The ecosystem for developing modern web applications is incredibly rich. There are countless tools for delivering a modern web app to production, monitoring it's performance, and deploying in real-time. These tools are so essential that modern web application development would be almost impossible without them.
By contrast, modern ML and AI doesn't yet have that same ecosystem. This makes sense for a number of reasons: best practices have still yet to emerge (i.e. there isn't a LAMP stack for ML yet), tools are changing quickly, and modern Deep Learning has really only existed for a blink of an eye in the grand scheme of things.
DevOps ➜ MLOps
The questions around ML tooling and building production pipelines are one of the key problems we are trying to solve here at Paperspace. Most of our current work is being built into Gradient° - our toolstack for ML/AI developers to quickly develop modern deep learning applications.
We believe that one of the largest barriers to pervasive and productive AI is an infrastructural and tooling problem (assuming that a hard requirement of these intelligent systems is scrutibility, determinism, and reproducibility).
While container orchestration tools (like Kubernetes, Mesos, etc) are an essential part of modern ML, they are only one small part of a true CI/CD system for deep learning. Furthermore, traditional CI/CD and a similar system for ML/AI have different parameters, constraints, and goals.
We have spent a lot of time thinking about these systems, exploring the landscape, and working with developers in academia, startups, and large enterprise to identify general problems that span across problem domains and can be addressed by a modern machine learning platform.
Generally these pipelines looks pretty similar. They take data in, build a model, and then deploy this model to the world. The particulars, however, are incredibly interesting and worth diving deeper into.

Gradient is our take on modern CI/CD for machine learning and AI systems. As a platform it is being designed to take a set of fundamental building blocks (primitives) which can be composed into larger and more complex systems.
A reproducible pipeline must be composed of deterministic and immutable pieces. These include git hashes, docker hashes, etc. Powerful hashing is one of the key design patterns at the core of Gradient. Job runs, and even machine hardware (host, accelerator, etc) are all assigned immutable tags which are designed to contribute to the larger project of deterministic and reproducible processes.
This post is not about Gradient itself, but rather a collection of thoughts on how these types of systems fundamentally differ from the existing tools in the developers toolchest.
The future of data pipelines
At Paperspace we share the belief that we are in a golden age of machine intelligence but also acknowledge that the relatively nascent field is still playing catch up in many ways. To give just one example, containerization (using Docker or similar technology) pushed modern web infrastructure forward in ways that were unimaginable in the early days of the web. By contrast, containerization in Machine Learning is still relatively new with substantial amounts of production work being done on laptops, bare-metal servers, and hand-configured environments.
Much of modern ML is still being done on powerful desktop computers (the things that sit under your desk and warm your feet). Companies like Lambda Labs and Boxx offer big rigs that include fast processors and big GPUs. We think this is a weird (but understandable) anti-pattern that exists today because there doesn't really exist an affordable and powerful cloud computing option.
Big companies with large Deep Learning and AI expertise have been investing heavily in software platforms that help bring ML up to speed with the rest of the development process. Making AI operational is an ambition for many companies, and the ones that do it successfully will have long-term competitive advantages.
To give just a few examples of these end-to-end ML platforms, Uber has discussed publicly their version called Michaelangelo. Facebook has FBLearner, Google has TFX, and AirBnb has BigHead. Recognizing the power of opening up these types of tools to more companies that might not have the same internal expertise as Google, FB, and Uber, companies like DataBricks have introduced platforms like MLFlow.
Open source alternatives exist such as Polyaxon and KubeFlow, but in most cases a company is left to hack together disparate systems or (worse) attempting to repurpose older toolstacks for these modern dataflows.
Traditional CI/CD workflow
Continuous Integration/Continuous Deployment (CI/CD) describes a set of best practices for application development pipelines. They are largely implemented by devops teams to enable software developers to quickly and reliably introduce updates to production applications.
Some of the core benefits of a modern CI/CD pipeline include:
- reliability
- reproducibility
- speed
- safety
- version control
A quick survey of CI/CD tools for traditional web applications yields a number of tools that you have likely used of heard of:

At their core, these tools attempt to formalize a well-known workflow: Build➡ Test➡ Deploy. For example, we largely use Node.js and Golang here at Paperspace, and we have invested heavily in building infrastructure that lets us quickly push new features to production.
