
Bring this project to life
In the past weeks, we have been looking at several techniques for improving various Stable Diffusion inference pipelines by adding various types of guidance, versatility, and control. Examples of this include the incredible ControlNet, T2I-Adapter, Self-Attention Guidance, and many more.
One of the big challenges for working with Stable diffusion and txt2img models in general, is controlling for the randomness and noise artifacting that occurs in every generative model. It's simple to tell a model, via text prompting, what to generate, but it is another matter altogether to implement finer control to this process in a way that doesn't break things.
Today we are going to talk about one of the most interesting solutions to this problem: GLIGEN, aka Grounded-Language-to-Image Generation. This fascinating new model works by freezing the weights and injecting the grounding truth information into new, trainable layers via a gated mechanism. In practice, this allows us to direct the model where to generate certain objects, subjects, or details in the final output with a high degree of accuracy. While these newly added features are still subject to the problems of txt2img synthesis models at large, GLIGEN can mitigate much of this effect by directly guiding the inpainting for distinct regions of interest.
In this tutorial, we will start with an overview of GLIGEN, including a more detailed explanation for how the model works, the model architecture, and it's capabilities. Once we are familiar with the topic at hand, we'll conclude by showing how to set up GLIGEN with any Huggingface model in a Gradio application, and run it in a Gradient Notebook (launch with a Free GPU Machine by clicking the Run on Gradient link at the top of this article!).
GLIGEN
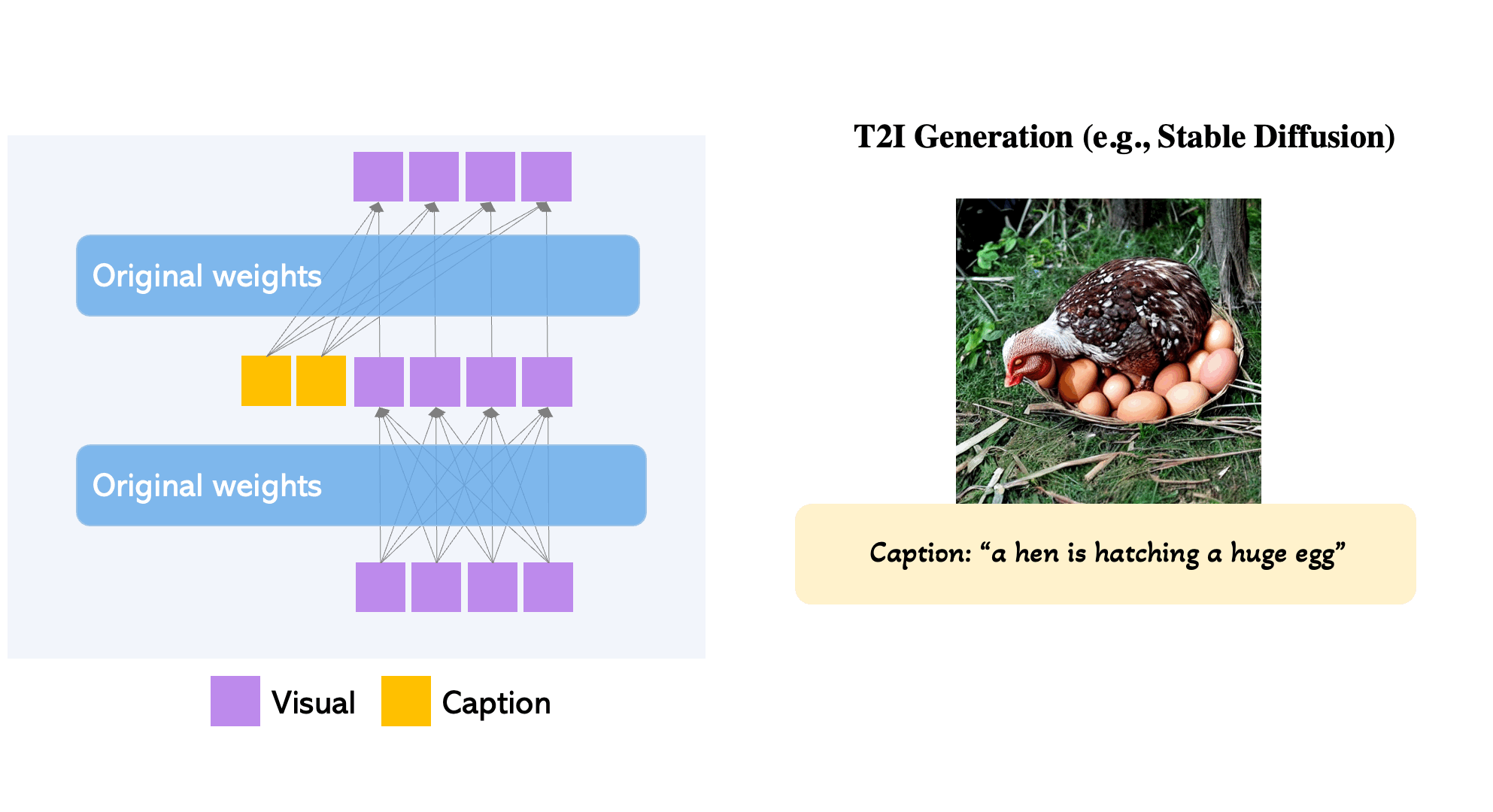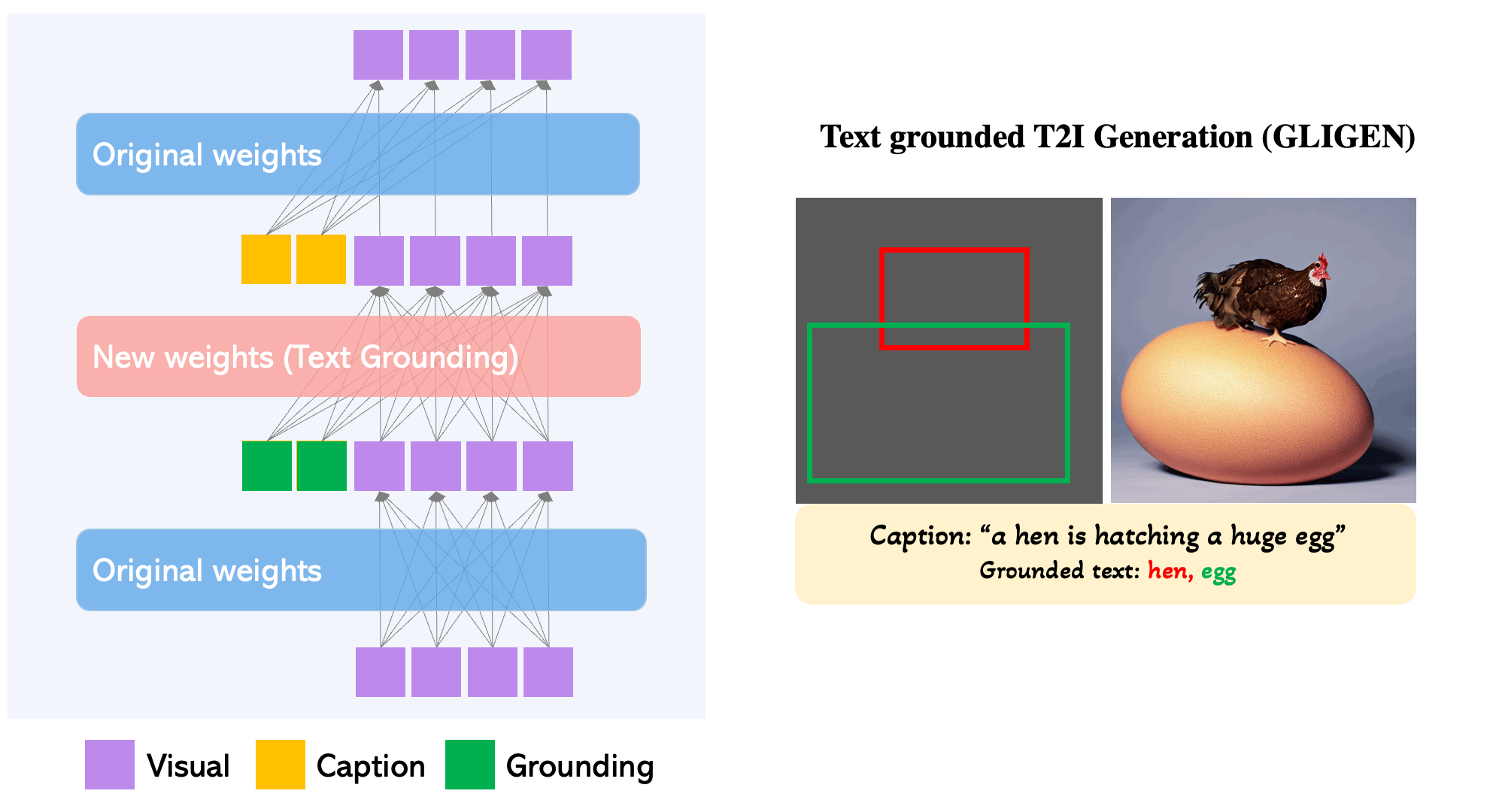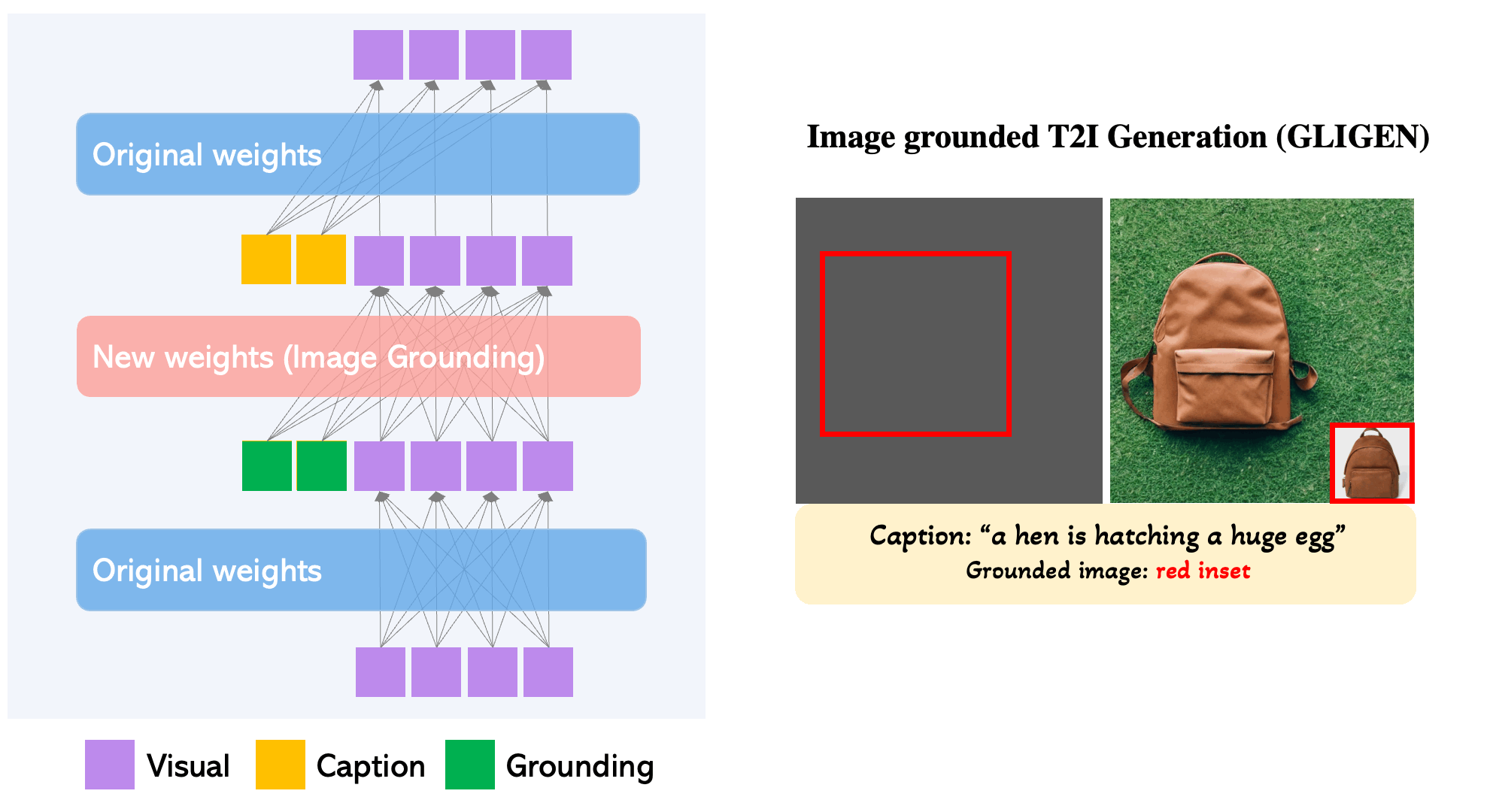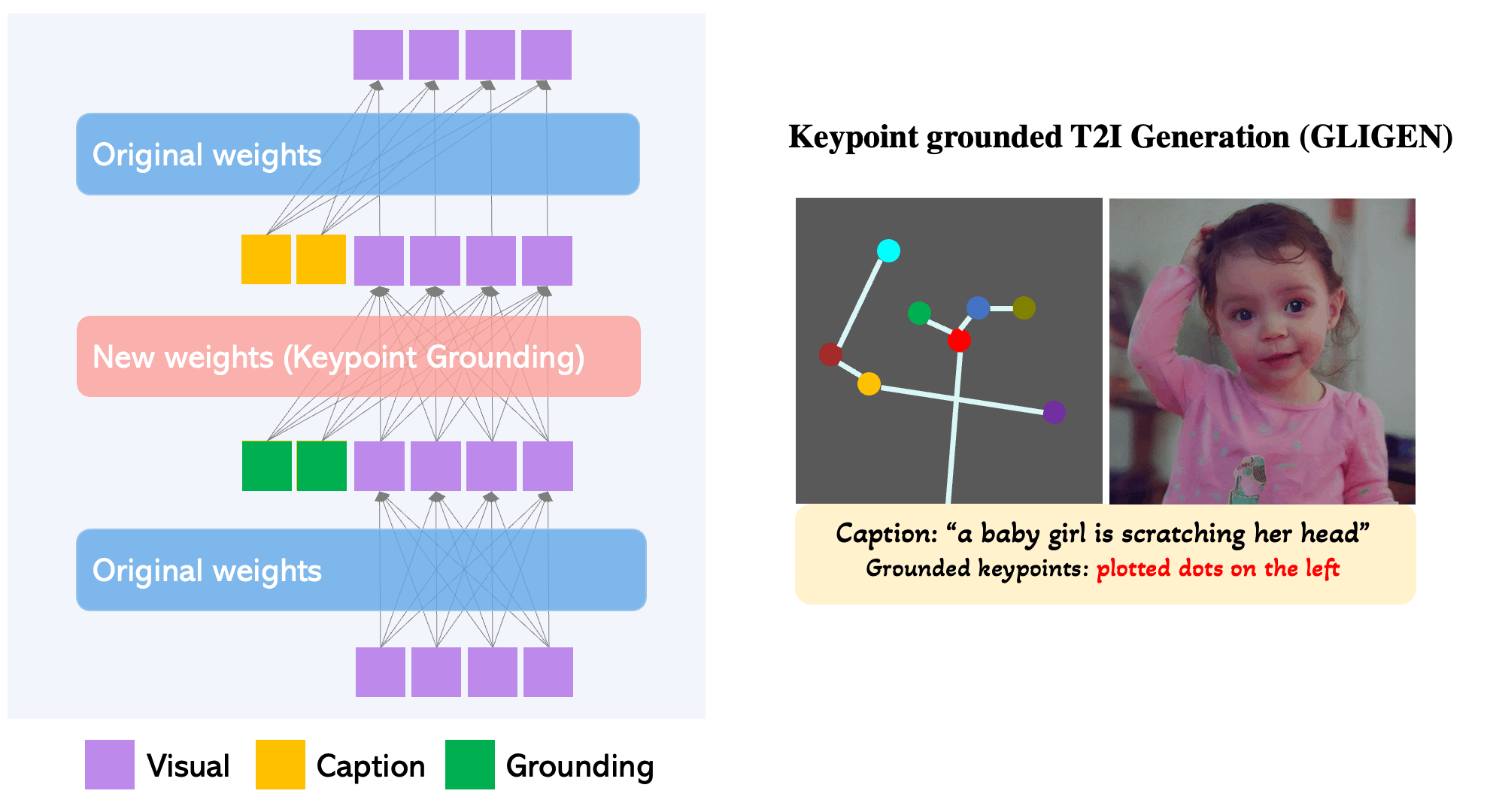
How does it work?
Modulated training
The original Transformer block of Latent Diffusion Models is comprised of two attention layers: self-attention from the visual tokens and cross-attention from caption tokens. GLIGEN first key contribution to achieving this SOTA status in layout txt2img synthesis is freezing the training weights of the original model, and inserting novel Gated Self Attention layers in between the model's attention layers (see fig below).
