

Google recently introduced a new light weight vision-model PaliGemma. This model was released on the 14 May 2024 and has multimodal capabilities.
A vision-language model (VLM) is an advanced type of artificial intelligence that integrates visual and textual data to perform tasks that require understanding and generating both images and language. These models combine techniques from computer vision and natural language processing, enabling them to analyze images, generate descriptive captions, answer questions about visual content, and even engage in complex visual reasoning.
VLMs can understand context, infer relationships, and produce coherent multimodal outputs by leveraging large-scale datasets and sophisticated neural architectures. This makes them powerful tools for applications in fields such as image recognition, automated content creation, and interactive AI systems.
Gemma is a family of lightweight, cutting-edge open models developed using the same research and technology as the Gemini models. PaliGemma is a powerful open vision language model (VLM) that was recently added to the Gemma family.
What is PaliGemma?
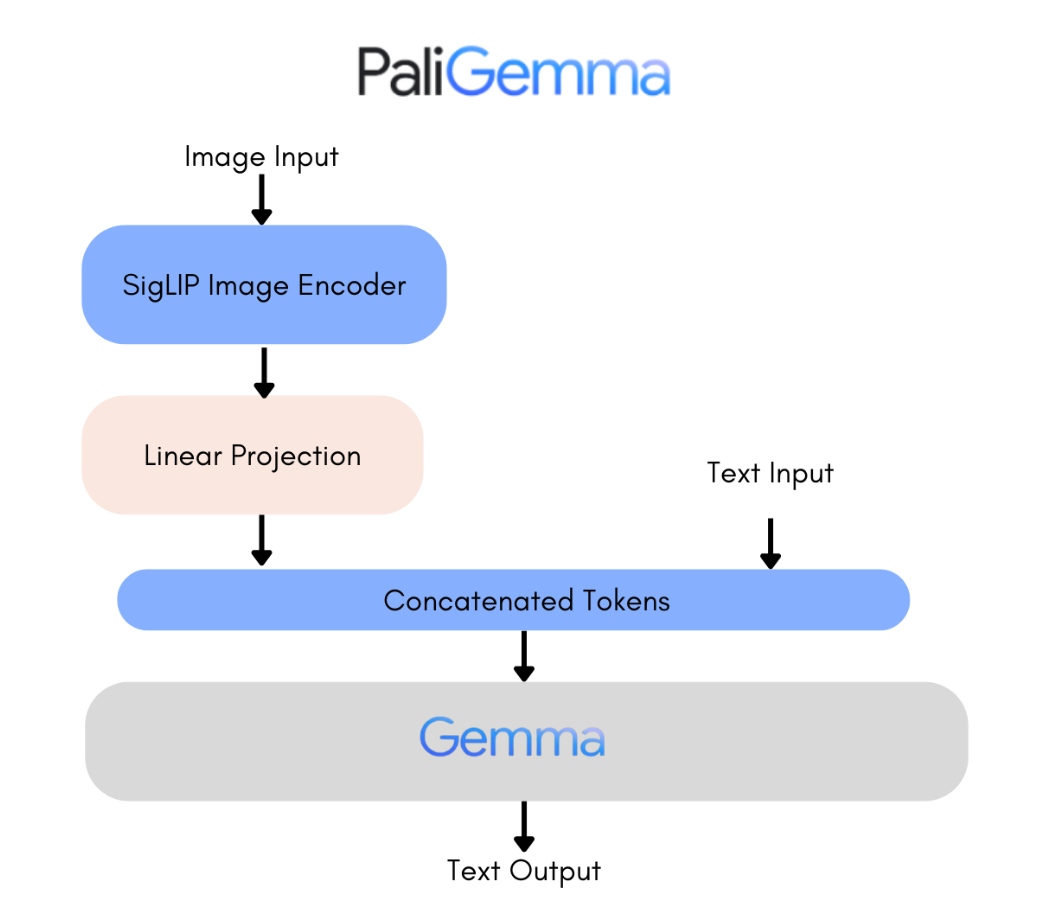
PaliGemma is a powerful new open vision-language model inspired by PaLI-3, built using the SigLIP vision model and the Gemma language model. It's designed for top-tier performance in tasks like image and short video captioning, visual question answering, text recognition in images, object detection, and segmentation.
Both the pretrained and fine-tuned checkpoints are open-sourced in various resolutions, plus task-specific ones for immediate use.
