

In this article, we will learn how to run inference using the quantized version of IDEFICS and fine-tune IDEFICS-9b using Paperspace A100 GPU. We will also fine-tune IDEFICS 9B, a variant of the innovative visual language model. This fine-tuning process involves techniques like LoRa, which are specifically designed to enhance the model's performance in certain areas.
The A100 GPUs on Paperspace are powerful and versatile tools designed for high-performance computing tasks. Leveraging NVIDIA's Ampere architecture, these GPUs offer exceptional processing power, making them ideal for AI, machine learning, and data analytics workloads. When it comes to running inference and fine-tuning IDEFICS-9 b, the high processing power of these GPUs can significantly speed up the process, allowing you to iterate and experiment more quickly.
With up to 90 GB of memory, these GPUs can efficiently handle large datasets and complex models. Paperspace's cloud infrastructure ensures scalable and flexible access to these GPUs, enabling developers and researchers to accelerate their projects without the need for significant upfront investment in hardware. The combination of advanced technology and ease of use makes A100 GPUs on Paperspace a valuable resource for cutting-edge computational tasks.
What is IDEFICS?
IDEFICS (Image-aware Decoder Enhanced à la Flamingo with Interleaved Cross-attentionS) is an open-access visual language model that can process sequences of images and text to produce text outputs, similar to GPT-4.
The model is built on DeepMind's Flamingo model, which isn't publicly available. IDEFICS uses publicly available data and models, specifically LLaMA v1 and OpenCLIP, and is offered in two versions: a base version and an instructed version, each available in 9 billion and 80 billion parameter sizes.
Recently, IDEFICS2 was released. The model is trained to answer questions about images, such as 'What color is the car?' or 'How many people are in the picture? '. It can also describe visual content, create stories grounded in multiple images, extract information from documents, and perform basic arithmetic operations.
What is fine-tuning?
Fine-tuning is a process that involves taking a pre-trained model and training it for a specific task using a specific dataset. This process involves updating the model's weights based on the new task's data, typically with a lower learning rate, to make slight adjustments without drastically altering the pre-trained knowledge.
Pre-trained models are typically trained on large, diverse datasets and capture many features. They are trained to perform well on a specific task, such as sentiment analysis, image classification, or any domain-specific application. Using data specific to the new task, the model can learn the nuances and specifics of that data, leading to improved accuracy and performance.
Fine-tuning requires significantly less computational resources and time than training a model from scratch.
In this case, we will use 'TheFusion21/PokemonCards' to fine-tune the model. Here is the data structure of this dataset.
{
"id": "pl1-1",
"image_url": "https://images.pokemontcg.io/pl1/1_hires.png",
"caption": "A Stage 2 Pokemon Card of type Lightning with the title ""Ampharos"" and 130 HP of rarity ""Rare Holo"" evolved from Flaaffy from the set Platinum and the flavor text: ""None"". It has the attack ""Gigavolt"" with the cost Lightning, Colorless, the energy cost 2 and the damage of 30+ with the description: ""Flip a coin. If heads, this attack does 30 damage plus 30 more damage. If tails, the Defending Pokemon is now Paralyzed."". It has the attack ""Reflect Energy"" with the cost Lightning, Colorless, Colorless, the energy cost 3 and the damage of 70 with the description: ""Move an Energy card attached to Ampharos to 1 of your Benched Pokemon."". It has the ability ""Damage Bind"" with the description: ""Each Pokemon that has any damage counters on it (both yours and your opponent's) can't use any Poke-Powers."". It has weakness against Fighting +30. It has resistance against Metal -20.",
"name": "Ampharos",
"hp": "130",
"set_name": "Platinum"
}Fine-tuning IDEFICS-9B
Bring this project to life
Installation
We will start by installing a few necessary packages. We recommend our users to click the link provided with the article to spin up the notebook and start working.
!pip install -q datasets
!pip install -q git+https://github.com/huggingface/transformers.git
!pip install -q bitsandbytes sentencepiece accelerate loralib
!pip install -q -U git+https://github.com/huggingface/peft.git
!pip install accelerate==0.27.2We will install the datasets library. This library provides tools for accessing and managing datasets for training and evaluating machine learning models. We are also installing transformers and bitsandbytes for efficient fine-tuning.
Bitsandbytes is an incredible library that allows loading models in 4-bit precision, making it extremely useful for fine-tuning large language models with Qlora.
Once these packages are successfully installed we will import the necessary libraries.