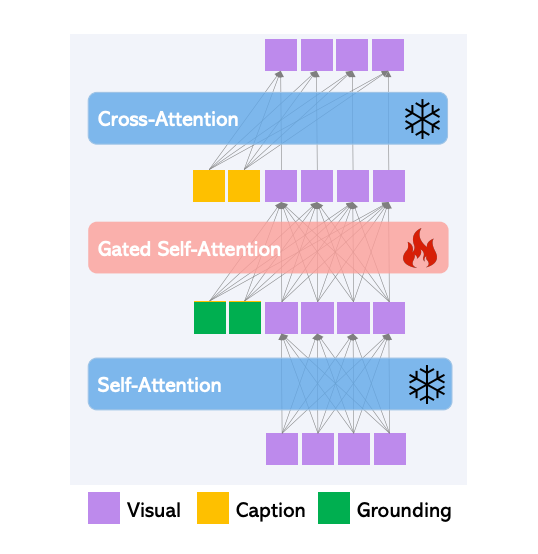
This enables the spatial grounding capabilities of the model by forcing the model attention to be performed over the concatenation of visual and grounding tokens. This is done in such a way that the grounding truth injection has no effect on the original models understanding and has no effect on any sort of pre-trained concept knowledge. The modification of this block allows for much greater influence from the user by defining specific regions to modulate with the novel feature, and this leads to the subsequent, significant reduction to the cost for tuning the model to a specific concept.
In practice, GLIGEN is capable of retaining the original concept knowledge while still continually learning novel information to insert into the synthesis process.
Scheduled Sampling
