
Large language models have shown promise in a number of different application areas, including general problem solving, code generation, and instruction comprehension. As opposed to the earlier models' reliance on direct answer strategies, the current body of work favors linear reasoning approaches by decomposing problems into sub-tasks or using external processes to alter token generation. The Algorithm of Thoughts (AoT) is a new prompting approach that, with few queries, can go along reasoning paths in large language models. The researchers introduce AoT's architecture, explore its benefits over conventional prompting approaches, and emphasize its capacity to inject its own "intuition" to create effective search outcomes.
With this in mind, our goal is to dramatically reduce the query counts employed by contemporary multi-query reasoning methods while maintaining performance for tasks necessitating adept use of world knowledge, thereby steering a more responsible and proficient use of AI resources.
Some related works
Standard prompting: Common in large language models (LLMs), standard prompting (also known as input-output prompting) involves providing the model with a small number of input-output examples of the task before getting a response for a test sample. This approach is universal and does not need any particular prompting technique. However, when compared to more advanced prompting approaches, the performance of ordinary prompting is generally subpar.
Chain of though prompting: In Chain of Thought, large language models get shown examples where a query x gets answered through a series of intermediate reasoning steps c1, c2, c3 etc until it reaches the final answer y. It looks like x -> c1 -> c2 -> c3 ->. . and -> cn -> y. By mimicking these examples the model can break down the solution into simpler linear steps to get better at solving reasoning problems.
Self-consistency (Wang et al. 2022) is a widely used decoding strategy aimed at generating a variety of reasoning paths by choosing the final answer through a majority vote, though this necessitates additional generations.
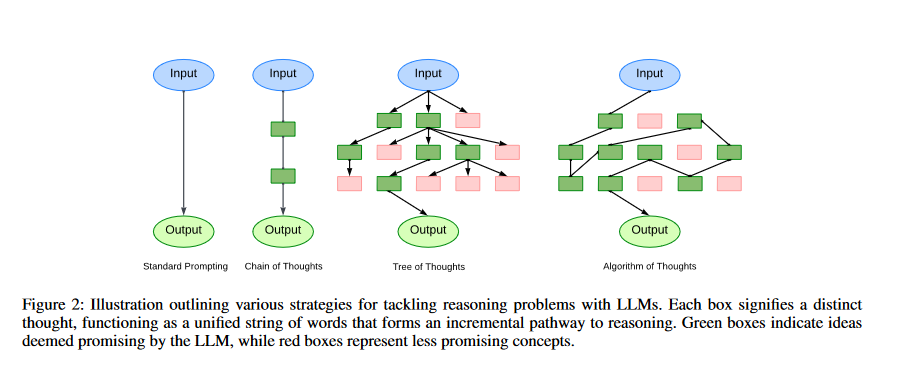
Unlike Chain of Thought's direct step-by-step progression, the idea of our researchers looks more at how creative and exploratory these models can be. They see the c1, c2, c3 steps not as just steps to the answer but as a mutable path like an algorithm searching around, with room to explore, adjust, and move in nonlinear ways.
Least-to-Most prompting: By using the field of educational psychology (Libby et al., 2008), L2M prompting guides the LLM to break down the task at hand into more manageable sub problems. A sequential approach is used to solving the problems, with each solution being added to the previous one before moving on (Zhou et al. 2022; Drozdov et al. This method of organized delineation is best suited for situations with a clear-cut structure, but it has the added benefit of aiding in more generalization. However, its rigidity becomes obvious when tasks are intertwined with their decomposition complexities (such as in games of 24). In contrast, AoT not only emphasizes the current subproblem (as seen in Fig. 1). It also lets you take a more thoughtful approach, entertaining different options for each sub-problem, while still maintaining efficiency even with minimal prompts.

