
Imagine making a computer to see and understand the world, much like how we humans recognize faces or spot objects. This tasks seems to be easy for human brain but for a computer not so much!
In this article we will break down the Convolutional Neural Networks in simpler terms.
Convolutional Neural Networks (CNNs) are like the digital eyes and brains that allow machines to make sense of images. The way computer looks at images is as a grid of numbers, these numbers are usually RGB numbers from 0 to 255.
In the world of Convolutional Neural Networks, we'll understand how computers look at pictures and figure out what's in them. From understanding the basics of how they "see" to the cool things they can do, get ready for a fun ride into the heart of this technology that's changing the way computers understand the visual wonders around us!
CNNs are primarily used to extract features from an input image by applying certain filters.
Why CNNs?
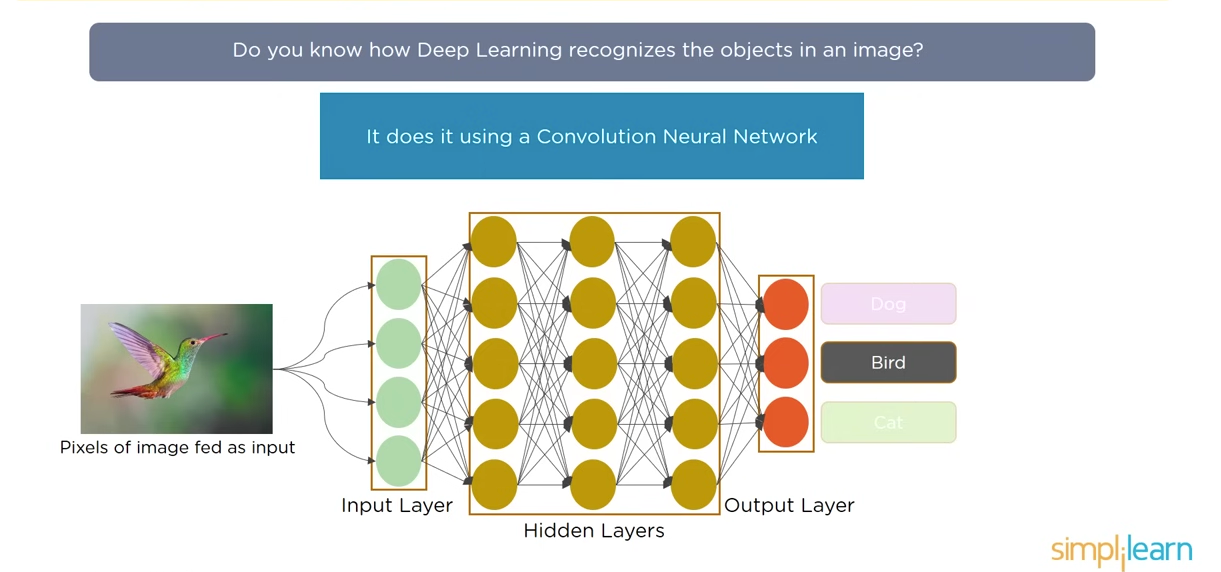
A CNN is a special type of ANN that gained its popularity for analyzing image and other classification problem as well. CNNs are great to detect pattern from an image and hence making it useful for image analysis. A CNN consists of input layer, hidden layer and the output layer. The hidden layer comprises of convolutional layer, pooling layer, and fully connected dense layers.
Now, the question might arise can we use ANN for image recognition?
Let us understand with an example!

In this case suppose we have a bird, the image is a coloured pic hence will have three RGB channel.
- The image size is 3082 × 2031, hence the first layer neurons will be 3082 x 2031 x 3 ~ 18 million
- Hidden layer neurons will almost be equal to 10 million
- Weights between first layer and hidden layer will come upto 19 mil x 10 mil ~ 190 million
Using a densely connected neural network for image classification brings about a significant computational burden, potentially this number could reach upto billions. This amount of computation is not only excessive but also unnecessary. Additionally, artificial neural networks (ANNs) tend to treat all pixels uniformly, regardless of their spatial proximity. Given that image recognition predominantly relies on local features, this approach becomes a drawback. The challenge lies in the network's struggle to detect objects in an image when pixel arrangements are changed, this is a potential limitation encountered with ANN.
Convolution Operation and Stride Jump
In the human brain, the process of image recognition involves the examination of individual features by specific sets of neurons. These neurons are subsequently linked to another set that identifies distinct features, and this set, in turn, connects to another group responsible for aggregating the outcomes to determine whether the image depicts a cat, dog, or bird.
Similar to this concept is used in CNN, where features are detected using filters or kernels. This filter is applied to the input data or image by sliding it over the entire input. At each cell element wise multiplication is carried out, and results are summed up to produce a single value for that specific cell. Furthermore, the filter takes a stride jump and the same operation is repeated until the entire image is captured. The output of this operation is known as a feature map.
