Bring this project to life
Data2Vec
The self-supervised learning paradigm has made a significant breakthrough by enabling machine learning models to learn using multi-modal, labeled data. Many ML applications often rely on the representation capabilities of models. But, typically, existing algorithms have certain limitations, as they apply to only a single downstream task (vision, speech, or text) or mode. This paradigm is very different from how humans learn. To enable this level of machine intelligence, the theoretical general AI, the aim of ML model development should be a common framework to understand different types of data (image, text, or audio).
Data2Vec by Meta AI is a recently released model which introduces a common framework to train on different types of data inputs. Currently, it supports 3 types of modalities: Text, Speech, and Vision (images). The objective behind such a general learning framework is to conserve research advancements from one modality problem to another. For example, it enables language understanding to image classification of the speech translation task.
How does it work?
Data2Vec trains the data (of any modality) in two separate modes: Student mode and Teacher mode. For Teacher mode, the backbone model (which is different for each modality and corresponds to the data type) first creates embeddings corresponding to the full input data whose purpose is to serve as targets (labels). For student mode, the same backbone model creates embeddings to the masked version of input data, with which it tries to predict the full data representations. Remember, the backbone model is different for different types of data (text, audio, or vision) in a single Data2Vec model.
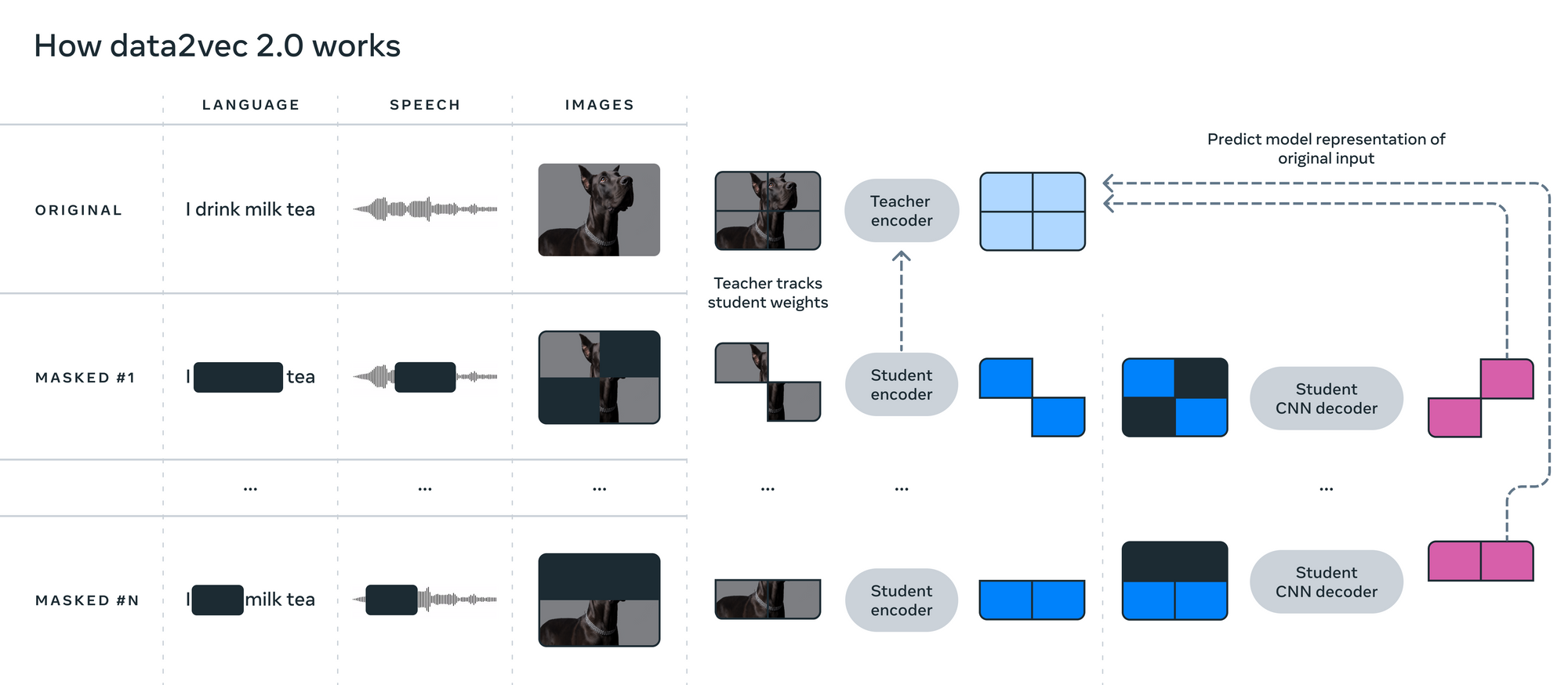
In teacher mode, the target is taken as the weighted sum of all the features in the single sample. For example, in the case of image data, the backbone model generates representations of 4 different patches of the image and takes a weighted average of each of them. The training targets are based on averaging the top K Feed-Forward module blocks of the teacher encoder network, where K is a hyperparameter.