#import the libraries
import torch
from datasets import load_dataset
from peft import LoraConfig, get_peft_model
from PIL import Image
from transformers import IdeficsForVisionText2Text, AutoProcessor, Trainer, TrainingArguments, BitsAndBytesConfig
import torchvision.transforms as transformsLoad the Quantized Model
Next, we will load the quantized version of the model, so let's get the load the model. We will select the device as 'CUDA'; if 'CUDA' is not available we will use CPU.
device = "cuda" if torch.cuda.is_available() else "cpu"
checkpoint = "HuggingFaceM4/idefics-9b"
#load the model in 4-bit precision
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.float16,
llm_int8_skip_modules=["lm_head", "embed_tokens"],
)
processor = AutoProcessor.from_pretrained(checkpoint, use_auth_token=True)
We will load the model in 4-bit precision, which reduces memory usage and can speed up processing. Additionall,y we will use a technique called double quantization, a technique that can improve the accuracy of the 4-bit quantized model. Next,a processor is initializedr to handle the model's inputs and outputs using the pre-trained checkpoint.
model = IdeficsForVisionText2Text.from_pretrained(checkpoint, quantization_config=bnb_config, device_map="auto")
This code initializes the IdeficsForVisionText2Text model by loading a pre-trained version from the specified checkpoint. Next, we will apply the quantization settings defined in bnb_config to load the model in an efficient 4-bit precision format.
Additionally, the code uses automatic device mapping to distribute the model's components across the available hardware, optimizing for performance and resource utilization.
Once the downloads are over, we will print the model.
print(model)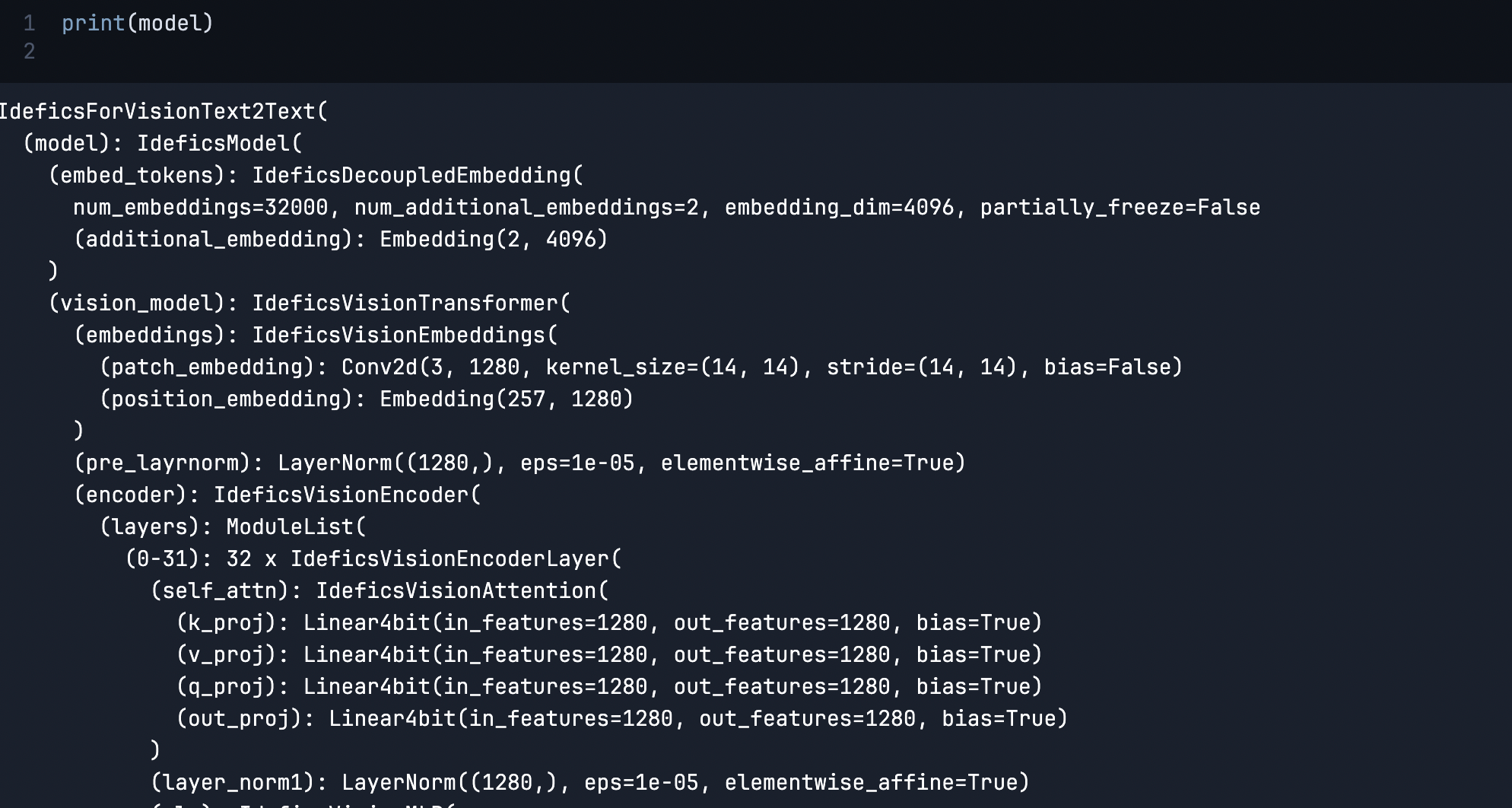
This prints the entire model pipeline with the layer and embedding details.
