
Understanding how to finetune PaliGemma using Paperspace GPU is crucial for developers, data scientists, and AI enthusiasts. This article will dive into the process, focusing on using the A100-80G GPU for our task. This guide will provide a comprehensive understanding of how to finetune this vision model.
The evolution of vision-language models has been remarkable. They have become incredibly versatile from their early stages of understanding and generating images and text separately. Today, these models can describe the content of a photo, answer questions about an image, or even create detailed pictures from a text description, marking a significant advancement in the field.
Fine-tuning these models is crucial because it fits the model to specific tasks or datasets, improving their accuracy and performance. By training them on relevant data, they better understand context and nuances, which is essential for real-world applications.
So, PaliGemma is an open-source vision language model released by Google. The model can take in images and text and output text. We have already created a detailed blog on PaliGemma, where we explored the model with various input images, discussing its architecture, training process, and performance on different tasks.
PaliGemma represents a significant advancement in vision-language models, offering a powerful tool for understanding and generating content based on images.
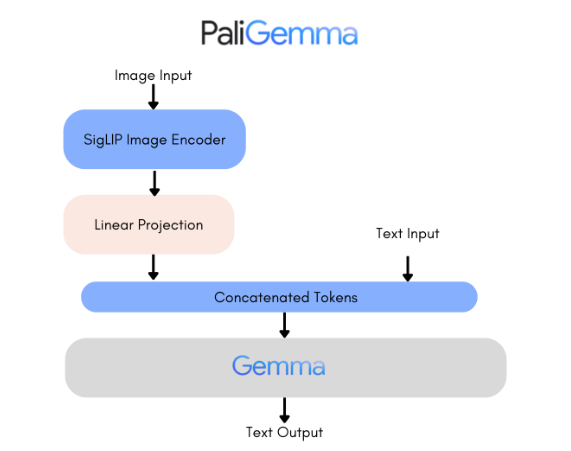
PaliGemma is a family of advanced vision-language models. It combines SigLIP-So400m as the image encoder and Gemma-2B as the text decoder. SigLIP, like CLIP, understands images and text with its joint training approach. The PaliGemma model, similar to PaLI-3, is pre-trained on image-text data and can be fine-tuned for tasks like captioning or segmentation. Gemma is explicitly designed for text generation. By connecting SigLIP's image encoder to Gemma through a simple linear adapter, PaliGemma becomes a competent vision-language model.
Why A100-80G?
Using the NVIDIA A100-80G from Paperspace for fine-tuning vision-language models like PaliGemma offers significant advantages. Its high performance and 80GB memory capacity ensure efficient handling of large datasets and complex models, reducing training times.
The A100 80GB debuts the world’s fastest memory bandwidth at over 2 terabytes per second (TB/s) to run the largest models and datasets—NVIDIA.
AI models are becoming more complex, especially conversational AI, demanding significant computing power and scalability. NVIDIA A100 Tensor Cores with Tensor Float (TF32) offer up to 20 times higher performance than previous models like NVIDIA Volta.
The NVIDIA A100-80G GPU available on Paperspace represents a cutting-edge solution for intensive computing tasks, particularly in AI and machine learning. With its 80GB of memory and Tensor Cores optimized for AI workloads, the A100-80G delivers exceptional performance and scalability—Paperspace's cloud infrastructure leverages these capabilities, offering users flexible access to high-performance computing resources.
This combination allows researchers, developers, and data scientists to tackle complex AI models and large-scale data processing tasks efficiently, accelerating innovation and reducing time to solutions in various fields.
Finetuning the Vision Language Model
Bring this project to life
Install the Packages
We will first install all the latest versions of the necessary packages required for fine-tuning.
# Install the necessary packages
!pip install -q -U accelerate bitsandbytes git+https://github.com/huggingface/transformers.git
!pip install datasets -q
!pip install peft -qAccess Token
Once step one is successfully executed, we will export the hugging face access token.
from huggingface_hub import login
login("hf_yOuRtoKenGOeSHerE")
Import Libraries
Next, we will import all the necessary libraries.
import os
from datasets import load_dataset, load_from_disk
from transformers import PaliGemmaProcessor, PaliGemmaForConditionalGeneration, BitsAndBytesConfig, TrainingArguments, Trainer
import torch
from peft import get_peft_model, LoraConfigLoad Data
Let's load the dataset! We will utilize the visual question-and-answer dataset from Hugging Face for the model finetuning. Also, we are only considering a small chunk of the data for this tutorial, but please feel free to change this.