From the above figure, we can see that the parts of the input data are masked in student mode. The student encoder network creates a representation of only unmasked input data. Then the model attaches the constant embeddings in place of the masked data patch. Now, this resultant embedding is passed through the student decoder network which tries to predict the target representation (created from the teacher encoder network). For learning, only the masked input representation is compared between the teacher and student network.
Teacher encoder network weights ∆ are exponentially moving averages of student encoder weights θ. Weights can be represented formulaically with ∆ = τ ∆ + (1 − τ ) θ , where τ is a hyperparameter that increases linearly. L2 loss is used for learning between target representation (from the teacher network) y and the masked representation (from the student network) f(x) .
As stated earlier, the Data2Vec model utilizes different backbone models depending on the type of data being fed. For vision, it uses the Vision Transformer (ViT), which acts as a feature encoder for patches of dimension 16x16. For speech, it uses the Multi-Layer Convolutional Network. For text, it uses embeddings learned from byte-pair encoding.
Comparison with existing algorithms
In the paper, the results of Data2Vec are compared with the state-of-the-art representation learning algorithms in computer vision, speech processing, and natural language processing. The comparison is performed based on accuracy for image classification, word error rate for speech recognition, and GLUE for the natural language understanding task. The below plots represent the performance of Data2Vec v1 & v2 with other state-of-the-art models from the corresponding modality.
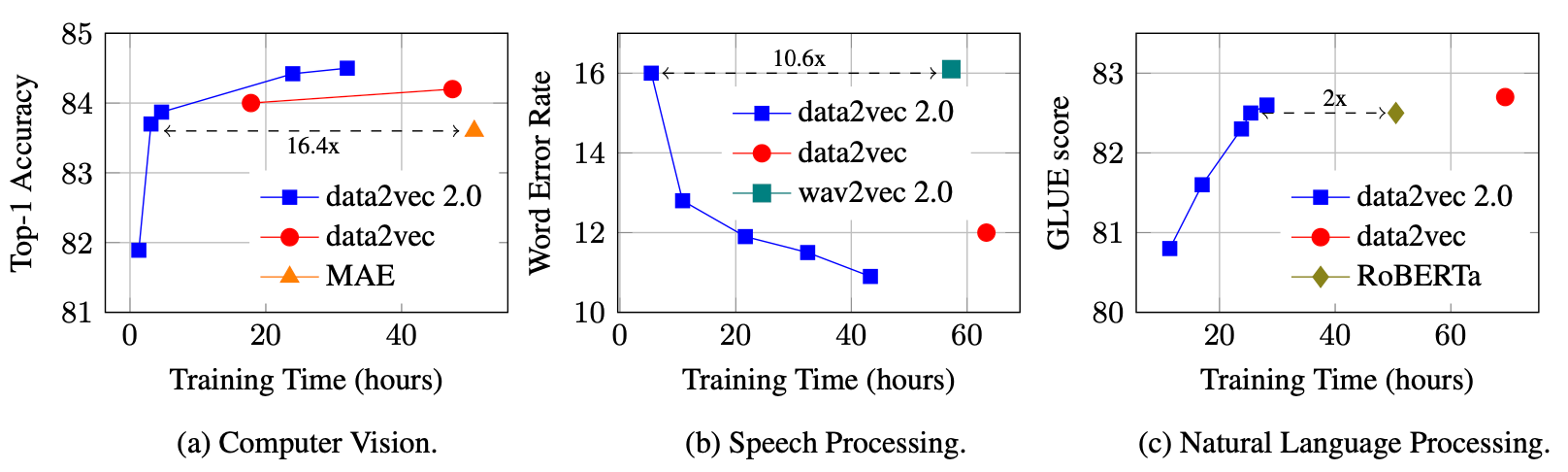
In the above plots, we can notice that Data2Vec 2.0 performs the best in all 3 modality tasks. We can also observe that it trains faster.