PaliGemma combines SigLIP-So400m as the image encoder and Gemma-2B as the text decoder. SigLIP is a SOTA model capable of understanding images and text, similar to CLIP, featuring a jointly trained image and text encoder. The combined PaliGemma model, inspired by PaLI-3, is pre-trained on image-text data and can be easily fine-tuned for tasks like captioning and referring segmentation. Gemma, a decoder-only model, handles text generation. By integrating SigLIP's image encoding with Gemma via a linear adapter, PaliGemma becomes a powerful vision-language model.
Overview of PaliGemma Model Releases
- Types of Models:
- PT Checkpoints:
- Pretrained models for fine-tuning downstream tasks.
- Mix Checkpoints:
- Pretrained models fine-tuned on a mixture of tasks.
- Suitable for general-purpose inference with free-text prompts.
- Intended for research purposes only.
- FT Checkpoints:
- Fine-tuned models specialized on different academic benchmarks.
- Available in various resolutions.
- Intended for research purposes only.
- PT Checkpoints:
- Model Resolutions:
- 224x224
- 448x448
- 896x896
- Model Precisions:
- bfloat16
- float16
- float32
- Repository Structure:
- Each repository contains checkpoints for a given resolution and task.
- Three revisions are available for each precision.
- The main branch contains float32 checkpoints.
- bfloat16 and float16 revisions contain corresponding precisions.
- Compatibility:
- Separate repositories are available for models compatible with 🤗 transformers and the original JAX implementation.
- Memory Considerations:
- High-resolution models (448x448, 896x896) require significantly more memory.
- High-resolution models are beneficial for fine-grained tasks like OCR.
- Quality improvement is marginal for most tasks.
- 224x224 versions are suitable for most purposes.
Try out PaliGemma with Paperspace
Bring this project to life
We will explore how to use 🤗 transformers for PaliGemma inference.
Let us first, install the necessary libraries with the update flag to ensure we are using the latest versions of 🤗 transformers and other dependencies.
!pip install -q -U accelerate bitsandbytes git+https://github.com/huggingface/transformers.gitnotebook_login() and enter your access token by running the cell below.Input Image

input_text = "how many dogs are there in the image?"
Next, we will import the necessary libraries and import AutoTokenizer, PaliGemmaForConditionalGeneration, and PaliGemmaProcessor from the transformers library.
Once the import is done we will load the pre-trained PaliGemma model and the model is loaded with torch.bfloat16 data type, which can provide a good balance between performance and precision on modern hardware.
from transformers import AutoTokenizer, PaliGemmaForConditionalGeneration, PaliGemmaProcessor
import torch
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model_id = "google/paligemma-3b-mix-224"
model = PaliGemmaForConditionalGeneration.from_pretrained(model_id, torch_dtype=torch.bfloat16)
processor = PaliGemmaProcessor.from_pretrained(model_id)Once the code is executed, the processor will preprocesses both the image and text.
inputs = processor(text=input_text, images=input_image,
padding="longest", do_convert_rgb=True, return_tensors="pt").to("cuda")
model.to(device)
inputs = inputs.to(dtype=model.dtype)
Next, use the model to generate the text based on the input question,
with torch.no_grad():
output = model.generate(**inputs, max_length=496)
print(processor.decode(output[0], skip_special_tokens=True))Output:-
how many dogs are there in the image?
1
Load the model in 4-bit
We can also load model in 4-bit and 8-bit, to reduce the computational and memory resources required for training and inference. First, initialize the BitsAndBytesConfig.
from transformers import BitsAndBytesConfig
import torch
nf4_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_use_double_quant=True,
bnb_4bit_compute_dtype=torch.bfloat16
)
Next, reload the model and pass in above object as quantization_config,
from transformers import AutoTokenizer, PaliGemmaForConditionalGeneration, PaliGemmaProcessor
import torch
device="cuda"
model_id = "google/paligemma-3b-mix-224"
model = PaliGemmaForConditionalGeneration.from_pretrained(model_id, torch_dtype=torch.bfloat16,
quantization_config=nf4_config, device_map={"":0})
processor = PaliGemmaProcessor.from_pretrained(model_id)Generate the output,
with torch.no_grad():
output = model.generate(**inputs, max_length=496)
print(processor.decode(output[0], skip_special_tokens=True))Output:-
how many dogs are there in the image?
