

Bring this project to life
Automatic text generation is the task of generating natural language text using a machine learning system. The generation here could be open-ended or guided as per some use-case. A well-trained text generation system can make it really hard to distinguish between human and machine-written text pieces. Some of the popular real-world use cases where text generation is seen in action are Gmail's Smart Reply, a smartphone's Auto-completion, etc.
Evaluating these systems can get tricky. Most of the systems available these days are probabilistic in nature and are often seen to hallucinate factual information when generating text. So, one of the best ways to perform the evaluation is to do it with the help of humans, but this might not always be feasible as it is a costly and time-consuming process. It also does not guarantee re-producibility because of the sampling bias. Also, evaluating at scale is not an option when doing manually. Hence, for the above-mentioned reasons, automatic metrics are usually preferred when evaluating text generation systems. Automatic metrics could be both trained and untrained. As expected, trained metrics try to take into account the task specifics when doing the evaluation but at the cost of learning this function with relevant data, whereas, untrained metrics are generic, require no training, are language-independent, and faster to calculate. Untrained metrics are popular and widely used to measure the quality of generated text in both the industry and academia spanning over many use cases like machine translation, text summarization, story generation, image captioning, etc.
In this blog, we will focus on some popular untrained metrics (with code) for evaluating the quality of text generated by existing Natural Language Generation (NLG) systems ranging from classical ones like template-based generation to advanced models like GPT, Sequence Models, etc.
ROUGE
ROUGE stands for Recall-Oriented Understudy for Gisting Evaluation. It was introduced in this paper in 2004. This is a really popular metric that you'll definitely find in the literature around text summarization. The metric is based on calculating the syntactic overlap between candidate and reference summaries (or any other text pieces). Rouge-1, Rouge-2, Rouge-L, and Rouge-S are some commonly calculated numbers. Here, Rouge-1 calculates the overlap of unigram(individual word) between the candidate and reference text pieces. Rouge-2 calculates the overlap of bigrams(word pairs) between the candidate and reference text pieces. Rouge-L calculates the overlap of the longest co-occurring in sequence n-grams between candidate and reference text pieces. Rouge-S calculates the overlap of Skip-bigram(of any pair of words in their sentence order) between the candidate and reference text pieces. The mathematical formulation of Rouge-1 precision, recall is shown below -

In literature, you'll often find the F1 score to be mentioned for each of R1, R2, RL, and so on. The implementation of ROUGE is done below -
from rouge import Rouge
rouge = Rouge()
def calculate_rouge(candidate, reference):
'''
candidate, reference: generated and ground-truth sentences
'''
scores = rouge.get_scores([candidate], reference)
return scoresFeel free to check out the python package here and also check out this online demo.
BLEU
BLEU stands for Bilingual Evaluation Understudy. This is a really popular metric that you'll definitely find in the literature around machine translation and was proposed in this paper in 2002. The metric used in comparing a candidate translation to one or more reference translations. And the output lies in the range of 0-1, where a score closer to 1 indicates good quality translations.
BLEU-1, BLEU-2, BLEU-3, and BLEU-4 are some commonly calculated numbers that you'll often find mentioned in the literature. Here, each of 1, 2, 3, and 4 represent the precision of the n-gram sequence that is taken into consideration while calculating the BLEU score. The mathematical formulation of BLEU is shown below-
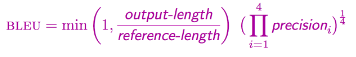
The metric also introduces the notion of "Brevity Penalty"(the first term in the above formula). In which, if the output is shorter than the reference sentence, we penalize the BLEU score by that factor, hence tackling the problem of subset generation.
The implementation of BLEU is done below -
from nltk.translate.bleu_score import sentence_bleu
from nltk import word_tokenize
def calculate_bleu(candidate, reference):
'''
candidate, reference: generated and ground-truth sentences
'''
reference = word_tokenize(reference)
candidate = word_tokenize(candidate)
score = sentence_bleu(reference, candidate)
return scoreFeel free to check out the python package here and follow more examples from here. It's also good to know when not to use a metric, for which I would recommend you read Evaluating Text Output in NLP: BLEU at your own risk.
BERTScore
As the name says, BERTScore has to do something with BERT, right? So yes, BERTScore uses BERT for calculating the quality of text generated by NLG systems. It was proposed pretty recently in this paper in 2020. Unlike most of the methods that majorly make use of token or phrasal level syntactic overlaps between hypothesis and reference text pieces, BERTScore on the other hand captures the semantic aspect by using the contextualized embeddings generated by the BERT model.