The next innovation of GLIGEN we need to discuss is the selective switching on and off of the effect of this modulated training during inference to achieve better results.
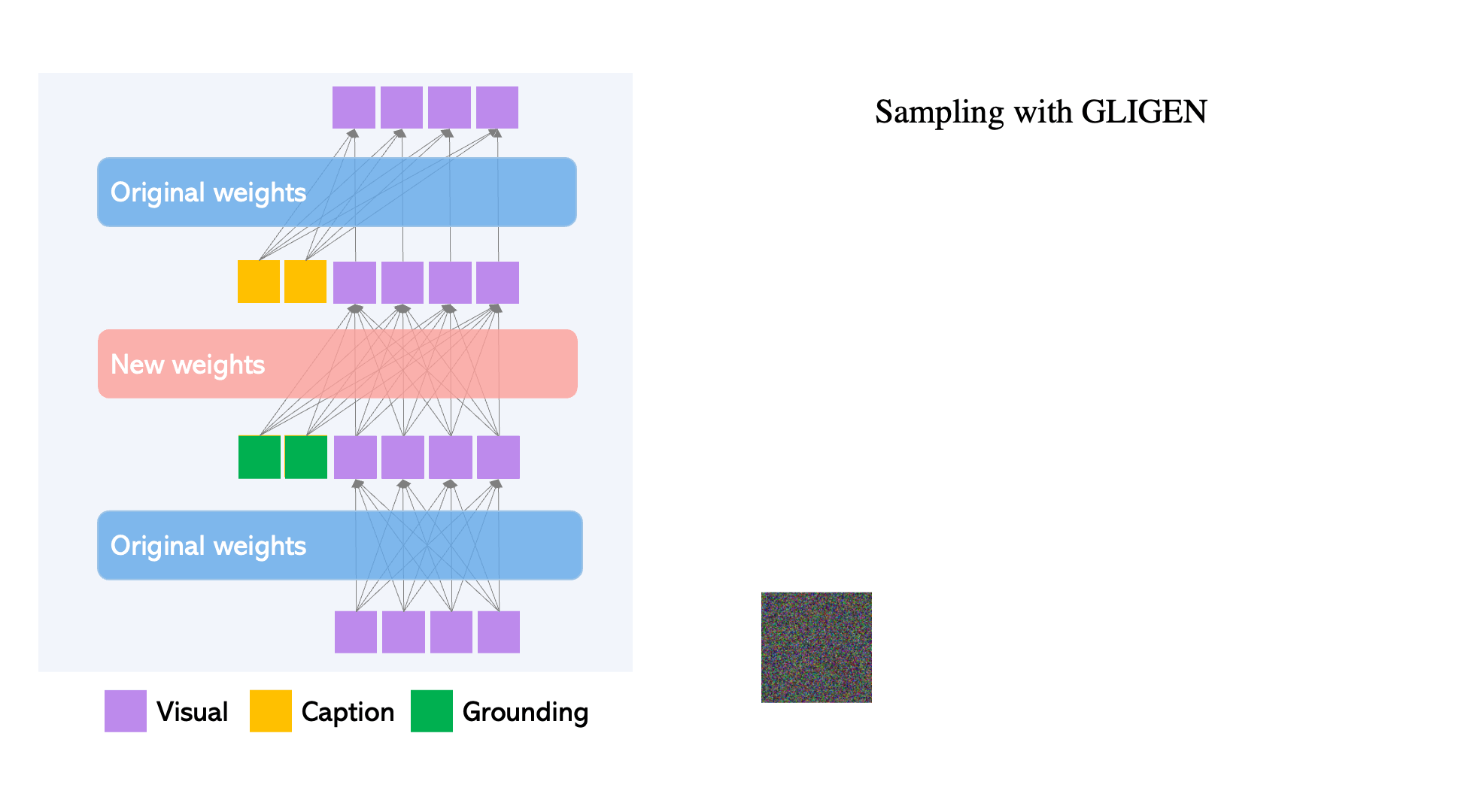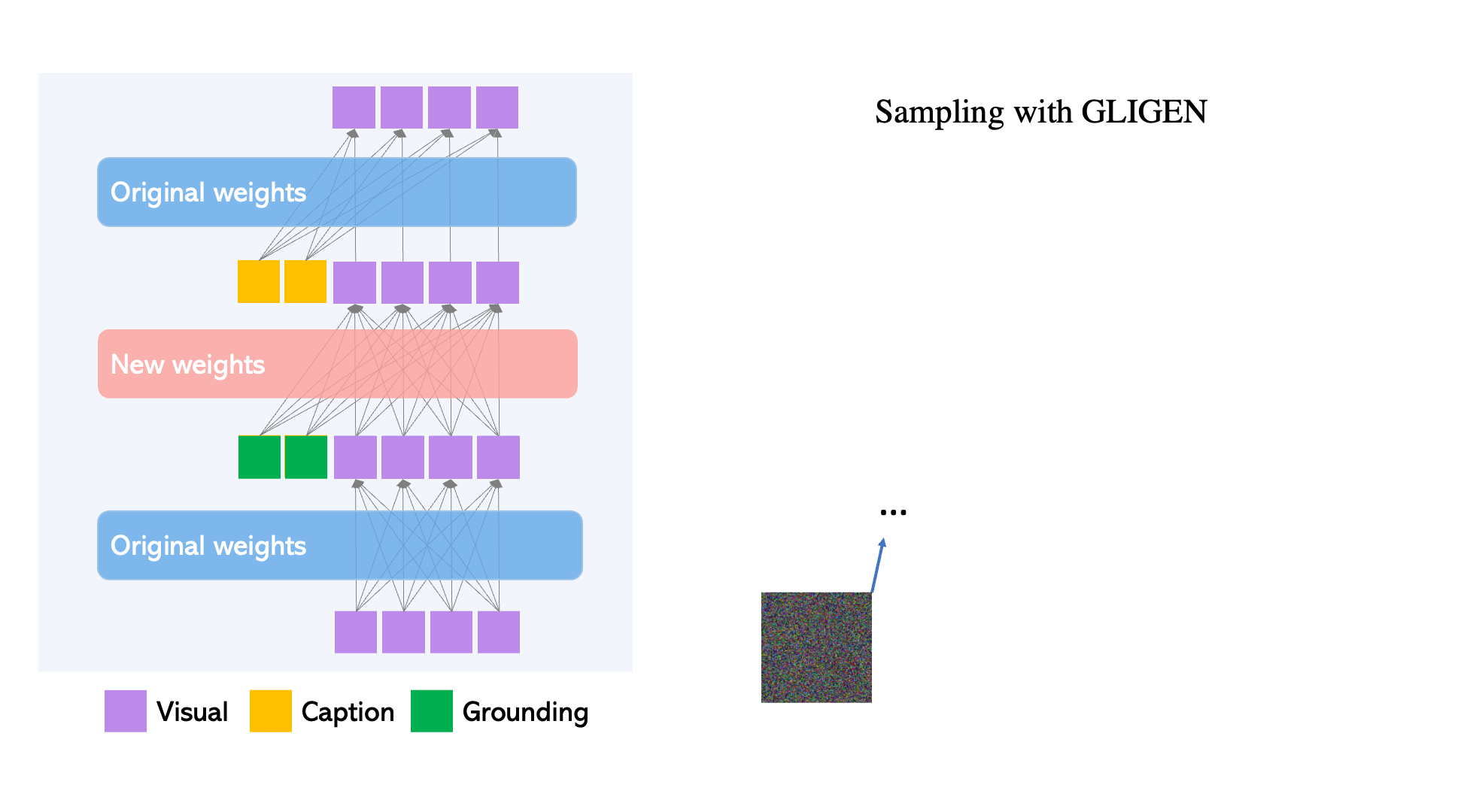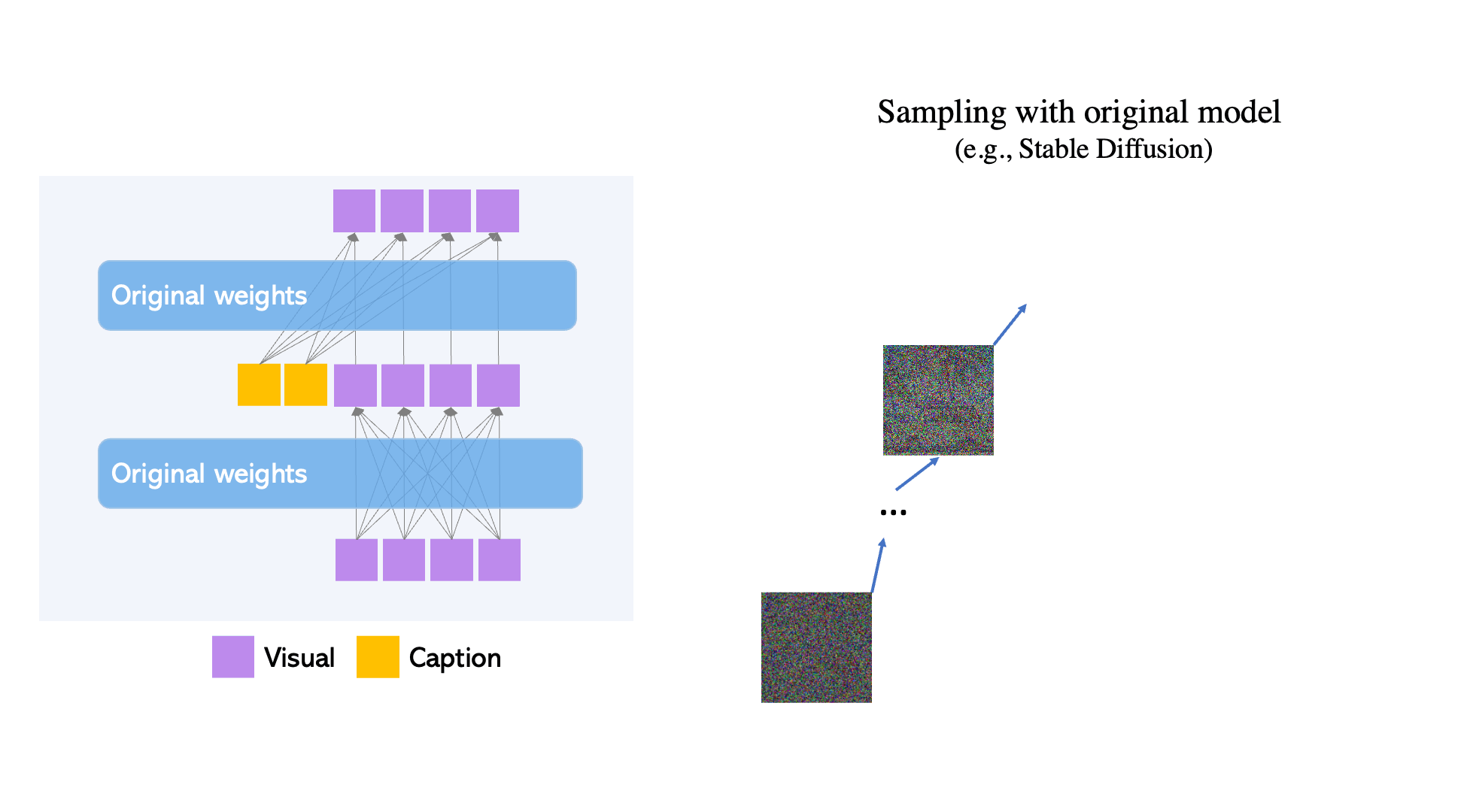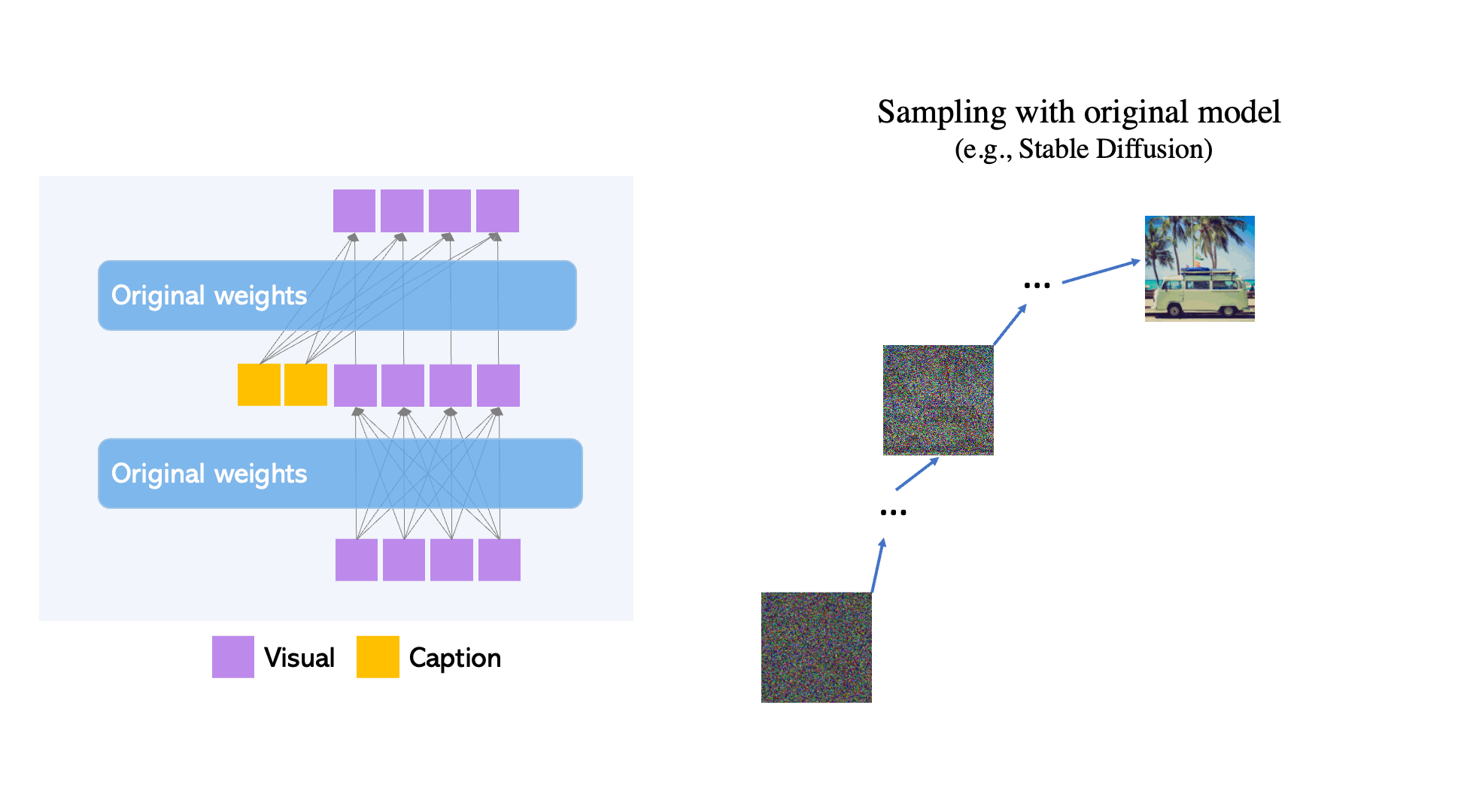
During inference itself, the model can dynamically decide whether or not to use grounding tokens (by adding the new layer) or the original diffusion model (by removing the new layer). This is called Scheduled Sampling. This innovation significantly improves output visual quality because it can initially use the rough concept location and outline in the early steps of re-noising, and then, during the later steps, can implement the fine-grained details.
Capabilities:

GLIGEN is an excellent option for users seeking to increase their control through grounding to typical txt2img synthesis, including with text grounded synthesis bounding boxes, inpainting, keypose estimation, and image grounded T2I Generation with bounding boxes.

When compared qualitatively with competing models, we can start to see why GLIGEN reports such success. Take a look at the example above from the GLIGEN project page. Here, we can see how GLIGEN handles different formations of the final output of the grounding prompt via manipulation of the bounding box locations. The versatility on display when compared to DALLE and DALLE2 should not be underestimated: the power to choose where a feature will be placed is potent in image generation frameworks, and the results reflect this quantitatively as well.