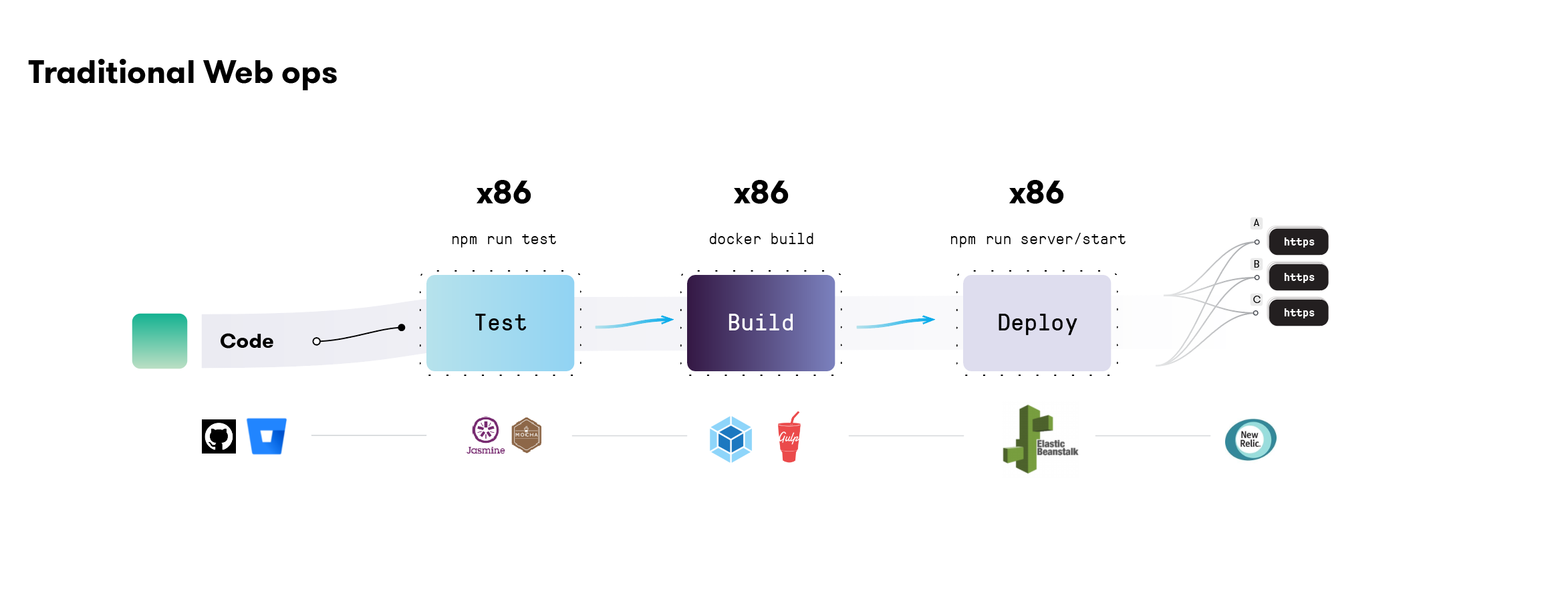
CI/CD are often lumped together, but in fact they describe two separate (but related) concepts. Continuous Integration (CI) is primarily concerned with testing code as it is pushed - i.e making sure that new application features are automatically tested using unit tests. By contrast, Continuous Deployment (CD) describes the actual release/delivery of the tested code. For example, a CD system could describe how different feature/release branches are deployed, or even how new features are selectively rolled out to new users (i.e. test feature A on 20% of the customer base).
Importantly, however, both of these concepts have been largely absent from the conversation around modern machine learning and deep-learning pipelines.
CI/CD For ML/AI
Looking at an ideal CI/CD system for machine learning we immediately see a number of key differences. At Paperspace, we believe these differences are substantial enough to warrant entirely new workflows, development paradigms, and toolstacks.