ds = load_dataset('HuggingFaceM4/VQAv2', split="train[:10%]") For the preprocessing steps, we will remove a few columns from the data that are not required. Once done, we will split the data for training and validation.
cols_remove = ["question_type", "answers", "answer_type", "image_id", "question_id"]
ds = ds.remove_columns(cols_remove)
ds = ds.train_test_split(test_size=0.1)
train_ds = ds["train"]
val_ds = ds["test"]{'multiple_choice_answer': 'yes', 'question': 'Is the plane at cruising altitude?', 'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=640x480 at 0x7FC3DFEDB110>}Load Processor
Load the processor containing the image processing and tokenization part and preprocess our dataset.
from transformers import PaliGemmaProcessor
model_id = "google/paligemma-3b-pt-224"
processor = PaliGemmaProcessor.from_pretrained(model_id)
There are different versions of the model such as paligemma-3b-pt-224, paligemma-3b-pt-448, and paligemma-3b-pt-896. In our case, we will use the 224x224 version as the high-resolution models (448x448, 896x896) require significantly more memory. However, these models are beneficial for more accuracy and fine-grained tasks like OCR. But the 224x224 versions are suitable for most purposes.
Set the device to 'cuda' to use the GPU and load the model. We will Specify that the model should use bfloat16 (Brain Float 16) precision for its parameters. bfloat16 is a 16-bit floating point format that helps speed up computation and reduces memory usage while maintaining a similar range to float32.
device = "cuda"
image_token = processor.tokenizer.convert_tokens_to_ids("<image>")
model = PaliGemmaForConditionalGeneration.from_pretrained(model_id, torch_dtype=torch.bfloat16).to(device)
Model Training
The following steps are used to set up the model for conditional generation, specifically configuring which parts of the model should be trainable and remain fixed (frozen).
We will set the requires_grad attribute of each parameter to False, indicating that these parameters should not be updated during backpropagation. This effectively "freezes" the vision tower, preventing its weights from being modified during training. This assumes that the image encoder has already learned useful general features from a large dataset.
Furthermore, we will set the requires_grad attribute of each parameter to True, ensuring that these parameters will be updated during backpropagation. This makes the multi-modal projector trainable, allowing its weights to be optimized during training.
We will load the model, and freeze the image encoder and the projector, and only fine-tune the decoder. If your images are within a particular domain, which might not be in the dataset the model was pre-trained with, you might want to skip freezing the image encoder—Hugging Face Blog.
# Freeze Vision Tower Parameters (Image Encoder)
for param in model.vision_tower.parameters():
param.requires_grad = False
# Enable Training for Multi-Modal Projector Parameters (Fine-Tuning the Decoder)
for param in model.multi_modal_projector.parameters():
param.requires_grad = TrueWhy Freeze the Image Encoder and Projector?
- General Features: The image encoder (vision tower) has typically been pre-trained on a large and diverse dataset (e.g., ImageNet). It has learned to extract general features useful for a wide range of images.
- Pre-Trained Integration: The multi-modal projector has also been pre-trained to integrate features from different modalities effectively. It is expected to perform well without further fine-tuning.
- Resource Efficiency: Freezing these parts of the model reduces the number of trainable parameters, making the training process faster and requiring less computational resources.
Why Fine-Tune the Decoder?
- Task Specificity: The decoder must be fine-tuned for the specific task. Fine-tuning allows it to learn how to generate the appropriate output based on the particular types of input it will receive in your application.
Define a 'collate_fn' function. The function returns the final batch of tokens containing the tokenized text, images, and labels, all converted to the appropriate format and moved to the right device for efficient computation.
def collate_fn(examples):
texts = ["answer " + example["question"] for example in examples]
labels= [example['multiple_choice_answer'] for example in examples]
images = [example["image"].convert("RGB") for example in examples]
tokens = processor(text=texts, images=images, suffix=labels,
return_tensors="pt", padding="longest")
tokens = tokens.to(torch.bfloat16).to(device)
return tokensThe Quantized Model
Load the model in 4-bit for QLoRA. This will reduce memory usage and speed up inference and training while maintaining performance.
