
Introduction
The H100, Nvidia's latest GPU, is a powerhouse built for AI, boasting 80 billion transistors—six times more than the previous A100. This allows it to handle massive data loads much faster than any other GPU on the market.
AI or any deep learning applications need significant processing power to train and run effectively. The H100 comes with powerful computing capabilities, making the GPU perfect for any deep learning tasks. The GPU is built to train large language models (LLMs) for text generation, language translation, develop self-driving cars, medical diagnosis systems, and other AI-driven applications.
H100, built on Hopper architecture, is named after the famous computer scientist and U.S. Navy Rear Admiral Grace Hopper. It builds on the Turing and Ampere architectures, introducing a new streaming multiprocessor and a faster memory subsystem.
NYC2 datacenter.Powerful GPUs such as H100 are crucial hardware when it comes to training deep learning model. These beefy GPUs are built to handle vast amounts of data and compute complex operations easily which are very much necessary for training any AI models.
Why is GPU required for Deep Learning?
GPUs provide high parallel processing power which is essential to handle complex computations for neural networks. GPUs are designed to preform different calculations simultaneously and which in turn accelerates the training and inference for any large language model. Additionally, GPUs can handle large datasets and complex models more efficiently, enabling the development of advanced AI applications.
Several deep learning algorithms require powerful GPUs to perform efficiently. Some of these include:
- Convolutional Neural Networks (CNNs): Used for image and video recognition, CNNs rely on extensive parallel processing for handling large datasets and complex computations.
- Recurrent Neural Networks (RNNs) and Long Short-Term Memory Networks (LSTMs): These are used for sequential data like time series and natural language processing, requiring significant computational power to manage their intricate architectures.
- Generative Adversarial Networks (GANs): GANs consist of two neural networks competing against each other, demanding substantial processing power to generate high-quality synthetic data.
- Transformer Networks: Utilized in natural language processing tasks, such as BERT and GPT models, these networks need considerable computational resources for training due to their large-scale architectures and massive datasets.
- Autoencoders: Employed for tasks like dimensionality reduction and anomaly detection, autoencoders require powerful GPUs to efficiently process high-dimensional data.
- Gradient Descent: This fundamental optimization algorithm is used to minimize the loss function in neural networks. The large-scale computations involved in updating weights and biases during training are significantly accelerated by GPUs.
These algorithms benefit greatly from the parallel processing capabilities and speed offered by GPUs.
What is H100 GPU?
NVIDIA H100 Tensor Core GPU, is the next generation highest performing GPU specifically designed for advanced computing tasks in field for AI and deep learning.
The latest architecture includes 4th generation tensor cores and dedicated transformer engine which is responsible for significantly increasing the efficiency on AI and ML computation. This specialized hardware accelerates the training and inference of transformer-based models, which are crucial for large language models and other advanced AI applications.
H100 GPU Architecture and Features
The H100 GPU chip supports various precision types, including FP8, FP16, FP32, and FP64, impacting the accuracy and speed of calculations. It introduces a dedicated Transformer Engine to accelerate training and inference.
Fast, scalable, and secure, the H100 can connect with other H100 GPUs via the NVLink Switch System, enabling them to work as a unified cluster for exascale workloads (requiring at least one exaflop of computing power). It also supports PCIe Gen5 and features built-in data encryption for security.
The H100 can accelerate the training and inference of large language models by up to 30 times over the previous generation, facilitating the development of new AI applications like conversational AI, recommender systems, and vision AI.

