
Introduction
Kaggle is a popular code and data science workspace from Google that supports a large number of datasets and public data science notebooks.
Paperspace Gradient is a platform for building and scaling real-world machine learning applications, and Gradient Notebooks is a web-based Jupyter IDE with free GPUs.
In this blogpost we'll take a look at Google Kaggle and Paperspace Gradient and determine strengths and weaknesses of each product depending on use case.
Let's begin!
What makes a good workspace for machine learning?
The key to a good machine learning pipeline is accessibility. This includes access to good information, a robust environment for processing, and a reliable method for disseminating results and trained models.
Machine learning engineers and data scientists often run into challenges during one or more of the stages of data science exploration.
Kaggle has found great success as a place to make accessible public datasets. Kaggle excels at maintaining rich datasets and providing the basis for data science competitions.
Gradient has found success providing accelerated computing instances with GPUs and providing a viable path to productionizing projects made on the platform.
This blog will attempt to breakdown the differences between two approaches – those of Kaggle and those of Gradient – in their attempts to build a fully featured machine learning exploration and MLOps platform.
Each section of this article will compare and contrast a different aspect or feature of the two products, and you can use the table of contents on the right to navigate to each section.
GPUs
Both Kaggle and Gradient offer free GPUs. Let's take a look at the free GPU types.
Free Types available
| Kaggle | Gradient Notebooks (free) | Gradient Notebooks (paid) | |
|---|---|---|---|
| Type | P100 | M4000 | P5000 |
| Cores | 2 | 8 | 8 |
| RAM (GB) | 13 | 8 | 16 |
Kaggle:
GPU: TESLA P100 with 2 CPU cores and 13 GB RAM
TPU: TPU v3-8 with 4 CPU cores and 16 GB RAM
Gradient:
GPU: Free tier: QUADRO M4000 with 8 CPU cores and 8 GB RAM
Pro tier (Users get free access to more GPUs for 8 USD/month): QUADRO P4000 with 8 cpu cores and 8 GB Ram, QUADRO P5000 with 8 cores and 16 GB RAM, and the Quadro RTX4000 with 8 CPU cores and 8 GB RAM
TPU: Not available on Gradient
Accessibility
Kaggle:
GPU/TPU access is limited to 30 hours per week for each type of processor on Kaggle. Due to high demand, there are also availability issues so you may be placed in a queue upon requesting a GPU in their notebook platform.
Gradient:
GPU access is only limited by availability.
Free GPU Availability
Kaggle:
Each notebook editing session has 9 hour of available execution time before it is disrupted, and only 20 minutes of idle time (meaning that 20 minutes of inactivity will cause the kernel to be shutdown).
Gradient:
GPU access is only limited by availability. Each free-GPU instance will shut down after 6 hours of runtime, but has unlimited idle time during that period.
Pricing
Kaggle:
Kaggle is completely free on the actual Kaggle platform. You can however gain access to Kaggle notebooks on the paid version of Google Cloud Project, and this is how a Kaggle user can access more customizable environments with different GPUs, docker containers to use, etc. The actual process of setting this up can be very involved and time consuming however, so we recommend you follow this guide.
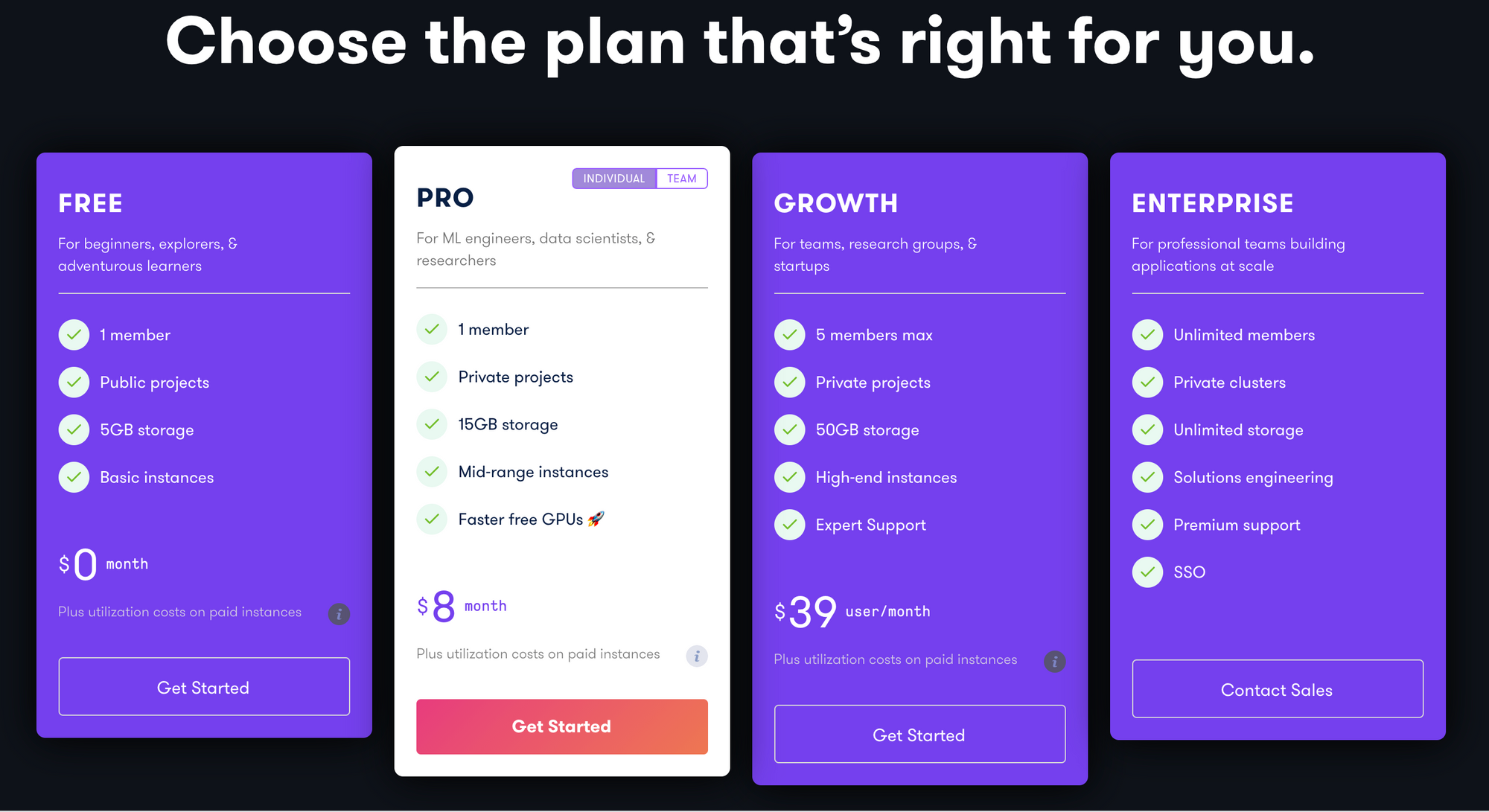
Gradient:
Gradient has three pricing tiers available to the individual customer, with increasing amount and quality of free GPU's available at each tier of pricing. The first paid tier expands access to 3 new, free GPU types and 15 GB of storage for $8/mo.