Tree of Thoughts (ToT): The coverage of the thought space is constrained by linear reasoning pathways from CoT or L2M in cases where each subproblem has several plausible possibilities to explore. The decision tree can be explored using external tree search algorithms (e.g., BFS, DFS) (Yao et al. 2023), taking into account potential decisions for each subproblem. The evaluation features of LLMs can also be used to guide the search by eliminating useless nodes. One of the shortcomings of ToT is that it often requires hundreds of LLM searches to solve a single problem. The solution to this problem is to generate the entire thought process within a single context.
Algorithm of Thoughts
The Algorithm of Thought (AoT) is an innovative prompting technique that uses algorithmic reasoning paths to enhance the reasoning abilities of Large Language Models (LLMs). This technique incorporates the methodical and ordered nature of algorithmic approaches in an effort to simulate the layered exploration of ideas seen in human thinking.
As a first step in the AoT process, the LLM is shown algorithmic examples that represent the entire spectrum of investigation, from brainstorming to verified results. The LLM might use these examples as a roadmap for tackling complex problems by breaking them down into smaller subproblems. The LLM uses algorithmic reasoning to systematically test hypotheses and get the optimal solution.
The key strength of the AoT process lies in its ability to expand the scope of the investigation with few queries. In contrast to the multiple queries required by conventional query techniques, AoT requires only one or a small number of queries to produce comparable results. As a result, computing power and storage requirements are reduced, making this method more practical and economical.
The AoT method makes use of LLMs' recursive nature. As the LLM generates answers, it refers back to previous intermediate steps to eliminate implausible solutions and fine-tune its reasoning process. Because of its repeated generation cycle, the LLM can learn from its past mistakes and improve upon its own strategies, eventually outperforming the algorithm itself. LLMs can improve their reasoning in many contexts by adopting the AoT process. AoT is an organized and methodical method that can help with tasks that need mathematical reasoning and logical problem solving. Here are the key component of the Algorithm of Thoughts (AoT) approach:
Decomposition into Subproblems
The Algorithm of Thought (AoT) relies heavily on decomposition into smaller, more manageable chunks. The process involves breaking down a large problem into smaller chunks that can be tackled independently. This decomposition is critical for large language models (LLMs) to enable efficient reasoning and solution finding.
There are several considerations that must be made while breaking down a problem. The first step is to consider the dependencies among individual steps. Effective decomposition requires an appreciation for the interdependencies between the subproblems and the contributions of their solutions to the whole.
Second, it's important to think about how simple it will be to solve each subproblem individually. Some of the subproblems may be simple and easy to answer, while others may need more nuanced reasoning or more data. The goal of the decomposition should be to guarantee that each of the subproblems is manageable in scope and complexity.
Proposing Solutions to Subproblems
In the Algorithm of Thought (AoT) process, the generation of solution proposals for specific subproblems occurs seamlessly. This continuous process offers several advantages. First, it reduces computational load and model queries by eliminating the need to evaluate each solution separately. Additionally, it promotes efficient solution generation. Secondly, instead of repeatedly pausing and restarting the token sampling process, the large language model (LLM) can generate complete sequences of solutions. The probabilities of individual tokens or token groups may not always accurately reflect the LLM's ability to genetare cohesive and meaningful sequences, which our method takes into account.
A simple illustration is found in Fig. 4. When evaluated independently, the second-most probable token for our inaugural number is ‘1’—not qualifying as prime. But, when generation remains unbroken, the derived sequence is correct.

Gauging the Promise of a Subproblem
In the Algorithm of Thought (AoT), evaluating the potential of a subproblem is crucial. It entails assessing the viability and potential of each subproblem within the context of the overall issue domain. The large language model (LLM) may efficiently allocate resources by prioritizing the research of promising subproblems.
When determining a subproblem's potential, it's important to take into account a number of elements. The LLM must first determine whether or not the side issue is important to the main issue. Is the subproblem essential to fixing the main issue ? The LLM can better allocate its investigation time and resources by understanding the relative relevance of each subproblem.
Second, the LLM should determine how complex the subproblem is. Is it a simple problem that can be rapidly addressed, or does it call for complex analysis and computation? The LLM can select the best strategy for tackling the subproblem and distribute resources accordingly after evaluating its complexity.