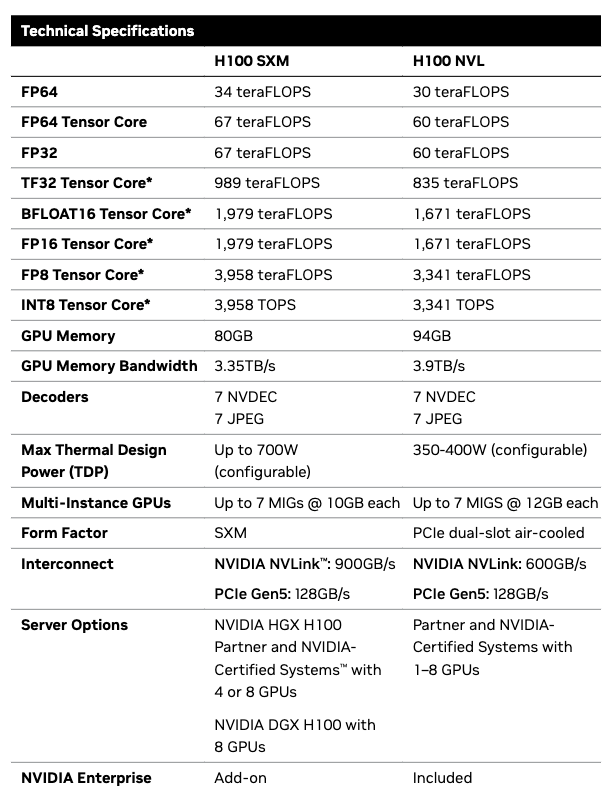
If you take a look at the data sheet provided for H100, the different columns provided below lists the performance and technical specification for this GPU.
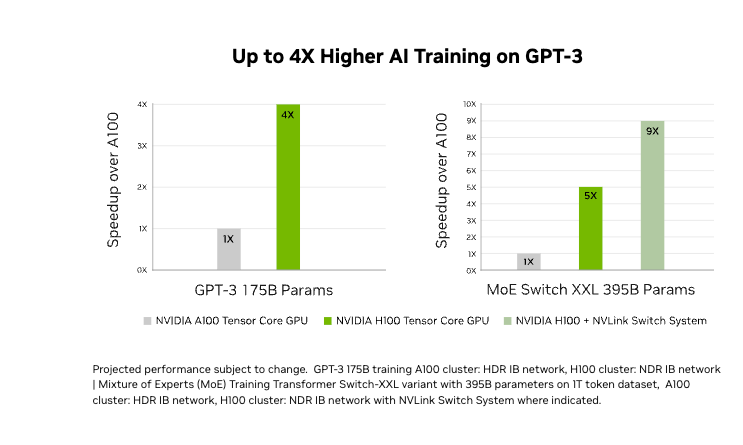
Transform Model Training
The 4th gen tensor cores and a transformer engine with FP8 precision making H100 to train 4 times faster when training GPT-3 (175B) models compared to previous generations. It combines advanced technologies like fourth-generation NVLink, providing 900 GB/s of GPU-to-GPU communication; NDR Quantum-2 InfiniBand networking, which speeds up communication between GPUs across nodes; PCIe Gen5; and NVIDIA Magnum IO™ software. These features ensure efficient scaling from small setups to large.
H100 PCIe Gen 5 GPU
The H100 PCIe Gen 5 configuration packs the same capabilities as the H100 SXM5 GPUs but operates at just 350 watts. It can connect up to two GPUs with an NVLink bridge, offering nearly five times the bandwidth of PCIe Gen 5. This setup is ideal for standard racks and is great for applications that use 1 or 2 GPUs, such as AI inference and some HPC tasks. Notably, a single H100 PCIe GPU delivers 65% of the performance of the H100 SXM5 while consuming only 50% of the power.
Notable Features
The NVIDIA H100 NVL GPU, equipped with several advanced features, optimizes performance and scalability for large language models (LLMs). Here’s a breakdown:

- Fourth-generation Tensor Cores: The H100 is up to 6 times faster at chip-to-chip communication compared to the A100. This speedup is due to several factors, including increased processing units (Streaming Multiprocessors or SMs), higher clock speeds, and improved architecture. Additionally, using the new FP8 data type, the H100 Tensor Cores achieve four times the computational rate of the A100's previous-generation 16-bit floating-point options.
- PCIe-based NVIDIA H100 NVL with NVLink Bridge: This setup uses PCIe (Peripheral Component Interconnect Express) for fast communication between the GPU and other components, and NVLink bridge technology to connect multiple GPUs, enhancing data transfer speeds and efficiency.
- Transformer Engine: A specialized hardware unit within the H100 designed to accelerate the training and inference of transformer-based models, which are commonly used in large language models. This new Transformer Engine uses a combination of software and custom Hopper Tensor
Core technology designed specifically to accelerate Transformer model training and
inference. - 188GB HBM3 Memory: High-Bandwidth Memory (HBM3) is used in the H100 NVL to provide large, fast memory capacity, crucial for handling the vast amounts of data processed by LLMs.