Inference
We will use this model for inference and test the model.
def model_inference(model, processor, prompts, max_new_tokens=50):
tokenizer = processor.tokenizer
bad_words = ["<image>", "<fake_token_around_image>"]
if len(bad_words) > 0:
bad_words_ids = tokenizer(bad_words, add_special_tokens=False).input_ids
eos_token = "</s>"
eos_token_id = tokenizer.convert_tokens_to_ids(eos_token)
inputs = processor(prompts, return_tensors="pt").to(device)
generated_ids = model.generate(**inputs, eos_token_id=[eos_token_id], bad_words_ids=bad_words_ids, max_new_tokens=max_new_tokens, early_stopping=True)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(generated_text)The function processes input prompts, generates text using the model while filtering out unwanted tokens, and prints the resulting text. The function utilizes the tokenizer and processor to handle text tokenization and decoding this in turn ensures that the generated text adheres to specified constraints.
url = "https://hips.hearstapps.com/hmg-prod/images/dog-puppy-on-garden-royalty-free-image-1586966191.jpg?crop=0.752xw:1.00xh;0.175xw,0&resize=1200:*"
prompts = [
# "Instruction: provide an answer to the question. Use the image to answer.\n",
url,
"Question: What's on the picture? Answer:",
]
model_inference(model, processor, prompts, max_new_tokens=5)
Question: What's on the picture? Answer: A puppy.
We will prepare the dataset that we will use for our fine-tuning task.
def convert_to_rgb(image):
# `image.convert("RGB")` would only work for .jpg images, as it creates a wrong background
# for transparent images. The call to `alpha_composite` handles this case
if image.mode == "RGB":
return image
image_rgba = image.convert("RGBA")
background = Image.new("RGBA", image_rgba.size, (255, 255, 255))
alpha_composite = Image.alpha_composite(background, image_rgba)
alpha_composite = alpha_composite.convert("RGB")
return alpha_composite
def ds_transforms(example_batch):
image_size = processor.image_processor.image_size
image_mean = processor.image_processor.image_mean
image_std = processor.image_processor.image_std
image_transform = transforms.Compose([
convert_to_rgb,
transforms.RandomResizedCrop((image_size, image_size), scale=(0.9, 1.0), interpolation=transforms.InterpolationMode.BICUBIC),
transforms.ToTensor(),
transforms.Normalize(mean=image_mean, std=image_std),
])
prompts = []
for i in range(len(example_batch['caption'])):
# We split the captions to avoid having very long examples, which would require more GPU ram during training
caption = example_batch['caption'][i].split(".")[0]
prompts.append(
[
example_batch['image_url'][i],
f"Question: What's on the picture? Answer: This is {example_batch['name'][i]}. {caption}</s>",
],
)
inputs = processor(prompts, transform=image_transform, return_tensors="pt").to(device)
inputs["labels"] = inputs["input_ids"]
return inputs
# load and prepare dataset
ds = load_dataset("TheFusion21/PokemonCards")
ds = ds["train"].train_test_split(test_size=0.002)
train_ds = ds["train"]
eval_ds = ds["test"]
train_ds.set_transform(ds_transforms)
eval_ds.set_transform(ds_transforms)The convert_to_rgb function ensures images are in RGB format, to handle different types of images. The ds_transforms function processes a batch of examples by transforming images, preparing text prompts, and converting everything into a format suitable for model training or inference. The function helps to apply necessary transformations, tokenizes the prompts, and sets up the inputs and labels for the model.