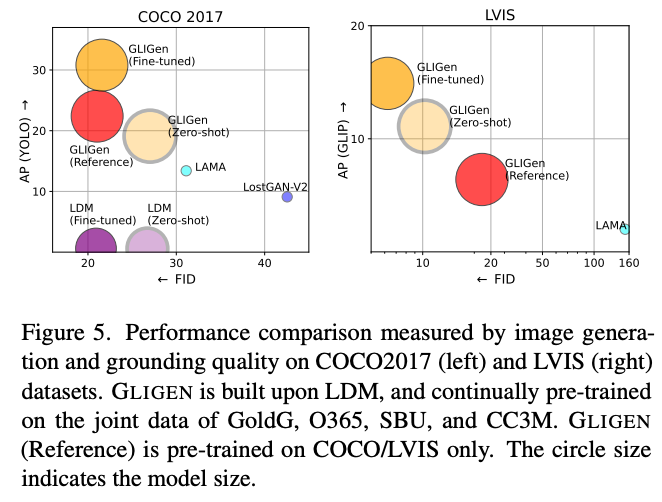
In order to assess the model, the researchers applied a number of tasks to compare the model with existing competitors in the contexts of style reference, zero-shot, and fine-tuned versions of GLIGEN. They found that on COCO2017 and LVIS, the fine-tuned versions of GLIGEN dominated against existing competition.

Additionally, they tested the inpainting and keypoint processing abilities of the model against the competition. They found that their model can generate much higher degrees of accuracy to both the original image and prompt inputs when compared to competing model types.
Overall, GLIGEN offers a substantial improvement over typical Stable Diffusion for creating images with a fine degree of control over the physical locations of the features in the synthesized images.
Demo
We are going to now adapt the official GLIGEN HuggingFace space to run in a Gradient Notebook. Just click the link below to open up a new Notebook with the relevant files. The only requirement to run this is an account with Gradient!
Bring this project to life
Setup
Setting up the environment has been simplified to just a single cell run to make this all easier. Inside your Gradient Notebook, open up a new file in the demos directory called notebook.ipynb and navigate to the first code cell. Paste the code in the cell shown below. Run the cell to install all the required packages.
%cd demo
pip install -r requirements.txtOnce that's done, we can execute the code in the following cell to start up the Gradio application. This will output a shareable link that we can then use to query our model from any web browser. This may take a few minutes as the model checkpoints download. Paste the following code into the next code cell and run it to open up the application.
!python app.py --load-text-box-inpainting True --load-text-image-box-generation TrueUsing the app
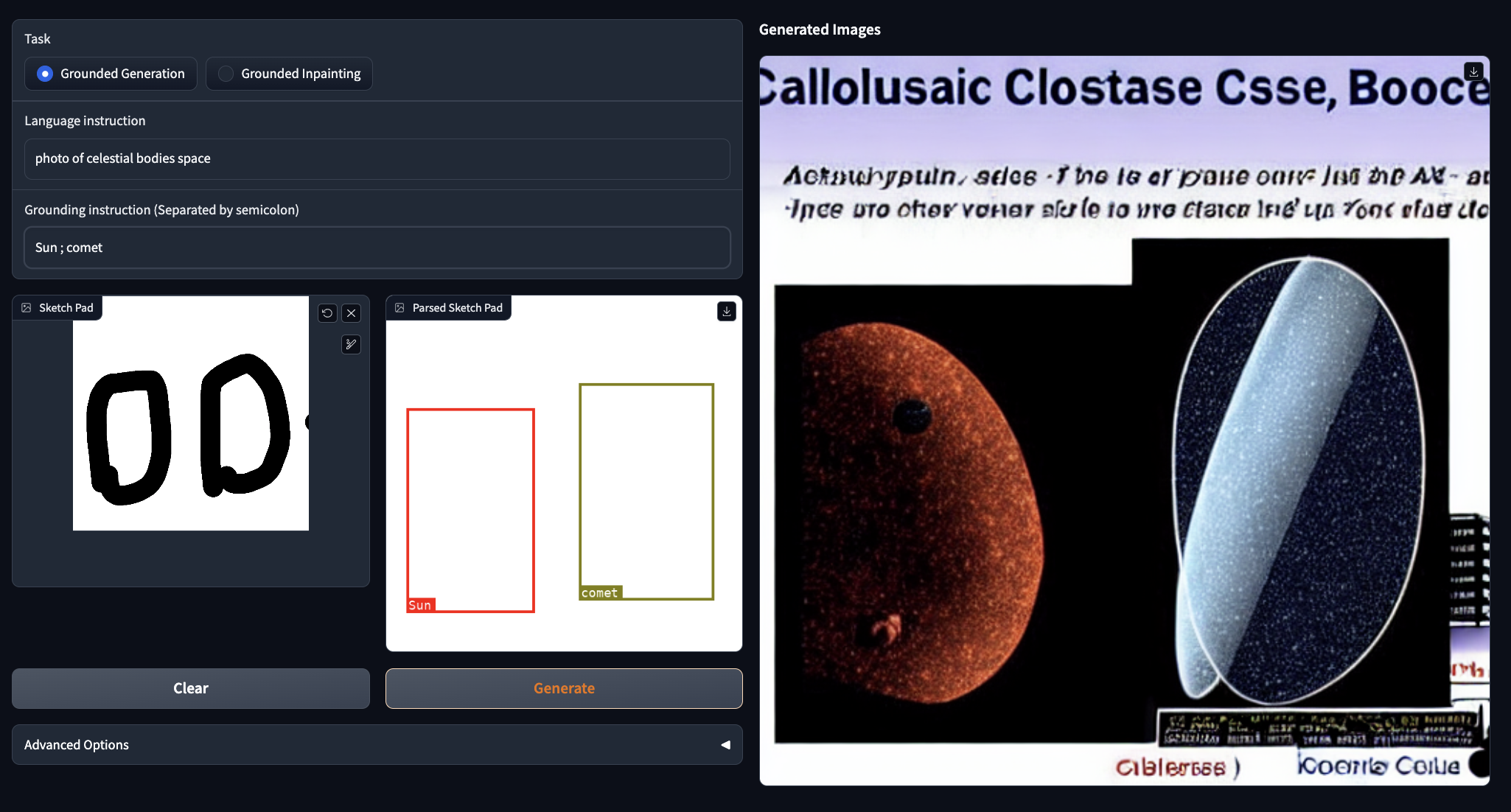
Now that we are in the web app, we can begin to make synthesized images! First, let's play around with the grounded generation framework, where the scribbled drawing determines the bounding box locations. As you can see from the example above, there are two named objects: Sun and Comet. We can change these by altering the semicolon separated variables in the grounding instruction text box, and we can alter the context for the images by adjusting the language instruction.