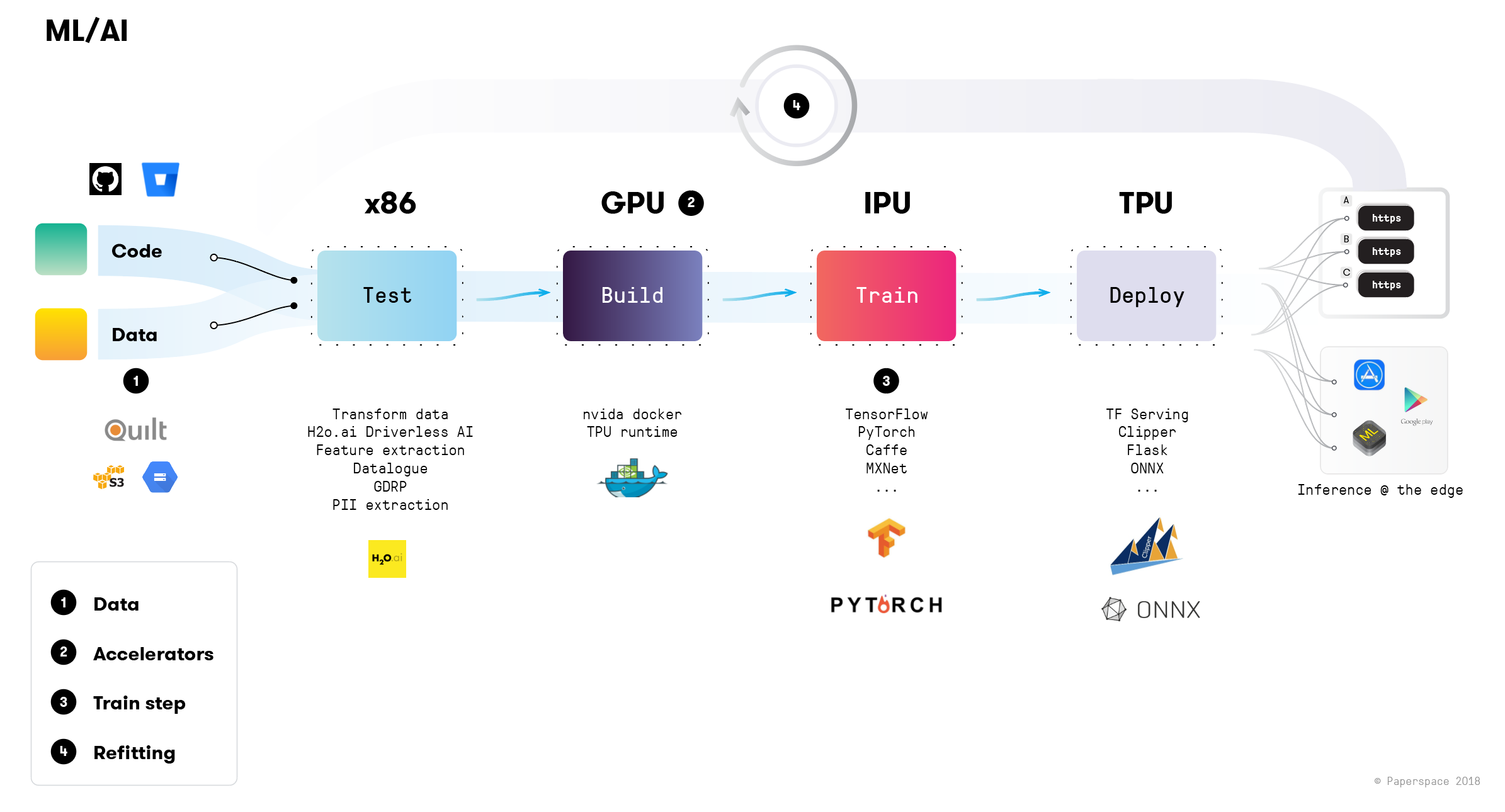
1. Data
Arguably the most consequential difference between traditional web apps and a ML pipeline is the fact that the primary input to the system is not just code. Rather, there are two (equally consequential) inbound components: code and data.
Data orchestration, cleaning, versioning, etc is an entire domain that has only in recent history become a first-class citizen for many companies. The "big data" shift of the last 10 years, as well as the emergence of the data scientist as a primary operator at a company speaks to this dramatic shift.
Unfortunately we are still at a very early stage for true, versioned, reproducible data pipelines. There are no shortage of powerful ETL (extract, transform, load) tools such as Kafka, Spark, Cassandra, Hadoop, etc which are widely used in large-scale production systems today. Modern ML introduces additional constraints and a higher standard for better understanding this data and it isn't hyperbolic to say we are in a "reproducibility crisis" and modern ML is (rightly) criticized for being an inscrutable "black box".
There are many big (and unanswered) questions around data governance/provenance. If a self-driving car is involved with an accident, a regulating body will rightly want to know what assumptions in the data (and the model) contributed to the error condition. The data can embed bias in ways that deep learning models are particularly good at extracting, and as this trend continues there will undoubtedly be increased scrutiny on how data is collected, prepared, and ultimately delivered as an input in to prediction engines.
Tools such as Quilt are leading the way for a forward-looking data versioning tool but they have not yet had widespread adoption. Some alternatives include dat and gitLFS but the space is still new and relatively unexplored. Also worth mentioning is the work being done by teams such as Pachyderm (we are big fans) to think about data as a first class primitive in datascience/ML workflows.
