Text-to-Image (T2I) models that can generate realistic images from text have become a hot topic. They can make all kinds of wacky and creative images using AI! However, existing T2I models only support limited languages, hindering their global expansion and leaving non-English users under-served.
Some researchers tried to fix this issue by creating a new multilingual T2I model called AltDiffusion, that can handle 18 different languages and they trained it using some clever tricks like knowledge distillation and combining it with an English-only model that was already pretrained. It went through a two-step schema to get it aligned with concepts in different languages and improve the image quality.
The goal was to create something that could produce convincing pictures from text in many different tongues around the world, not just English. That way, more people could tap into the power of AI image generation. More languages means more access and more fun! It will be exciting to see how international users interact with this technology.
Multilingual CLIP
Researchers have sought to broaden CLIP's linguistic capabilities beyond English by developing multilingual CLIP models through knowledge distillation and using the XLM-R multilingual model. The purpose of Multilingual CLIP is to compute the cosine similarity score between the genetaed images and the multilingual text.
It is used to determine whether or not the generated visuals accurately reflect the supplied text in a variety of languages.
It is a statistic that is used in the assessment of AltDiffusion's overall capacity to generate T2I in several languages.
Enhance Language Capability of the Text Encoder
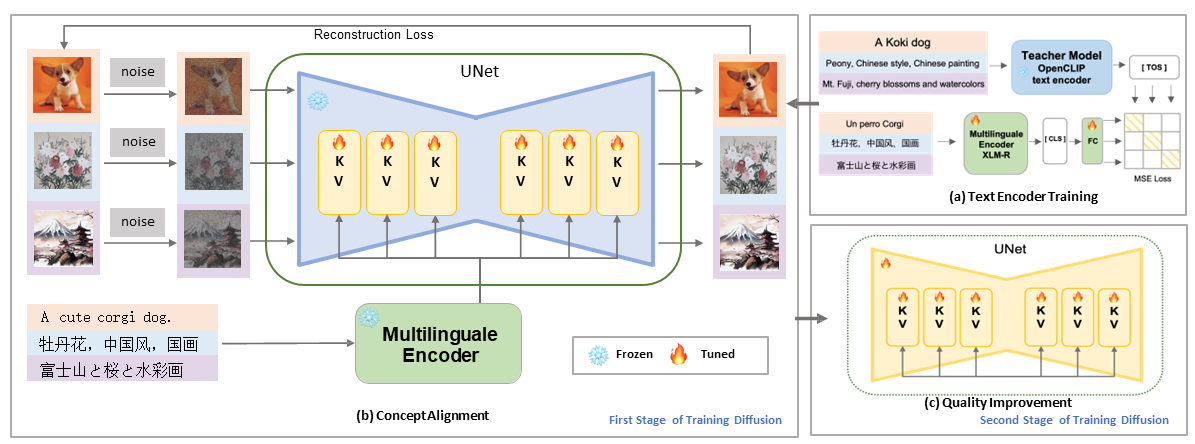
Based on the knowledge distillation, the researchers retrain the text encoder in the style of AltCLIP(Chen et al. 2022). The Open- CLIP text encoder (Cherti et al. 2022) is the teacher model and XLM- R (Conneau et al. 2019) is the student model, as illustrated in Figure 2(a).
Given parallel prompts (textenglish, textotherlanguage), the textenglish in-
put is fed into the teacher model, and the textotherlanguage input is fed into the student model.
They perform this by minimizing the Mean Squared Error(MSE) between the teacher model's [T OS] embedding and the student model's [CLS] embedding.
A fully connected network maps the outputs of XLM-R and the OpenCLIP text encoder penultimate layer to the same dimensionality. The trained model yields a multilingual text encoder with an embedding space similar to that of OpenCLIP.
Enhance Language Capability of the UNet
After training the text encoder, its parameters are then frozen and put into a pre-trained English-only off-the-shelf diffusion model. The authors make use of a two-stage training schema, which includes concept alignment and quality improvement stage, in order to turn a diffusion model that was previously only available in English into one that is multi-lingual.
Concept Alignment Stage
The purpose of this step is to align the embedding space between the text encoder and UNet in order to restore the relationship between the text and the images. LAION(Schuhmann et al. 2022) is a massive multilingual dataset used for training. According to preliminary research(Gandikota et al. 2023), the cross-attention mechanism of the diffusion model is vital in establishing a suitable match between the text and the images. For this reason, as shown in Figure 2(b), the authors first freeze the UNet's multilingual text encoder, autoencoder, and the most of its parameters, and then, they train the cross-attention module's K, V matrix with the denoising diffusion objective(Ho, Jain, and Abbeel 2020):
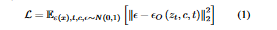
- The loss function L represents what the AltDiffusion model is trying to optimize during training.