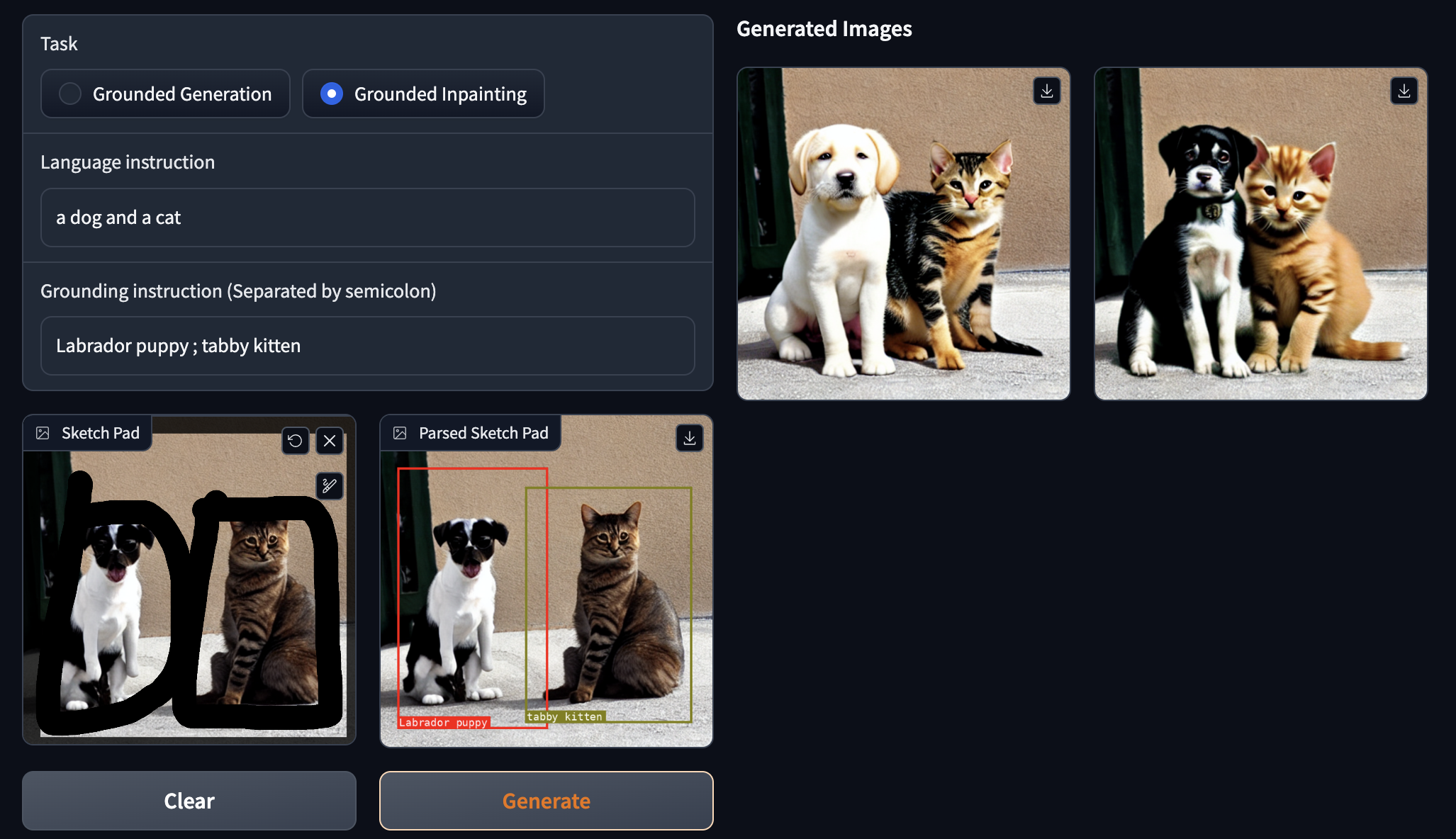
The inpainting function is very similar. Simply add in an existing photo to the application, supply the instructions, and let it make changes. This is a powerful image editing framework thanks to this functionality. Above is an example we made using a photo of a cat and dog turned into puppies and kittens of different breeds.

By playing around with the grounded truth values and language instruction, we can alter the nature of our outputs significantly while using the same bounding box inputs as guidance. Be sure to try adding in as many features as possible to try and push the limits of the model! Surprisingly, it can handle a lot of grounded truth variables to a high degree of accuracy, so long as we are careful not to include the grounded truth statements in the language instruction context. (this can be turned off in advanced options).
Closing thoughts
GLIGEN is a fantastic new pathway to generating quality images thanks to its high degree of controllability, versatility, and power to the text2image synthesis pipeline. We are looking forward to seeing implementations of GLIGEN with ControlNet and the Stable Diffusion Web UI, soon!
This application can be run on any Gradient Notebook, so be sure to try it out on more powerful machines for faster generation!
Resources
- Link to paper
- Link to github (see gradient-ai fork for the code in this project)
- Link to project page










