
Introduction
The authors of this paper introduce Imagen, a text-to-image diffusion model with an extraordinary level of photorealism and a deep level of language comprehension.
With the objective of more thoroughly evaluating text-to-image models, the authors provide DrawBench, a comprehensive and complex benchmark for text-to-image models.
Imagen relies heavily on diffusion models for high-quality image generation and on massive transformer language models for text comprehension. The main finding of this paper is that generic large language models (e.g. T5), pretrained on text-only corpora, are surprisingly effective at encoding text for image synthesis; in Imagen, increasing the size of the language model, boosts sample fidelity and image-text alignment much more than increasing the size of the image diffusion model.
Related works and Imagen
- Diffusion models have experienced widespread success in image generation, prevailing over GANs in fidelity and diversity while avoiding training instability and mode collapse concerns. Auto-regressive models, GANs, VQ-VAE, Transformer-based approaches, and diffusion models have made significant advances in text-to-image conversion, including the concurrent DALL-E 2, which uses a diffusion prior on CLIP text latents and cascaded diffusion models to generate high resolution 1024X1024 images.
- Imagen, according to the authors, is more easier since it does not need learning a latent prior and gets higher results in both MS-COCO FID and human assessment on DrawBench.
Approach
When compared to multi-modal embeddings like CLIP, the authors show that using a large pre-trained language model as a text encoder for Imagen has some benefits:
- Large frozen language models trained only on text data are surprisingly very effective text encoders for text-to-image generation, and that scaling the size of frozen text encoder improves sample quality significantly more than scaling the size of image diffusion model.
- The presence of dynamic thresholding, a novel diffusion sampling approach that makes use of high guidance weights to generate more lifelike and detailed images than were previously possible.
- The authors emphasize some critical diffusion architectural design decisions and offer Efficient U-Net, a novel architecture alternative that is simpler, quicker to converge, and uses less memory.
Analysis of Imagen, training and results
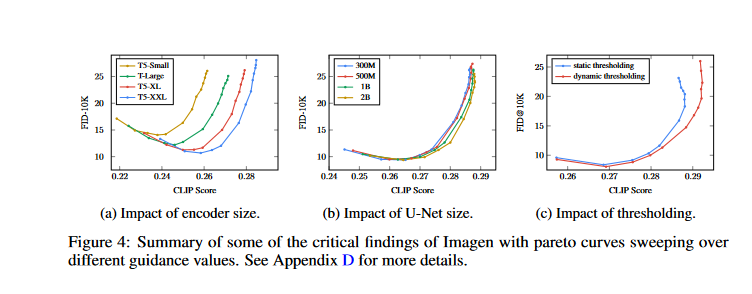
- It's quite efficient to scale the size of text encoders. Scaling up the text encoder consistently improves image-text alignment and image quality, as observed by the authors. Imagen trained with the largest text encoder, T5-XXL (4.6B parameters), yields the best results (Fig. 4a)
- Larger U-Nets are less of a concern than scaling text encoder sizes. The authors discovered that increasing the size of the text encoder had a far larger effect than increasing the size of the U-Net did on the sample quality (Fig. 4b).
- The use of a dynamic threshold is essential. Under the presence of substantial classifier-free guidance weights, dynamic thresholding generates samples with much improved photorealism and alignment with text compared to static or no thresholding (Fig. 4c).
- The researchers train a 2B parameter model for the 64 × 64 text-to-image synthesis, and 600M and 400M parameter models for 64 × 64 → 256 × 256 and 256 × 256 → 1024 × 1024 for super- resolution respectively. They use a batch size of 2048 and 2.5M training steps for all models. We use
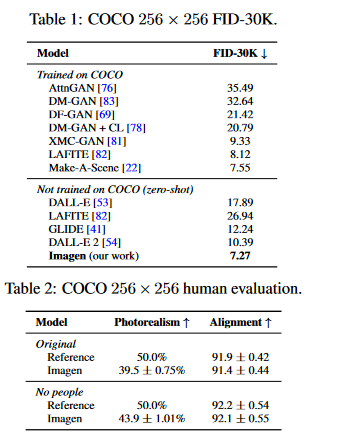
256 TPU-v4 chips for our base 64 × 64 model, and 128 TPU-v4 chips for both super-resolution models - Imagen is evaluated on the COCO validation set using the FID score. The findings are shown in Table 1. Imagen achieves state-of-the-art zero-shot FID on COCO at 7.27, prevailing over DALL-E 2 concurrent work and even models trained on COCO.