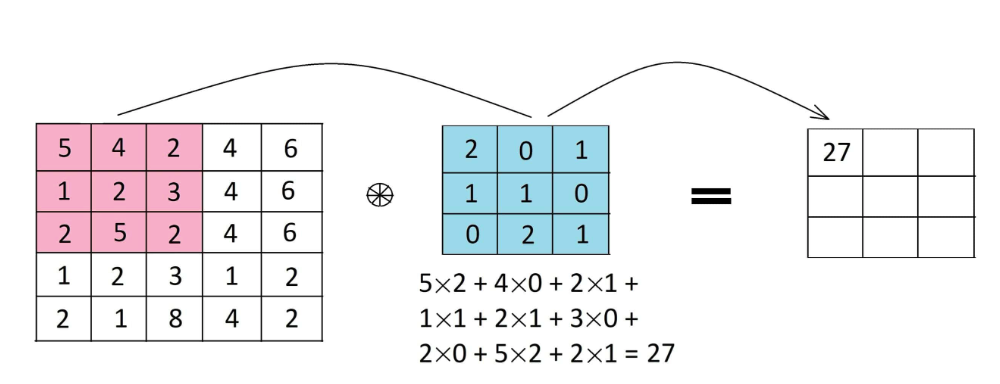
Feature maps are responsible for capturing specific patterns depending on the filter used. As the filter takes the stride jump across the input, it detects different local patterns, capturing spatial information.
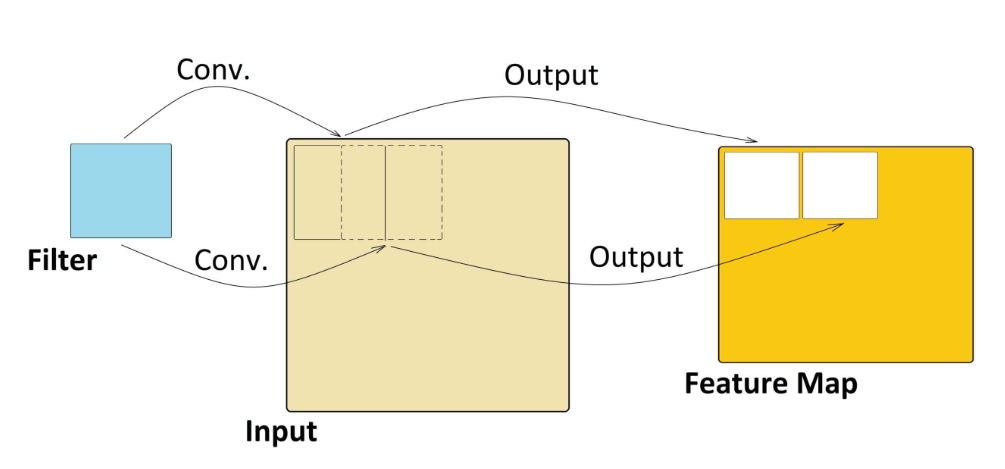
In simple terms, when we use a filter or perform a convolution operation, we're creating a feature map that highlights a specific characteristic. Think of these filters as special tools that can detect particular features, like an "eye detector" for a bird. When we apply this detector to an image, it scans through, and if it finds eyes, it marks their location on the feature map. Importantly, these filters don't care where the eyes are in the image; they'll find them regardless of the location because the filter slides across the entire image. Each filter is like a specialized feature detective, helping us identify different aspects of the image.

These filters can be 2D as well as 3D filter. For example a head filter will be a aggregated filter of eyes, tail, beak, etc., and this filter becomes a head detector. In a similar way there could be body detector. A complex feature would be able to locate a much intricate detail in an image. These features filters generates the feature maps.
Feature Maps
Feature map or activation map, are flattened array of numbers that capture specific patterns or features in an image. In computer vision, particularly in Convolutional Neural Networks (CNNs), feature maps are created by applying filters or kernels to input images. Each number in the feature map represents the level of activation of the corresponding feature in the input data. These features map are flattened to get a 1d array and is further connected to a dense fully connected neural network for classification task.
