
Bring this project to life
Introduction
With the Cohere platform, you can include natural language processing and generation into your product with only a few lines of code. Classification, semantic search, paraphrasing, summarizing, and content creation are just some of the many natural language use cases that Cohere's massive language models can address. Users can build huge models specific to their use case and train using their data via fine-tuning.
Semantic Search with Cohere
With the help of language models, computers can now go beyond simple keyword matching to conduct in-depth, meaning-based searches. This article will go through the basics of creating a semantic search engine. Semantic search has many uses outside of making a better search engine. They can provide an in-house search engine for confidential files and archival materials. It can be used to power functions like the "similar questions" section on StackOverflow.
Let's install the dependencies & import Libraries
To get started, we will use Line Magic to quickly install the project dependencies using the cell below:
# Install Cohere for embeddings, Umap to reduce embeddings to 2 dimensions,
# Altair for visualization, Annoy for approximate nearest neighbor search
!pip install cohere umap-learn altair annoy datasets tqdmOnce the installs are complete, we can now use the cell below to import the relevant packages to the Notebook.
import cohere
import numpy as np
import re
import pandas as pd
from tqdm import tqdm
from datasets import load_dataset
import umap
import altair as alt
from sklearn.metrics.pairwise import cosine_similarity
from annoy import AnnoyIndex
import warnings
warnings.filterwarnings('ignore')
pd.set_option('display.max_colwidth', None)Get your Cohere API Key by signing up here
In order to use Cohere, you need to sign up for Cohere. This API allows us to connect to any of their endpoints for free, and there is an active userbase of NLP developers to share your work with inside the Cohere community.
Enter your API key using the code block below to get started in the Notebook.
# Paste your API key here. Remember to not share publicly
api_key = ''
# Create and retrieve a Cohere API key from os.cohere.ai
co = cohere.Client(api_key)Get the archive of questions
We'll use the trec dataset, which consists of questions and their respective categories.
# Get dataset
datas = load_dataset("trec", split="train")
# Import into a pandas dataframe, take only the first 100 rows
dt = pd.DataFrame(datas)[:1000]
# Preview the data to ensure it has loaded correctly
dt.head(10)Embed the archive
Let's now embed the text of the questions embedding archive texts. The time required to generate a thousand embeddings of this length will likely be on the order of seconds.
# Get the embeddings
embeds = co.embed(texts=list(dt['text']),
model="large",
truncate="LEFT").embeddingsBuilding the search index from the embeddings
For lightning-fast searches, let's create an index using Annoy that keeps track of the embeddings. The method works well with a massive dataset of texts (other options include Faiss, ScaNN, and PyNNDescent).
After creating the index, we can use it to find the closest neighbors of any existing queries.
# Create the search index, pass the size of embedding
search_index = AnnoyIndex(embeds.shape[1], 'angular')
# Add all the vectors to the search index
for i in range(len(embeds)):
search_index.add_item(i, embeds[i])
search_index.build(10) # 10 trees
search_index.save('test.ann')Bring this project to life
Find the neighbors of an example from the dataset
Suppose we are interested in evaluating the similarities between questions inside the dataset (not any external inquiries). In that case, we can easily calculate the similarities between every pair of embeddings we have.
# Choose an example (we'll retrieve others similar to it)
example_id = 92
# Retrieve nearest neighbors
similar_item_ids = search_index.get_nns_by_item(example_id,10,
include_distances=True)
# Format and print the text and distances
results = pd.DataFrame(data={'texts': dt.iloc[similar_item_ids[0]]['text'],
'distance': similar_item_ids[1]}).drop(example_id)
print(f"Question:'{dt.iloc[example_id]['text']}'\nNearest neighbors:")
resultsOutput:
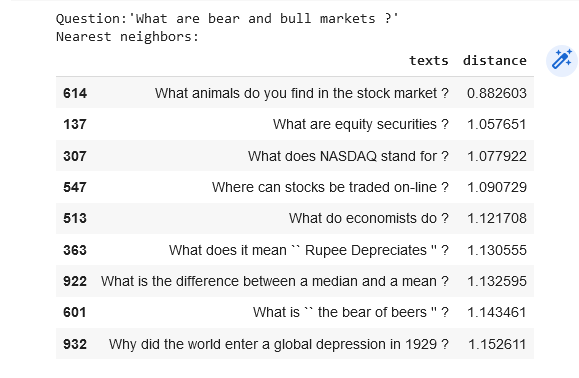
Find the neighbors of a user query
We should not restrict ourselves to preexisting items to find what we need.
As soon as we have a query, we may embed it and look for its nearest neighbors in the dataset.
query = "What is the tallest mountain in the world?"
# Get the query's embedding
query_embed = co.embed(texts=[query],
model="large",
truncate="LEFT").embeddings
# Retrieve the nearest neighbors
similar_item_ids = search_index.get_nns_by_vector(query_embed[0],10,
include_distances=True)
# Format the results
results = pd.DataFrame(data={'texts': dt.iloc[similar_item_ids[0]]['text'],
'distance': similar_item_ids[1]})
print(f"Query:'{query}'\nNearest neighbors:")
resultsOutput:
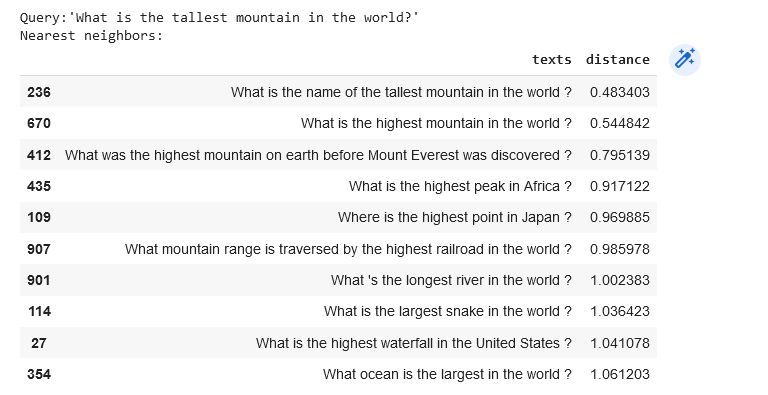
Conclusion
This brief overview of sentence embeddings for semantic search draws to a close. Additional factors come into play as you go further in developing a search product (like dealing with long texts or fine-tuning to better improve the embeddings for a specific use case).
Reference
Semantic Search: https://docs.cohere.ai/semantic-search#2-embed-the-archive