Be careful not to mistake the two versions of Data2Vec. Both have the same underlying architecture, but v2 has made some computation changes for faster training.
Try it yourself
Bring this project to life
Let us now walk through how you can train the model using the datasets described in the paper, and use it for your own purposes. For this task, we will get this running in a Gradient Notebook here on Paperspace. To navigate to the codebase, click on the "Run on Gradient" button above or at the top of this blog.
Setup
The file installations.sh contains all the necessary code to install the required dependencies. Note that your system must have CUDA to train Data2Vec. Also, you may require a different version torch based on the version of CUDA. If you are running this on Paperspace Gradient Notebook, then the default version of CUDA is 11.6 which is compatible with this code. If you are running it somewhere else, please check your CUDA version using nvcc --version. If the version differs from ours, you may want to change versions of PyTorch libraries in the first line of installations.sh by looking at the compatibility table.
To install all the dependencies, run the below command:
bash installations.sh
The above command clones fairseq repository and install fairseq package which is used to execute the training and validation pipeline. It also installs the apex package which enables faster training on CUDA-compatible devices. Moreover, it installs extra dependencies mentioned in requirements.txt file.
Downloading datasets & Start training
Once we have installed all the dependencies, we can download the datasets and start training the models.
The datasets directory contains the necessary scripts to download the data and make it ready for training. Currently, this repository supports downloading 3 types of datasets ImageNet (Vision), LibriSpeech (Speech), and OpenWebText (Text).
We have already set up bash scripts for you which will automatically download the dataset for you and will start the training. scripts directory in this repo contains these bash scripts corresponding to a few of the many tasks which Data2Vec supports. You can look at one of these task bash scripts to understand what it does. These bash scripts are compatible with Paperspace Gradient Notebook.
To download data files and start training, you can execute the below commands corresponding to the task you want to run it for:
# Downloads ImageNet and starts training data2vec_multi with it.
bash scripts/train_data2vec_multi_image.sh
# Downloads OpenWebText and starts training data2vec_multi with it.
bash scripts/train_data2vec_multi_text.sh
# Downloads LibriSpeech and starts training data2vec_multi with it.
bash scripts/train_data2vec_multi_speech.sh
Note that you may want to change some of the arguments in these task scripts based on your system. Since we have a single GPU on Gradient Notebook, the arg distributed_training.distributed_world_size=1 for us which you can change based on your requirement. You may want to know all the available args from the config file corresponding to the task in data2vec/config/v2.
Checkpoints & Future usage
Once we have downloaded the dataset and started the training, the checkpoints will be stored in the corresponding sub-directory of the directory checkpoints. You may want to download the publicly available checkpoints from the original fairseq repository. If you are training the model, note that the training will only be stopped when the minimal threshold condition between the target and predicted variable difference is met. It means there is no predefined number of epochs for training. Although, you can stop the training manually if you want to interrupt the training in between and use the last checkpoint.
To use the model for inference, you can use below code:
import torch
from data2vec.models.data2vec2 import D2vModalitiesConfig
from data2vec.models.data2vec2 import Data2VecMultiConfig
from data2vec.models.data2vec2 import Data2VecMultiModel
# Load checkpoint
ckpt = torch.load(CHECKPOINT_PATH)
# Create config and load model
cfg = Data2VecMultiConfig()
model = Data2VecMultiModel(cfg, modalities=D2vModalitiesConfig.image)
model.load_state_dict(ckpt)
model.eval()
# Generating prediction from data
pred = model(BATCHED_DATA_OBJECT)
Note that you need to load the checkpoint of the corresponding task to generate a prediction. It means that you can't generate predictions on image data using the checkpoint generated from training audio data.
Conclusion
Data2Vec is a very powerful framework that unifies learning schemes for different types of data. Due to this, it significantly improves the performance of downstream tasks, especially for multimodal models. In this blog, we walked through the objective & the architecture of the Data2Vec model, compared the results obtained from Data2Vec with other state-of-the-art models, and discussed how to set up the environment & train Data2Vec on Gradient Notebook.
Be sure to try out each of the model varieties using Gradient's wide range of available machine types!