We will load the 'TheFusion21/PokemonCards' as suggested by hugging face to fine-tune the model. However, please feel free to use any dataset with the correct format.
LoRA
Low-rank adaptation (LoRA) is a PEFT technique that reduces a large matrix into two smaller low-rank matrices within the attention layers, significantly reducing the number of parameters that need fine-tuning.
model_name = checkpoint.split("/")[1]
config = LoraConfig(
r=16,
lora_alpha=32,
target_modules=["q_proj", "k_proj", "v_proj"],
lora_dropout=0.05,
bias="none",
)
model = get_peft_model(model, config)This code configures and applies Low-Rank Adaptation (LoRA) to our model IDEFICS9b:
- Extract the Model Name: From the checkpoint, extract the model.
- Configure LoRA: Set LoRA parameters, including the rank of the low-rank matrices to 16, target modules, dropout, and bias handling.
- Set Dropout: Sets a dropout rate of 5% for LoRA. Dropout is a regularization technique to prevent overfitting by randomly setting some of the input units to zero during training.
- Apply LoRA to the Model: Modify the model to include LoRA in the specified layers with the provided configuration.
model.print_trainable_parameters()
trainable params: 19,750,912 || all params: 8,949,430,544 || trainable%: 0.2206946230030432
Training
Next, we will finetune the model,
training_args = TrainingArguments(
output_dir=f"{model_name}-pokemon",
learning_rate=2e-4,
fp16=True,
per_device_train_batch_size=2,
per_device_eval_batch_size=2,
gradient_accumulation_steps=8,
dataloader_pin_memory=False,
save_total_limit=3,
evaluation_strategy="steps",
save_strategy="steps",
save_steps=40,
eval_steps=20,
logging_steps=20,
max_steps=20,
remove_unused_columns=False,
push_to_hub=False,
label_names=["labels"],
load_best_model_at_end=True,
report_to=None,
optim="paged_adamw_8bit",
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_ds,
eval_dataset=eval_ds,
)
trainer.train()[20/20 , Epoch 0/1]
| Step | Training Loss | Validation Loss |
|---|---|---|
| 20 | 1.450000 | 0.880157 |
| 40 | 0.702000 | 0.675355 |
Out[23]:TrainOutput(global_step=40, training_loss=1.0759869813919067, metrics={'train_runtime': 403.1999, 'train_samples_per_second': 1.587, 'train_steps_per_second': 0.099, 'total_flos': 1445219210656320.0, 'train_loss': 1.0759869813919067, 'epoch': 0.05})
This code will start the training process according to the specified parameters, such as the learning rate, precision, batch sizes, gradient accumulation, and check pointing strategy. We use a 16-bit floating point precision for faster and more efficient training and will use the optimizer for 8-bit precision.
# check generation after finetuning
url = "https://images.pokemontcg.io/pop6/2_hires.png"
prompts = [
url,
"Question: What's on the picture? Answer:",
]
# check generation again after finetuning
check_inference(model, processor, prompts, max_new_tokens=100)Question: What's on the picture? Answer: This is Lucario. A Stage 2 Pokemon Card of type Fighting with the title Lucario and 90 HP of rarity Rare evolved from Pikachu from the set Neo Destiny and the flavor text: It can use its tail as a whip
Conclusion
With this, we reached the end of the article. We were able to fine-tune our model using the Pokemon dataset successfully. We can push our model to hugging faces and use the model for inferencing.
Fine-tuning multimodal models demands carefully balancing computational resources and training strategies to achieve the best outcomes.
The NVIDIA A100 GPU, available through platforms like Paperspace, is an excellent choice for fine-tuning multimodal models due to its high performance, large memory capacity, and scalability. These features allow efficient handling of complex and large-scale tasks involved in integrating visual and textual data, leading to faster and more effective model training and deployment.
We hope you enjoyed the article!
References
- The notebook is contributed by Léo Tronchon, Younes Belkada, and Stas Bekman, additionally, the IDEFICS model has been contributed by: Lucile Saulnier, Léo Tronchon, Hugo Laurençon, Stas Bekman, Amanpreet Singh, Siddharth Karamcheti, and Victor Sanh Code reference
- Introducing Idefics2: A Powerful 8B Vision-Language Model for the community
- Dataset Used










{kind=link}