- Ks(x),t,se∼N(0,1) is a function that computes how similar the input text x is to the generated image at time step t.
- ∥ε−εO(zt,C,t)∥22 measures the distance between the noise vector ε and the generator network's output εO, which takes the latent code zt, the conditioning info C and the time step t as inputs.
- ε is random noise added to make the generated images diverse and stochastic and εo comes from the generator network, and depends on zt, C, and t.
- zt is sampled from a standard distribution like a Gaussian distribution and input to the generator to genetate the image.
- C is the conditioning information from the text encoder that guides the image generation based on the text.
- t is the time step at which the image is generated. AltDiffusion makes the image gradually over multiple time steps.
Previous research(Rombach et al. 2022) reveals that compressing images from 512x512 to 256x256 causes only little loss of semantic information, with some undetectable features being lost in the process. To achieve their goal of harmonizing the semantic information across modalities, the authors reduce the image resolution to 256x256 at this step to speed up training while
minimizing computational costs.
Quality Improvement Stage
The researchers used a strategy of continuous learning in this stage. They loaded the checkpoint from the first stage and fine-tuned all the parameters of the UNet using the same objective function as in Equation 1.
They trained the model on high-quality multilingual datasets of aesthetics at 512x512 to improve the generative quality of the images generated by the model. They also dropped 10% of text inputs following the approach from SD(Rombach et al. 2022) for classifier-free guidance(Ho and Salimans 2022). This helps when computing the final noisy score during inference. ϵθ (zt, c, t) is obtained by
a combination of conditioned score ϵθ (zt, c, t) and unconditioned score ϵθ (zt, t), which is formalized in the following equation:
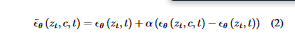
where α > 1 is a scale weight of condition. With the completion of the second stage, we finally obtain a multilingual T2I diffusion model that meet the needs of users across different linguistic backgrounds.
Exemple:Let's say we've got this latent code zt that represents the text "a red apple". We want to use a text-to-image diffusion model to generate a bunch of diverse images of a red apple from that code. To get diverse images, we'll add some random noise ε to zt. The diffusion time step t controls how much noise we add - higher t means more noise.
Here is how we generate the noise: we've got a function c~θ that takes in zt, ε, and t. The function generates a new noise vector by scaling the difference between a learned noise vector ϵθ and a standard normal noise vector ϵ0 by a learnable scaling factor a and adding it to ϵ0.
Training Data
In order to train AD, the authors used only image-text pairings obtained from LAION (Schuhmann et al. The specifics of these paired visuals and texts are as follows:
LAION 5B has three different datasets: LAION2B (English), LAION2B (Multiple Languages), and LAION1B (Non-English).
- LAION2B-en and LAION2B-multi are a couple of datasets with a ton of image-text pairs. LAION2B-en has around 2. 32 billion pairs in English, while LAION2B-multi has about 2. 26 billion pairs in over 100 languages beyond English.
- In the first training stage, the researchers filtered 1. 8 billion data in eighteen languages from LAION2B-multi and combined it with LAION2B-en.
- lAION Aesthetics is another dataset with high-quality subsets from LAION 5B. An Aesthetics Predictor was trained using LAION to predict how aesthetically pleasing images are on a 1-10 scale, with higher scores being better.
- The Aesthetics Predictor was then used to filter the data in the second training stage. In this stage they filtered eighteen languages from the LAION Aesthetics and LAION Aesthetics V1-multi datasets where the predicted aesthetics score was higher than seven. The filtered data was then used to improve the multilingual abilities of the AltDiffusion model.
Evaluation Benchmark
To evaluate the capability of AD to generate images and capture culture-specific concepts of different languages, we introduce two datasets: Multilingual-General-18(MG-18) for generation quality evaluation and Multilingual-Cultural-18(MC-18) for culture-specific concepts evaluation.
Multilingual e-General-18 (MG-18) is a big and high-quality dataset with 7,000 image-text pairs in 18 languages. The creators expanded the existing XM 3600 dataset with nice images from WIT using two main steps.
- First, they ran the images through an Optical Character Recognition system to filter out any with more than five words. Their thinking was that images with too much text tend to be documents image, which don't really show off how well an image-to-text model can generate captions .
- They used AltCLIP to calculate similarity scores between each image and its caption. They kept any pairs scoring higher than 0. 2 . The end result is a rich new dataset spanning multiple languages, with diverse images appropriately matched to descriptive captions.
Multilinguale-Cultural-18(MC-18) One of the important capabilities of multilingual T2I models is to understand culture-specific concepts of different languages.
Implementation details
- The model uses an AdamW optimizer, which is a version of Adam that adds in weight decay regularization. This helps avoid overfitting.
