
NVIDIA recently unveiled Grace – a new ARM-based CPU chip optimized for neural network workloads.
This got us wondering – does Grace signal the beginning of the end to 15+ years of dominance by 64-bit x86 architectures in high-performance computing (HPC)? And what might it mean for those of us building deep learning applications? Will we be porting our code over to ARM anytime soon?
We wanted to tackle these and other questions set off by NVIDIA's announcement by taking a look at some of the history of HPC. Hopefully we can understand a little bit first about how we got here and then what that might mean for the future of deep learning.
Supercomputing early days
Supercomputing has a long and fascinating history – from the original IBM, CDC, and Cray machines of the 1960s that measured performance in megaFLOPS (10^6 floating point operations per second) to the machines of today that are scheduled to break the exaFLOP barrier (10^18 floating point operations per second) in late 2021.
Supercomputing is also something of a spectator sport. Twice a year the Top 500 list is published to coincide with the two largest supercomputing conferences – and competition to place at the top of this list is fierce. The Top 500 list has been published continuously since 1993 and it's a Big Deal for all the players involved – from the sites that host these clusters to the manufacturers of the components that make up these clusters to the scientific communities (and nations) involved in the use of these clusters.
It's also worth noting that the Top 500 is limited to publishing only clusters that are public. Although not a topic for this blogpost, supercomputing also has a long history of secrecy – from Alan Turing cracking the German naval Enigma in the 1940s through to the Advanced Simulation and Computing Program which to this day is responsible for maintaining the US nuclear stockpile.
But that's for another time. What we want to get into today is to understand where we've been with supercomputing architectures and where we're headed – especially as it relates to machine learning and deep learning applications that are becoming increasingly parallelized.
The age of vector processors

In 1966, both Control Data Corporation (CDC) and Texas Instruments (TI) brought to market machines that utilized vector processing. From then on, early supercomputing was ruled by vector processor or array processor machines. Most dominant early on were mainframe manufacturers CDC and International Business Machines (IBM) until the mid-1970s when Cray (a spinoff of CDC) took the baton.
A National Research Council report explains the early advantage of vector architecture as such:
The Cray-1 supported a vector architecture in which vectors of floating-point numbers could be loaded from memory into vector registers and processed in the arithmetic unit in a pipelined manner at much higher speeds than were possible for scalar operands. Vector processing became the cornerstone of supercomputing.
By the time the famous Cray-1 launched in at Los Alamos National Lab in 1976, Cray was manufacturing incredibly efficient vector processing machines. The architectures that CDC, Cray, and others pioneered maintained dominance all the way into the 1990s.
It's especially worth noting this fact today because there are some modern parallels between the technical architectures of these early Cray machines and the parallel computing architectures of modern GPU-based machines.
Personal PCs change the game
While the early supercomputing pioneers were busy building single-processor machines, Intel produced the first commercially available microprocessor in 1971. By the early 1980s the technology was mature enough – meaning ready for mass production – that the personal computing revolution could begin to take shape.
PCs entered the mainstream around 1984 when the Macintosh first captured nationwide attention. With the benefit of hindsight we can see that Apple and other early PC assemblers were riding early tailwinds of a dramatic reduction in microprocessor costs.
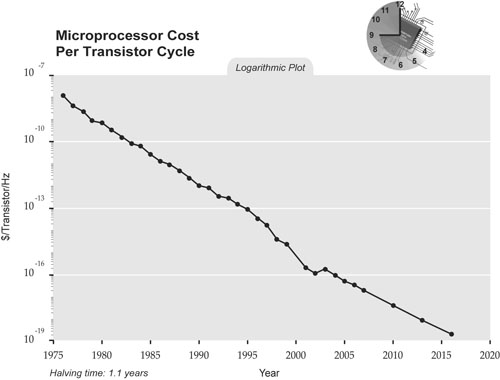
By the 1990s, Cray and other traditional supercomputing manufacturers who were continuing to produce single-processor machines would be unable to keep up with the price-to-performance ratio offered by commodity CPU architectures.
To understand why, it's helpful to see just how quickly the microprocessor market was growing:
During this time, microprocessor costs plummeted. And by 1995, Cray was bankrupt. As John Markoff wrote at the time for the New York Times:
But in the 1990s the transformation of the computing world wrought by the arrival of cheap and powerful microprocessor chips has dramatically undercut the multimillion-dollar "big iron" systems that have been Mr. Cray's hallmark. Moreover, the conclusion of the cold war has meant declining Government budgets for purchasing machines that were once the mainstay of the nation's weapons labs and at the heart of the "Star Wars" Strategic Defense Initiative.
The old "big iron" systems were replaced with commodity-style microprocessor architectures – a fact that has shaped the past 25 years of computing since the (first) demise of Cray.
POWER
The following graph shows the processor/architectures used by Top500 supercomputers since the inception of the list in the early 1990s. If we look all the way to the left we can see the last few years of Cray's dominance.