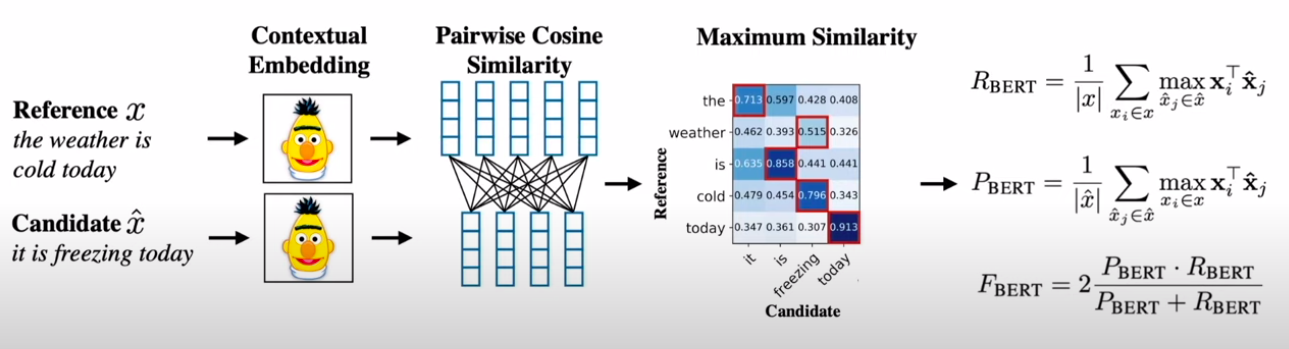
As can be seen in the above figure, it starts by first getting contextualized word embeddings for both reference (ground truth) and candidate (one that's generated by the NLG system) text pieces. It then calculates cosine similarity between each word from both reference and candidates, getting a sense of the semantically most similar words. On which it then calculates Precision, Recall, and F-score using formulas as described in the above image.
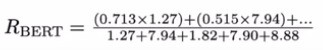
The authors of the paper also talk about the concept of "importance weights", which gives more weight to words that are supposed to be more important and exclusive to the text piece, unlike common words. They use Inverse-document Frequencies(IDF) weights for this purpose. The intuition is that the more common a word is across documents, the less important it is to the concerned document. Hence, the importance of scores for these words shouldn't matter much. In such cases, we will have a low IDF value. On the other side, if the word is unique to the concerned document, it will have a high IDF value. Here, the choice of weight can be tweaked and is open to exploration.
This code can be implemented easily using the Tiiiger bert_score GitHub repo. Follow the instructions to install the library, and then you can run BERTscore for English language evaluation through the terminal like so:
bert-score -r original_text.txt -c generated_text.txt --lang en
Feel free to follow the python library for implementation purposes. There is also a very good video explanation for the same. You can check it out here.
Bring this project to life
METEOR
METEOR stands for The Metric for Evaluation of Translation with Explicit ORdering. It was introduced in this paper. It can be used to evaluate output across various spectrums of tasks like Machine Translation, Text Summarization, Image Captioning, etc. But you'll often find it being used in the literature on machine translation. It also claims to have a high correlation with human judgment.
It comes with some obvious goodness compared to the BLEU metric (a popular one when it comes to evaluating o/p from Machine Translation systems) that focuses on majorly capturing the precision aspect of the generation against the ground truth. METEOR on the other hand is based on the idea of calculating the Harmonic mean of the unigram precision and recall, where recall is given more weight over precision. Giving greater weight to recall allows us to understand more about how much of the ground truth have we produced as a part of output during the generation process. The exact mathematical formulation is shown below -
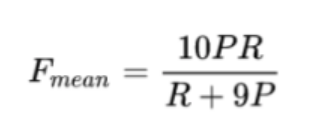
METEOR also has a notion of the "Chunk Penalty" that considers the overlap of not just unigrams but also chunks (consecutive words) to impose some level of ordering. It's denoted with "p" and is calculated as shown below -
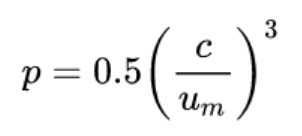
Here, c and um are the number of chunks in the candidate that also occur in reference and unigrams in the candidate sentence respectively. Finally, the METEOR score (M) calculation is done by multiplying the factor "p" with the F-score, shown below -
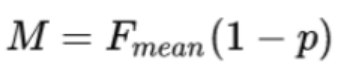
The implementation of METEOR is done below -
from nltk.translate import meteor
def calculate_meteor(candidate, reference):
'''
candidate, reference: tokenized list of words in the sentence
'''
reference = word_tokenize(reference)
candidate = word_tokenize(candidate)
meteor_score = round(meteor([candidate],reference), 4)
return meteor_scoreFeel free to check out nltk's documentation on the same.