1
Using PaliGemma for Inference: Key Steps
- Tokenizing the Input Text:
- Text is tokenized as usual.
- A
<bos>token is added at the beginning. - A newline token (
\n) is appended, which is important as it was part of the model's training input prompt.
- Adding Image Tokens:
- The tokenized text is prefixed with a specific number of
<image>tokens. - The number of
<image>tokens depends on the input image resolution and the SigLIP model's patch size. - For PaliGemma models:
- 224x224 resolution: 256
<image>tokens (224/14 * 224/14). - 448x448 resolution: 1024
<image>tokens. - 896x896 resolution: 4096
<image>tokens.
- 224x224 resolution: 256
- The tokenized text is prefixed with a specific number of
- Memory Considerations:
- Larger images result in longer input sequences, requiring more memory.
- Larger images can improve results for tasks like OCR, but the quality gain is usually small for most tasks.
- Test your specific tasks before opting for higher resolutions.
- Generating Token Embeddings:
- The complete input prompt goes through the language model's text embeddings layer, producing 2048-dimensional token embeddings.
- Processing the Image:
- The input image is resized to the required size (e.g., 224x224 for the smallest resolution models) using bicubic resampling.
- It is then passed through the SigLIP Image Encoder to create 1152-dimensional image embeddings per patch.
- These image embeddings are projected to 2048 dimensions to match the text token embeddings.
- Combining Image and Text Embeddings:
- The final image embeddings are merged with the
<image>text embeddings. - This combined input is used for autoregressive text generation.
- The final image embeddings are merged with the
- Autoregressive Text Generation:
- Uses full block attention for the complete input (image +
<bos>+ prompt +\n). - Employs a causal attention mask for the generated text.
- Uses full block attention for the complete input (image +
- Simplified Inference:
- The processor and model classes handle all these details automatically.
- Inference can be performed using the high-level transformers API, as demonstrated in previous examples.
Applications
Vision-language models like PaliGemma have a wide range of applications across various industries. Few examples are listed below:
- Image Captioning: Automatically generating descriptive captions for images, which can enhance accessibility for visually impaired individuals and improve the user experience.
- Visual Question Answering (VQA): Answering questions about images, which can allow more interactive search engines, virtual assistants, and educational tools.
- Image-Text Retrieval: Retrieving relevant images based on textual queries and vice versa, facilitating content discovery and search in multimedia databases.
- Interactive Chatbots: Engaging in conversations with users by understanding both textual inputs and visual context, leading to more personalized and contextually relevant responses.
- Content Creation: Automatically generating textual descriptions, summaries, or stories based on visual inputs, aiding in automated content creation for marketing, storytelling, and creative industries.
- Artificial Agents: Utilizing these technology to power robots or virtual agents with the ability to perceive and understand the surrounding environment, enabling applications in robotics, autonomous vehicles, and smart home systems.
- Medical Imaging: Analyzing medical images (e.g., X-rays, MRIs) along with clinical notes or reports, assisting radiologists in diagnosis and treatment planning.
- Fashion and Retail: Providing personalized product recommendations based on visual preferences and textual descriptions, enhancing the shopping experience and increasing sales conversion rates.
- Optical character recognition: Optical character recognition (OCR) involves extracting visible text from an image and converting it into machine-readable text format. Although it sounds straightforward, implementing OCR in production applications can pose significant challenges.
- Educational Tools: Creating interactive learning materials that combine visual content with textual explanations, quizzes, and exercises to enhance comprehension and retention.
These are just a few examples, and the potential applications of vision-language models continue to expand as researchers and developers explore new use cases and integrate these technologies into various domains.
Conclusion
In conclusion, we can say that PaliGemma represents a significant advancement in the field of vision-language models, offering a powerful tool for understanding and generating content based on images. With its ability to seamlessly integrate visual and textual information, PaliGemma opens up new path for research and application across a wide range of industries. From image captioning to optical character recognition and beyond, PaliGemma's capabilities hold promise for driving innovation and addressing complex problems in the digital age.
We hope you enjoyed reading the article!












:strip_icc()/cute-dog-breeds-we-can-t-get-enough-of-4589340-hero-04aba92c6fbb4651b7fa1f54823a1a6d.jpg?ref=blog.paperspace.com){kind=link}