The LLM should also think about the consequences of resolving the subproblem. When this particular will be resolved, will the larger problem-solving process will advance significantly? . The LLM can better allocate resources and focus on the most pressing problems if it has a clear picture of the likely effect.
Backtracking to a Preferable Juncture
The Algorithm of Thought (AoT) method allows for backtracking to be used when researching potential solutions to subproblems. The large language model (LLM) can retrace its steps to a prior subproblem to try a different approach if the current one does not provide desirable results. The iterative process of going back and forth between possible solutions can improve the LLM's reasoning and solution quality.
The decision of which node to explore next (including retracing to a prior node) inherently depends on the selected tree-search algorithm. Some studies (like Yao aet al. 2023) baked in special rules to guide the search, but that limits how useful their methods are - you gotta customize everything. In their work, the researchers stick to depth-first search with some pruning thrown in and the goal is to have child nodes hang close together, so the AI model focuses on local features instead of getting distracted by distant nodes.
Methodology and Experimental Results
Various problem-solving tasks, including the game of 24 and mini crosswords puzzles, are used in the experiments that form the backbone of the study's approach. The authors evaluate AoT's efficiency by comparing it to those of established methods like CoT and ToT. Based on the data, it's clear that AoT is superior than traditional prompting and CoT, while also performing similarly to ToT in certain cases. In addition to showcasing AoT's capabilities, the research reveals areas for improvement and suggests ways in which manual resolution can be necessary to get a satisfactory outcome.
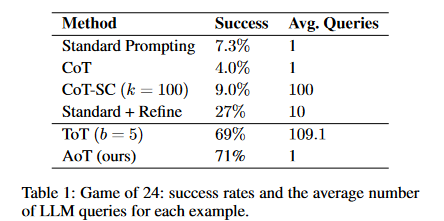
- From Table 1, it’s evident that standard prompting combined with CoT/-SC significantly lags behind tree search methods when used with LLMs.
- The “Standard + Refine” result, showing a 27% success rate, is referenced from (Yao et al. 2023). This method involves iteratively asking the LLM (up to 10 iterations) to refine its answer if the initial one is incorrect. Meanwhile, ToT is limited to a maximum of 100 node visits, translating to several hundred LLM queries for each example.
- Remarkably, AoT achieves its results with just a single query. Despite reducing the number of requests by more than a factor of 100, AoT still outperforms ToT in this task
Implications and Significance
There are major repercussions for business and AI research stemming from the findings of the research paper. The AoT method shows promise as a means to improve LLMs' problem-solving skills, allowing them to take on challenging tasks that require reasoning and exploration. By enhancing LLMs' capacity for generalization, AoT boosts their efficiency in tasks as diverse as natural language processing, data analysis, and creative writing. The research also emphasizes the possibility of AoT in cutting down on computing expenses and increasing the effectiveness of LLM-based systems.
Limitations
However, there are certain limitations to bear in mind. While the publication does include experimental data comparing AoT with established methods, more research into a larger sample size and a wider range of problem domains would strengthen the case for AoT's efficiency. The paper also notes that, there will be cases when AoT will require human intervention, suggesting that it may not be able to solve all problems on its own. Methods to improve AoT autonomy and reduce the need for human intervention might be investigated in future studies.
In addition, the computational costs of implementing AoT are briefly mentioned, whereas the research focuses largely on AoT's performance in problem-solving tasks. Research on the computational efficiency of AoT and possible enhancements to lower resource requirements might be conducted in light of the growing demand for effective AI systems.
Conclusion
The Algorithm of Thoughts (AoT) method has important implications in the field of NLP and AI. This research paper provide a unique approach to improve idea exploration in LLMs by combining recursive exploration with algorithmic examples. The experimental findings show that AoT is successful in training LLMs to generalize across different problem-solving tasks.
Reference
Algorithm of Thoughts: Enhancing Exploration of Ideas in Large Language Models https://arxiv.org/abs/2308.10379