Self-BLEU
Self-BLEU is a smart use of the traditional BLEU metric for capturing and quantifying diversity in the generated text. It was proposed by researchers from Shanghai Jiao Tong University and University College London in this paper in 2018.
The lower the value of the self-bleu score, the higher the diversity in the generated text. Long text generation tasks like story generation, news generation, etc could be a good fit to keep an eye on such metrics, helping evaluate the redundancy and monotonicity in the model. This metric can be complemented with other text generation evaluation metrics that account for the goodness and relevance of the generated text. A sweet spot of relevance and diversity would make a perfectly blended output.
The algorithm is pretty straightforward and goes as follows:
- Pick a sentence from a set of generated sentences for a given input. Calculate the BLEU score between this sentence and all other remaining sentences from the set.
- Iterate over all the unique sentences, generate BLEU scores for all, and store them in a list.
- Finally, take the average of the list calculated as a part of step 2.
import numpy as np
import copy
def get_bleu_score(sentence, remaining_sentences):
lst = []
for i in remaining_sentences:
bleu = sentence_bleu(sentence, i)
lst.append(bleu)
return lst
def calculate_selfBleu(sentences):
'''
sentences - list of sentences generated by NLG system
'''
bleu_scores = []
for i in sentences:
sentences_copy = copy.deepcopy(sentences)
remaining_sentences = sentences_copy.remove(i)
print(sentences_copy)
bleu = get_bleu_score(i,sentences_copy)
bleu_scores.append(bleu)
return np.mean(bleu_scores)
calculate_selfBleu(sentences)Word Mover’s Distance (WMD)
As the name hints, it's about calculating the distance a word takes to move itself to another word in some common hyperspace representation. This method can be used to determine the semantic closeness between the generated and the reference text pieces by calculating the minimum word-word distance it takes to transform a sentence into another sentence. However, while WMD works pretty well for short texts, the computation time grows significantly, and also overall semantic essence is a little lost as the length of the documents increase. There have been efforts to fasten the entire WMD calculations with some approximations, feel free to check out this and this.
The below image shows the visual interpretation of this algorithm-
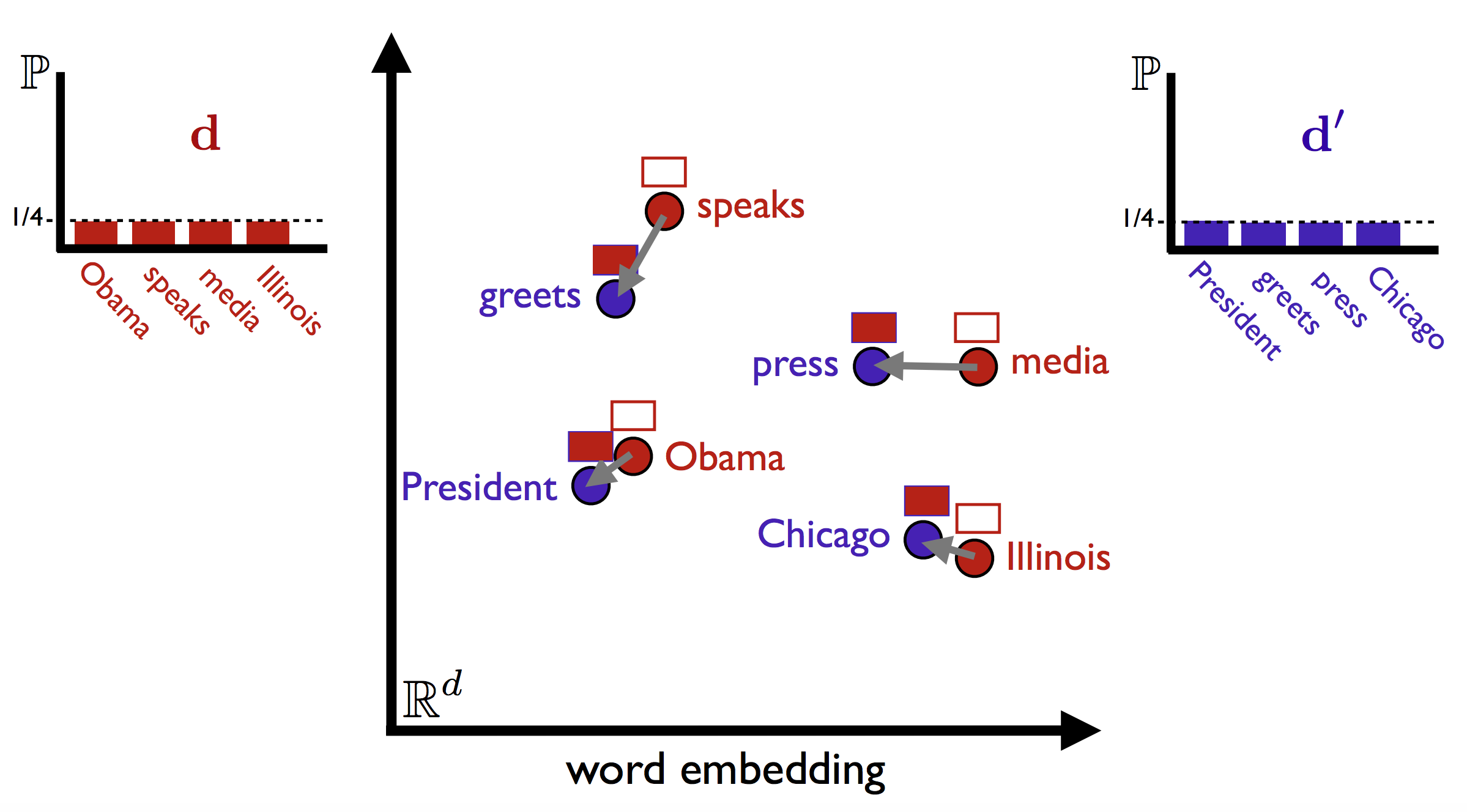