Resources
Kaggle:
Competitions: A community based product, competitions allow Kaggle, third parties, and users to create and participate in ML related contests. This is famously one of the most popular places for such competitions, and was where the world renowned Netflix Prize was held.
Notebooks: A Jupyter Notebook like IDE with code and markdown cells, a terminal, and a somewhat customizable environment (CPU only, GPU, or TPU). Serves as place where users can conduct ML and data analytics on the easily accessible Kaggle datasets.
Gradient:
Notebooks: A Jupyter Notebook like IDE with code and markdown cells, a terminal, logs, versioning, and a very customizable environment. It serves as a place where users can explore their data, conduct ML and data analytics on either their own data or the publicly stored data in Gradient storage, and prepare their ML pipeline to be set up.
WorkFlows: Once exploration and initial analytics are completed and a workflow is determined, WorkFlows allow users to dynamically update their modeling pipeline by connecting to GitHub. This allows for versioned development of models as progress is made.
Deployments: Once a finalized model is determined and saved to Gradient's persistent storage, the Deployments resource allows users to deploy their new model as an API endpoint in a few simple steps, thereby sidestepping many of the headaches of Kubernetes, Docker, and framework setup.
Start working with Free GPUs on Gradient today!
Storage
Kaggle:
Users are mostly restricted to using Kaggle's builtin storage. They can connect to AWS s3 or similar products through their clients, but this is clunky compared to just using the Kaggle datasets functionalities.
Limited to 20 GB of working data in total across all notebooks.
Gradient:
On Gradient, users can use a large number of storage services, including Gradient's own persistent storage, AWS s3, and more.
Free tier users will be restricted to 5 GB of free storage per notebook on Gradient's persistent storage (with up to five projects made and one notebook running at any given time). Overages will be charged at .29 USD per GB of storage.
Notebook Features
Kaggle:
Pros:
- Instant startup speed (you have to wait for session to start once code is run however)
- Gallery of suggested projects for inspiration on notebook startup page
- Jupyer-like IDE
- Notebook scheduling
- Private and public notebooks
- Kaggle community allows for collaboration and easy work sharing
- 9 hour execution time limit
- Higher GPU RAM (13 GB) than Gradient Free Tier
- Completely free
- 20 GB storage across all notebooks
Cons:
- Difficult to customize notebook environment (container, workspace etc.). It is possible to do so through Google Cloud Project, but it is both attention and time intensive to migrate to a new platform and then set up the notebooks
- Short idle time of 20 minutes makes it hard to train models on big data without constant attention.
- 30 hour weekly limit on GPU powered notebooks
- No ability to access better or different GPU's without migrating to separate platform
Gradient:
Pros:
- Jupyter-like IDE
- Private and public notebooks
- Python, R, JavaScript, and more all work within notebooks
- Projects and teams format allows for easy collaboration within companies or teams
- Extremely customizable setup from workspace to container to GPU type that is easy to do
- No idle time limit (but 6 hour execution time limit on GPU powered notebooks)
- Access to Gradient persistent storage & ability to connect to outside storage providers like AWS s3
- Ability to upgrade to higher tiers and access better GPU's
- More CPU cores on Free tier instances than Kaggle (8 vs 2)
- Easy to switch to paid version and get more powerful resources
Cons:
- 6 hour execution time limit for free GPUs
- 5 GB persistent storage limit for free tier (ability to pay for more with overages at .29 USD/GB)
- No access to notebook terminals in free tier
Conclusion
Both platforms offer free access to worthwhile computing power and GPU accessibility, a robust environment for conducting ML/DL work using this compute, and a useful storage system integrated into the notebook to facilitate all of it.
While Kaggle has a distinct edge in its free GPU's RAM (13 GB vs. 8 GB in free tier), free available storage capacity (20 GB vs. 5 GB), and ability to schedule notebooks, Gradient's versatility seems to elevate it above the competition. Gradient Notebooks offer a much higher number of CPU cores in their free tier instances, no weekly limit on GPU access time, a more customizable notebook environment, and a more user friendly UX thanks to its extremely long idle time. Furthermore, the 2 other Gradient resources, Workflows and Deployments, separate Gradient's capabilities even further apart from Kaggle.