2. Accelerators
It's almost so obvious that it goes without mentioning, but modern webapps are huge beneficiaries of the fact that almost everything runs on traditional x86 architectures (i.e. regular CPUs). There is some really interesting work around ARM for certain applications, but for the most part this homogeneity at the hardware level has allowed a general portability that (in retrospect) was undoubtedly a big part of the general cloud evolution.
Modern ML/AI (and in particular Deep Learning) owes much of its recent progress to the fact that it works extremely well on the GPU. This is more of a historical anomaly more than anything else, but the last few years have witnessed the transition of the GPU from its more well-known application in Graphics Processing to becoming a general compute device.
It is unlikely that the same device will be used to power video games and deep learning applications, and hardware vendors are racing to develop custom silicon that can accelerate deep learning training and inference. Companies like Graphcore (with their "IPU"), Intel (with the Nervana platform), and Google with the TPU (Tensor Processing Unit) are all racing to develop custom chips that are purpose-built for modern machine learning.
What does this mean for the modern ML/AI engineer? The hardware landscape is becoming more complex, heterogeneous, and rich. It is very likely that a modern ML pipeline would utilize a CPU at the data ingest phase, an NVIDIA GPU for training the model, and a custom architectures for deployment to the edge (i.e. the neural engine that lives in your iPhone).
3. Training Step
The training step in a ML pipeline is the area that ends up usually taking the most compute time. It is another big differentiator between traditional datascience and modern Deep Learning. You can do world-class datascience on an inexpensive laptop computer. Just to get started with real deep learning requires investing in expensive GPUs (ideally multiple) or sophisticated cloud tools.
The training task can take anywhere from a couple hours to a couple weeks depending on the complexity of the model, the amount of data to be processed (and its particular dimensions, features, etc), and the type of accelerator being used.
Distributed training (involving multiple distinct compute nodes) has made big progress very recently (with tools like Uber's Horovod, TensorFlow Distributed, and a suite of libraries built in to PyTorch, to name just a few) which adds additional complexity to the task.
4. Refitting / Online
So now the holy grail of machine learning pipelines -- realtime, online, predictive engines that not only deploy forward, but are actually continuously updated. You might have heard of the term "refitting" the model, which means that new data enters in and the model is updated in response to these new observations.
Traditional web application development is largely "unidirectional" in the sense that it flows from code --> deployment. Usually there are static "releases" and modern software development oftentimes necessitates distinct "development" "staging" and "production" environments. Newer technologies such as JenkinsX support things like distinct deployments for each developer/branch but this doesn't change the fact that most deployment processes looks pretty static from the outside. Of course there is customer feedback, bug fixes, etc that inform the development life-cycle, but this is generally the responsibility of organizational process (i.e. an "agile" development method).
In near future, we predict that every company will employ some form of continuous, real-time deep learning engine. That said, the barriers to creating such a system today are numerous. Even static ML pipelines are hard to put into practice by sophisticated teams with substantial resources.
The future, however, is bright in the sense that these types of self-updating, self-modifying systems are getting more practical and we can begin to discuss their possibilities and constraints. In addition to the fundamental machine learning algorithms and toolstacks that have been introduced in recent years (and are constantly being pushed forward by an active academic community), the infrastructural solutions to self-updating ML pipelines are arguably a core component of truly pervasive machine intelligence.
The idea of a self-updating deep learning engine opens up a whole host of problems. At a basic level, how do we detect, quantify, and ultimately correct so-called model drift where the outputted model of a classification or prediction engine begins to diverge from the input in an undesirable way. Perhaps even more pressing, what are the boundaries of these systems and how do we begin to meaningfully constrain them. The thread below is particularly illuminating.
In short, Facebook can simultaneously measure everything about us, and control the information we consume. When you have access to both perception and action, you’re looking at an AI problem. You can start establishing an optimization loop for human behavior. A RL loop.
— François Chollet (@fchollet) March 21, 2018
Conclusion
Ultimately, CI/CD and associated best practices contribute to faster development. A team that commits to a reproducible pipleining tool can build faster, deploy faster, and as a team grow faster.
Modern ML is a quickly evolving space that brings in many different practitioners from traditional software developers, to mathematicians, academics, and business executives and in this sense it is an exciting area to be working in. Even basic terminology is being defined and best practices are largely yet to emerge.
We are eager to hear your thoughts and observations from the field.
A special thanks to Aneesh Karve @ Quilt and John Mannes @ Basis Set Ventures for reviewing early drafts of this post.