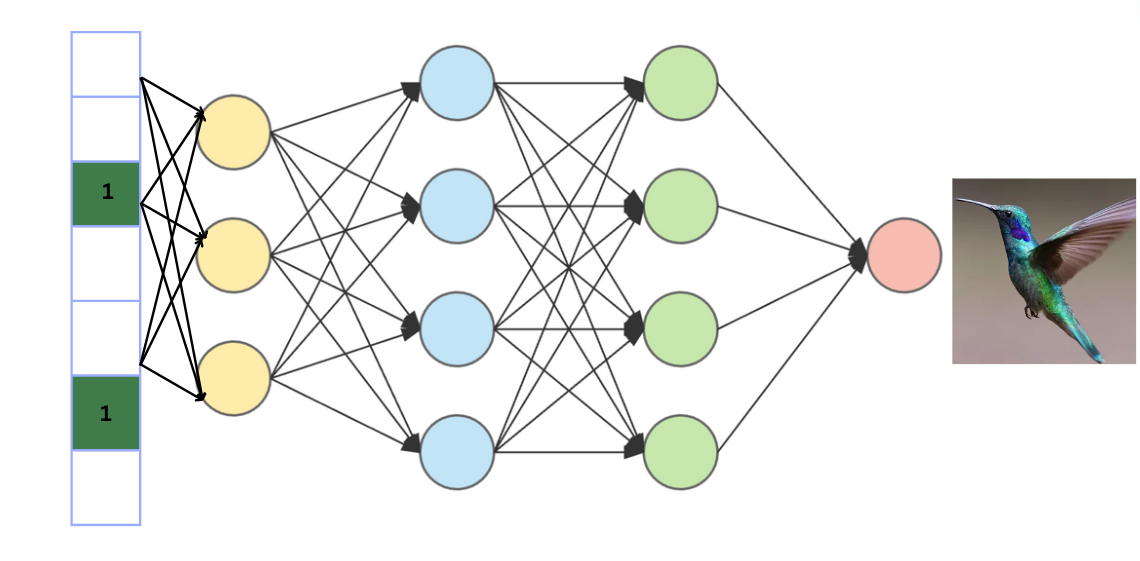
Why do we need a dense neural network?
The neural network deals with the fact that objects in pictures can be in different places and there might be many objects in one picture. Hence, first we use convolutional neural operation, that looks for different features in the image. This helps it recognize various patterns in the picture. Then, a dense neural network is used to figure out what is in the picture based on these features. So, the first part finds different details, and the second part decides what those details mean in terms of classification.
This is not all we also add an activation function typically after convolutional layer and fully connected deep neural layers. A very common activation functions is ReLu.
ReLu
ReLU activation is used to introduce non-linearity to our model. Essentially, it takes the feature map and replaces any negative values with zero, while leaving positive values unchanged. This simple mechanism of setting negative values to zero and retaining positive ones aids in making the model non-linear. This activation function also aids in eliminating vanishing gradient problem.
f(x) = max(0, x)
Dealing with heavy computation
By all of these calculations we still have not talked about the issue of heavy computation. To overcome this issue we use Pooling.
Pooling in simpler terms can be understood as summarizing information. For example to summarize a big picture, to understand what's in it but don't need every single detail. Pooling helps by reducing the size of the picture while keeping the important parts. It does this by looking at small chunks of the image at a time and picking the most important information from each chunk. For example, if it's looking at a group of four pixels, it might only keep the brightest one. This way, it shrinks the image while still capturing the main features, making it easier and faster for the computer to work with.
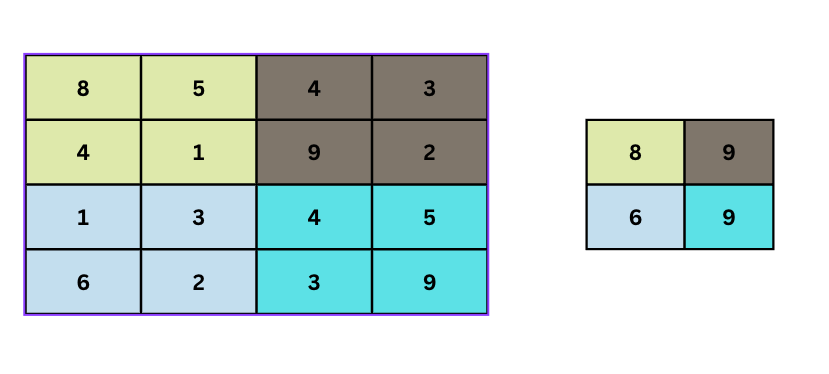
From the above illustration, an empty (2, 2) filter is slid over a (4, 4) image with a stride of 2. The maximum pixel value is extracted each time to form a new image. The resulting image is a resultant max pooled representation of the original image The resulting image is half the size of the original image. This helps is reducing the dimension and also the computation power. Pooling also reduces overfitting.
A typical CNN will have:-
- A convolution layer
- ReLu activation function layer
- Pooling
- Finally, at the end a fully connected dense neural network
Conclusion
To summarize, the main purpose of a convolutional neural network is to extract features, and the next part functions are like a artificial neural network. Convolution not only detects features but also reduces dimensionality. The three main advantages to this operation are first connection sparsity reducing overfitting, implying not every node is connected to every other node, as seen in dense networks. Second, convolution focuses on local regions of the image at a time, avoiding impact on the entire image. Third, combining convolution and pooling provides location-invariant feature detection. In simpler terms, convolutional neural networks excel at finding features in images, helping to prevent overfitting, and ensuring flexibility in recognizing features across different locations.
ReLu activtion introduces non-linearity and further reduces overfitting. Also data augmentation is used to generate variation in samples.