- The learning rate was set to 1e-4, which is a small value that let the model slowly converge rather than overshoot the optimal solution.
- The model was trained on 64 NVIDIA A100-SXM4-40GB GPUs, which are high-performance graphics processing units designed for deep learning applications.
- For the text part they used a multilingual encoder. This was trained through knowledge distillation, where you can transfer knowledge from a larger, complex teacher model to a smaller, simpler student.
- During training, they froze the text encoder parameters, so they are not updated.
- The model was trained with a continuous learning approach, which involves training the model in multiple stages to improve its performance gradually. In the concept align stage, they initialized it off an D v2.1 512-base-ema3 checkpoint. This was a pre-trained starting point. The batch size here was 3,072, which is the number of training examples used in each iteration of the training process.And the resolution in the concept align stage was 256x256 which corresponds to the image size.
- The training process took around 8 days to complete during the concept align stage. In the quality improvement stage, the model was trained using a larger batch size of 3,840 and higher 512x512 resolution. That training step took about 7 days or so.
- After the quality improvement stage, the model was trained for 150000 more steps using classifier-free guidance learning. That meant randomly throwing out 10% of the text to help the model get better at generating images without relying on a classifier.
- The teacher model used for knowledge distillation was OpenCLIP ViT-H-144, which is a huge, pre-trained model used to transfer knowledge over to the smaller, simpler model used in the AltDiffusion model.
- The model uses Xformer and Efficient Attention to save on memory and speed up training which are techniques that help the model deal with largeamounts of data efficiently.
- The decay of EMA is 0. 9999, which controls how fast the model updates its estimates of the mean and variance in the training data.
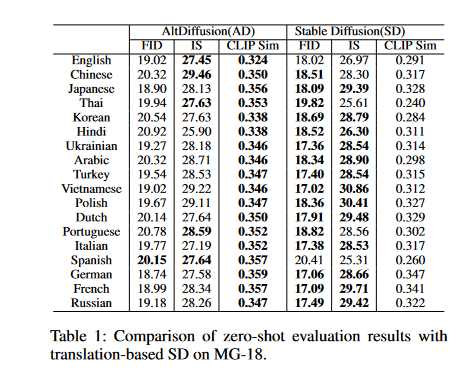
Results on MG-18
The table1 shows the outcomes of zero-shot evaluations of Stable Diffusion (SD) translations on the Multilingual-General-18 (MG-18) dataset.
The SD model performs well when asked to generate images from general text inputs in differents languages, but its performance is lower for cultural text inputs. The proposed multilingual T2I diffusion model, AltDiffusion, achieves better results than the state-of-the-art (SD) model on both general and cultural text inputs.
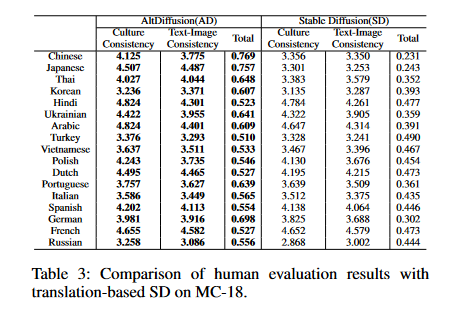
Results on MC-18
The table below shows that AltDiffusion outperforms other T2I models in terms of both quality and diversity of the generated images, as well as capturing culture-specific concepts in different languages.
Application
AD capabilities, including Image to Image (Img2Img) and Inpainting, are shown in Figure 7. The Inpaint and Image-to-Image tools are available in AD.

Compatibility with Downstream Tools
Large T2I models are capable of remarkable performance, yet they remain uncontrollable for certain industrial uses. ControlNet(Zhang and Agrawala 2023), and LoRA(Hu et al. 2021). are two methods that have received a lot of attention recently for making models more controllable. A Large T2I must be compatible with these dowstreams tools. AltDiffusion's output can be directly fed into other systems like ControlNet and LoRA without any compatibility issues.
Because of this functionality, AltDiffusion can be easily combined with other T2I tools.
Conclusion
In this study, the authors provide AltDiffusion(AD), a T2I diffusion model that is multilingual and can accommodate eighteen different languages. They use a two-stage training technique in which a multilingual text encoder is trained, then integrated into a pretrained diffusion model. They also provide a standard by which AD is assessed, in the form of two datasets, MG-18 and MC-18, respectively,
Based on experimental findings, AltDiffusion outperforms the existing state-of-the-art T2I models, such as Stable Diffusion, in multilingual understanding, particularly with regard to culture-specific concepts, while maintaining similar capacity to generate high-quality images. As a large multilingual T2I diffusion model, AD is also compatible with all downstream T2I technologies like ControlNet and LoRA, which might help advance both research and practical application in this area.
References