- Table 2 summarizes the human assessment of image quality and alignment on the COCO validation set. The authors provide findings for the original COCO validation set as well as a filtered version that excludes any reference data including people. Imagen has a 39.2% preference rating for photorealism, suggesting outstanding image generation. Imagen's preference rate increases to 43.6% on the scene with no people, suggesting Imagen's limited capacity to generate lifelike people.
- Imagen's score for caption similarity is on par with the original reference images, indicating Imagen's capacity to generate images that correspond well with COCO captions.
- On the COCO validation set, models trained with either the T5-XXL or CLIP text encoders provide similar CLIP and FID scores. On DrawBench, however, human raters favor T5-XXL over CLIP in all 11 categories.
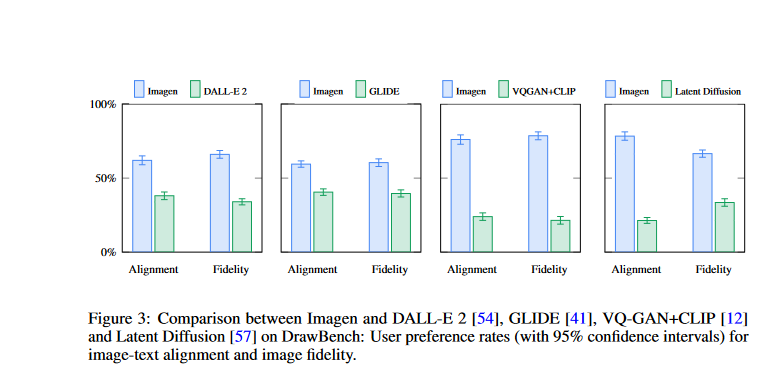
- The authors use DrawBench to compare Imagen to other current approaches including VQ-GAN+CLIP, Latent Diffusion Models, GLIDE, and DALL-E 2, and they show that Imagen is preferred by human raters over the other models in terms of sample quality and image-text alignment.
- Both sample fidelity and image-text alignment are much improved by conditioning across the sequence of text embeddings with cross attention.
Evaluating Text-to-Image Models
we introduce DrawBench, a comprehensive and challenging set of prompts that support the evaluation and comparison of text-to-image models. DrawBench contains 11 categories of prompts, testing different capabilities of models such as the ability to faithfully render different colors, numbers of objects, spatial relations, text in the scene, and unusual interactions between objects.
- Image fidelity (FID) and image-text alignment (CLIP score) are two of the most important automated performance indicators.
- The authors present zero-shot FID-30K, which follows in the footsteps of similar research by reporting a method in which 30K randomly selected samples from the validation set are used to build model samples, which are then compared to reference images taken from the entire validation set.
- Due to the significance of guidance weight in regulating image quality and text alignment, most of the ablation findings in the paper are shown as trade-off (or pareto) curves between CLIP and FID scores for various values of guidance weight.
- To test image quality, they ask the rater, "Which image is more photorealistic (looks more real)?" and provide them with options ranging from the model-generated image to the reference image. The number of times raters prefer model generations over reference images is reported.
- To test alignment, human raters are presented an image and a prompt with the question: "Does the caption accurately describe the above image?". They have three options for a response: "yes," "somewhat," and "no." The scores for these options are 100, 50, and 0 accordingly. These ratings are obtained independently for model samples and reference images, and both are reported.
- In both scenarios, the authors used 200 randomly selected image-caption pairs from the COCO validation set. Subjects received 50 images in batches. They also used interleaved "control" trials and only included data from raters who answered at least 80% of the control questions correctly. This resulted in 73 and 51 ratings per image for image quality and image-text alignment, respectively.
Conclusion
Imagen demonstrates how effective frozen giant pre-trained language models can be when used as text encoders for text-to-image generation using diffusion models.
In their next work, the authors plan to investigate a framework for responsible externalization. This framework will balance the benefits of independent review with the dangers of unrestricted open access.
The data used to train Imagen came from a variety of pre-existing datasets that contained pairs of images and English alt text. Some of this data was filtered to remove noise and anything deemed inappropriate, such as pornographic images and offensive language. However, a recent examination of one of the data sources, LAION-400M, revealed a wide range of offensive material, including pornographic images, racial epithets, and harmful social stereotypes.
The importance of thorough dataset audits and detailed dataset documentation to guide judgments about the appropriate and safe use of the model is underscored by this discovery, which contributes to the conclusion that Imagen is not ready for public use at this time. Imagen, like other large-scale language models, is biased and limited by its use of text encoders trained on uncurated web-scale data.