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_type=torch.bfloat16
)
lora_config = LoraConfig(
r=8,
target_modules=["q_proj", "o_proj", "k_proj", "v_proj", "gate_proj", "up_proj", "down_proj"],
task_type="CAUSAL_LM",
)
model = PaliGemmaForConditionalGeneration.from_pretrained(model_id, quantization_config=bnb_config, device_map={"":0})
model = get_peft_model(model, lora_config)
model.print_trainable_parameters()trainable params: 11,298,816 || all params: 2,934,765,296 || trainable%: 0.3849989644964099
Configure Optimizer
We will now configure the optimizer, number of epochs, learning rate, etc., for training. These settings are adjustable as needed.
args=TrainingArguments(
num_train_epochs=2,
remove_unused_columns=False,
output_dir="output",
logging_dir="logs",
per_device_train_batch_size=16,
gradient_accumulation_steps=4,
warmup_steps=2,
learning_rate=2e-5,
weight_decay=1e-6,
adam_beta2=0.999,
logging_steps=100,
optim="adamw_hf",
save_strategy="steps",
save_steps=1000,
push_to_hub=True,
save_total_limit=1,
bf16=True,
report_to=["tensorboard"],
dataloader_pin_memory=False
)Finally, we will begin the training by initializing the trainer. Pass the training dataset, data collating function (collate_fn), and the training arguments defined in the previous step. Then, call the train function to start the training.
trainer = Trainer(
model=model,
train_dataset=train_ds,
# eval_dataset=val_ds,
data_collator=collate_fn,
args=args
)
trainer.train()
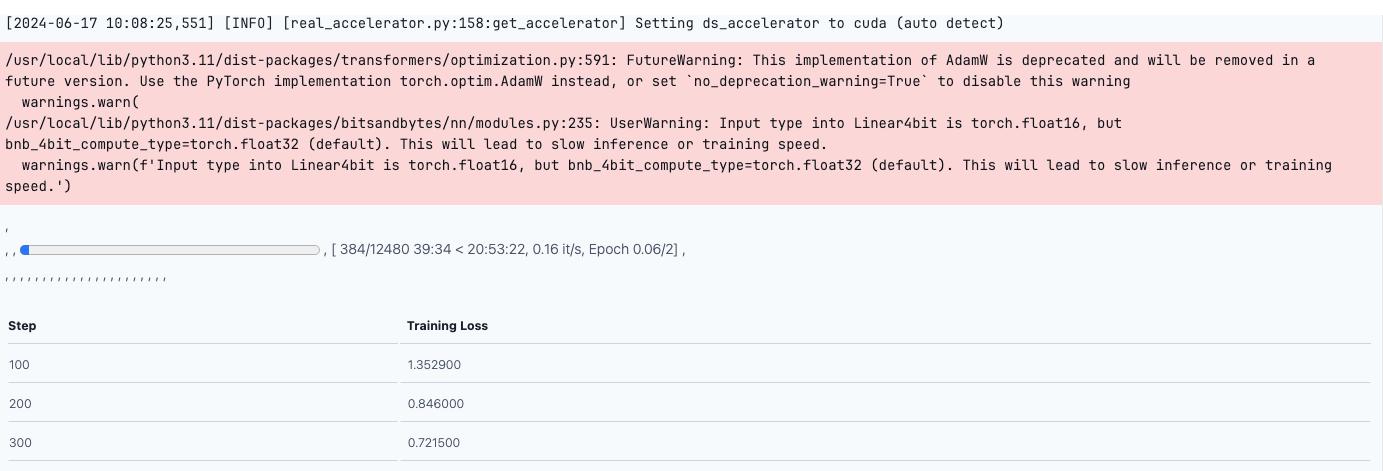
This will start the training, and the training loss will decrease with every epoch. Once the model is ready, we can upload it to Hugging Face for inferencing.
# Save the model in HuggingFace
trainer.push_to_hub('shaoni/paligemma_VQAv2')And you have successfully fine-tuned a VLM!!
Bring this project to life
Conclusion
The model PaliGemma shows incredible advancements in vision-language models. The model demonstrates the potential of AI in understanding and interacting with visual data. PaliGemma’s ability to accurately identify object locations and segmentation masks in images highlights its versatility and power. Fine-tuning PaliGemma using a custom dataset can enhance the model's performance for specific tasks, ensuring higher accuracy and relevance in real-world applications.
Vision-language models (VLMs) have numerous real-world applications that are transforming various industries. In healthcare, they can assist doctors by analyzing medical images and providing detailed descriptions, aiding in faster and more accurate diagnoses. In e-commerce, VLMs enhance the shopping experience by allowing users to search for products using images or generate detailed descriptions of items. These models create interactive learning materials for education that combine visual and textual information, making complex concepts easier to understand. Additionally, VLMs improve accessibility by describing visual content to visually impaired individuals, helping them navigate their environments more effectively.
These applications showcase the potential of VLMs to make technology more intuitive, accessible, and impactful in our daily lives.










