuwenyu
lyuwenyu