- Optimum Performance and Easy Scaling: The combination of these technologies allows for high performance and straightforward scalability, making it easier to expand computational capabilities across different data centers.
- Bringing LLMs to the Mainstream: These capabilities make it feasible to deploy large language models more widely and efficiently in various settings, not just in specialized, high-resource environments.
- Performance Improvement: Servers equipped with H100 NVL GPUs can increase the performance of LLMs like Llama 2 70B by up to 5 times compared to previous-generation NVIDIA A100 systems.
- Low Latency in Power-Constrained Environments: Despite the significant performance boost, the H100 NVL maintains low latency, which is crucial for real-time applications, even in environments where power consumption is a concern.
These advanced features of the H100 NVL GPU enhance the performance and scalability of large language models, making them more accessible and efficient for mainstream use.

The H100 GPU is highly versatile, compatible with a wide range of AI frameworks and libraries like TensorFlow, PyTorch, CUDA, cuDNN, JAX, and many other. This seamless integration simplifies adoption and future-proofs investments, making it an essential tool for AI researchers, developers, and data scientists.
How Paperspace Stands Out?
Paperspace now supports NVIDIA H100x1 with 80 and NVIDIA H100x8 with 640 GB GPU Memory and are available as on-demand compute.
Here are few key points on Paperspace's offering for NVIDIA H100 GPUs:
Performance Boost:
- NVIDIA H100 GPUs deliver massive performance improvements in AI and machine learning (AI/ML). They are up to 9 times faster in training AI models and up to 30 times faster in making predictions (inference) compared to the previous-generation NVIDIA A100 GPUs.
- Transformer Engine & 4th Gen Tensor Cores: These advanced technologies in the H100 GPUs enable these dramatic speedups, especially for large language models and synthetic media models.
Paperspace’s Offerings:
- Instance Options: Paperspace offers H100 GPUs as both on-demand (you can use them whenever needed) and reserved instances (you commit to using them for a set period, usually at a lower cost).
- Cost: H100 instances start at $2.24 per hour per GPU. Paperspace offers flexible billing options, including per-second billing and unlimited bandwidth, helping to manage and reduce costs.
“Training our next-generation text-to-video model with millions of video inputs on NVIDIA H100 GPUs on Paperspace took us just 3 days, enabling us to get a newer version of our model much faster than before. We also appreciate Paperspace’s stability and excellent customer support, which has enabled our business to stay ahead of the AI curve. - Naeem Ahmed, Founder, Moonvalley AI
Scalability:
- Multi-node Deployment: You can deploy up to 8 H100 GPUs together, which can work as a unified system thanks to their 3.2TBps NVIDIA NVLink interconnect. This setup is ideal for handling very large and complex models.

Ease of Use:
- Quick Setup: You can start using an H100 GPU instance within seconds. Paperspace’s "ML-in-a-box" solution includes everything needed: GPUs, Ubuntu Linux images, private network, SSD storage, public IPs, and snapshots, providing a complete and ready-to-use environment for machine learning.
Reliability and Support:
- 24/7 Monitoring: Paperspace’s platform is continuously monitored to ensure reliability. If any issues arise, their customer support is available to help, especially during high-traffic periods.
Paperspace’s new H100 GPU offering provides powerful, scalable, and cost-effective solutions for AI/ML tasks, making it easier and faster to train large models and perform complex computations.
“As Paperspace — an Elite member of the NVIDIA Cloud Service Provider Partner Program — launches support for the new NVIDIA H100 GPU, developers building and scaling their AI applications on Paperspace will now have access to unprecedented performance through the world's most powerful GPU for AI.” - Dave Salvator, Director of Accelerated Computing, NVIDIA
Conclusion
The NVIDIA H100 is a huge advancement in hig-performance computing and sets up a new bar in the AI field. With its cutting-edge architecture, including the new Transformer Engine and support for various precision types, the H100 is here to drive significant innovations in AI research and application.
Looking ahead, the H100's capabilities will likely accelerate the development of increasingly sophisticated models and technologies, shaping the future of artificial intelligence and high-performance computing. As organizations adopt these powerful GPUs, they will unlock new possibilities and push the boundaries of what’s achievable in AI and data science.
We hope you enjoyed reading the article!