As can be seen in the above image, We have two clean sentences d and d' as "Obama speaks media Illinois" and "President greets press Chicago" respectively. The next thing we do is to project each token of each sentence into some common hyperspace of d dimensions. One can use either out-of-the-box existing methods for this purpose like word2vec, gloVe, fasttext, BERT, etc, or train their versions on their data. The better the representation method, the better the overall distance calculation. Once that's done, the next step is to calculate the WMD by summing up the distance that each word from d takes to go to its nearest (in a semantic sense) word from document d'. For example - "speaks" is closest to "greets", "media is closest to "press", "Obama is closest to "President" and "Illinois" is closest to "Chicago". The original method calculates L2(euclidean) distance as a measure of distance. But one can use other distances like cosine for that matter when dealing with very high dimensions.
Let's take another example and see the distance calculation - As can be seen in the below image, each word from both the document D1 and D2 are aligned to the closest word in document D0. The overall minimum distance covered by the important tokens from D1 to go to D0 is 1.07, whereas, the overall minimum distance covered by important tokens from D2 to go to D0 is 1.63. Less the distance more the similarity.

The implementation of it is really handy and can be done by via gensim library as shown below -
import gensim.downloader as api
model = api.load('word2vec-google-news-300')
def calculate_wmd(model, hypothesis, reference):
'''
model - word vector model
hypothesis - generated sentence
reference - groud-truth sentence
'''
distance = model.wmdistance(
hypothesis,
reference
)
return distanceFeel free to check out gensim's documentation on the same.
Concluding thoughts
Each of the metrics that we discussed today tries to capture certain aspects of the generated text against the available ground truth. So it is practical to measure and report more than one of them for a given task. There have been a few extensions to ROUGE, BLEU, and METEOR in capturing synonyms as well, making them more robust to the overlapping scheme. Also for metrics that rely on syntactic overlaps, it recommended normalizing(case sensitivity, root words, morphological variations, etc) both generated and reference text pieces before doing the calculations. There is also a lot of active research going on in the "learned metric" space unlike what we discussed today which is non-parametric. For instance, You might want to check out BLEURT (paper, video), and Perception Score. We will keep that discussion for another blog.
I hope you enjoyed reading it. Thank you!












{kind=link}