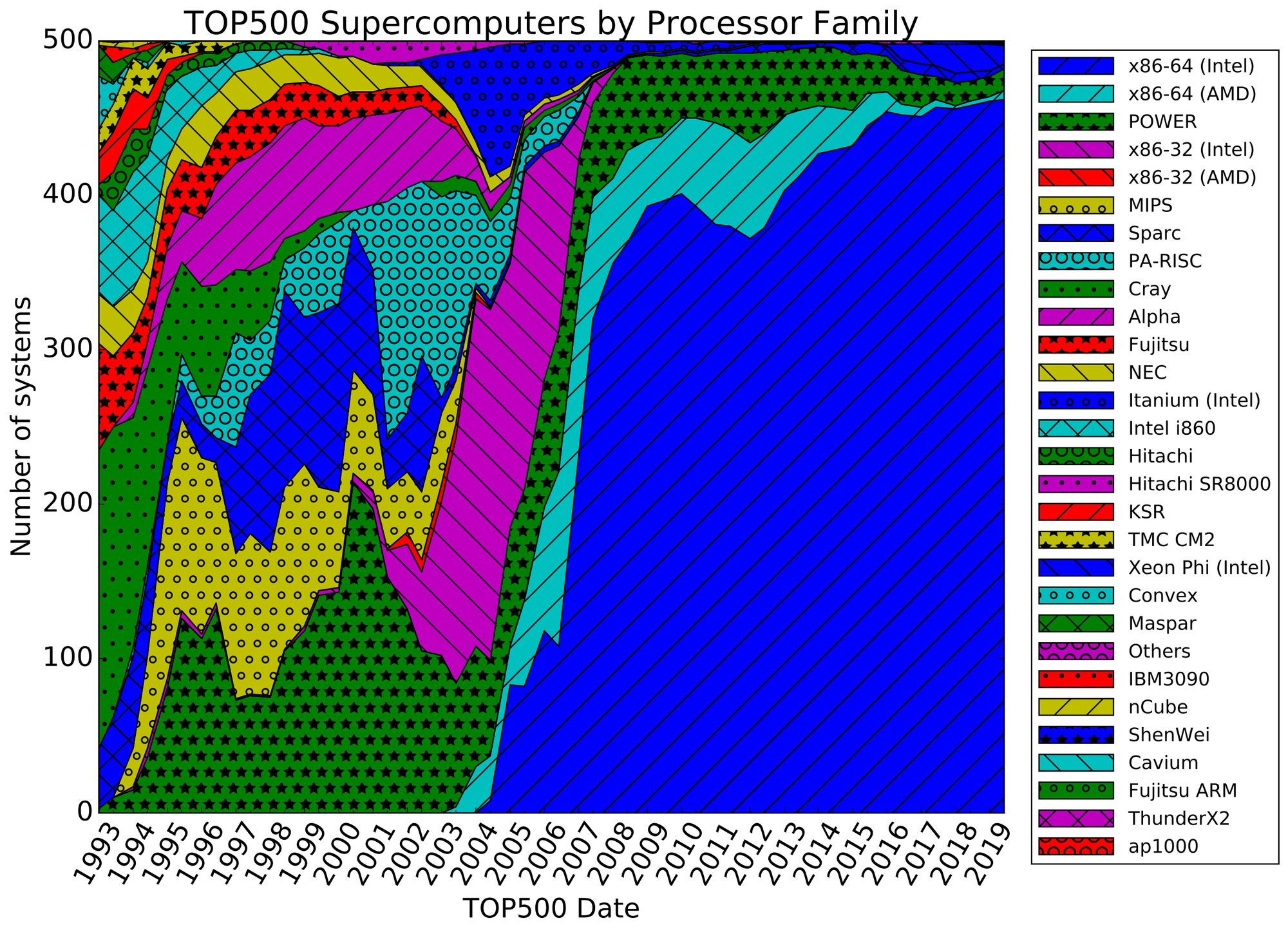
Soon after, we see the emergence of SPARC from Sun Microsystems and Alpha from DEC. Like IBM's POWER, these RISC architectures were heavily influenced by the work of Berkeley RISC (funded by ARPA) in the early 1980s.
The RISC project (along with the contemporaneous MIPS project at Stanford) set out to understand how to create a simpler CPU. The concept was to limit a processor's instruction set in such a way that it would still be able to perform the majority of frequently performed calculations while shedding complexity.
The early 1990s are also when we start to see massively parallel systems. The Intel Paragon could support 1000+ Intel processors by 1993. Fujitsu's Numerical Wind Tunnel shipped with QTY 166 vector processors in 1994. And by 1995 Cray too was shipping massively parallel systems with its T3E system.
Around the same time, we see the emergence of POWER (which later evolved into PowerPC) which IBM brought to market around 1990.
POWER would eventually cede market power in HPC over to x86 but not until x86 64-bit really took off. Until that time POWER was something of a transitional step. POWER compared favorably to 16 and 32-bit x86 for a limited amount of time but around 2004-2005, 64-bit x86 (first AMD and Intel quickly thereafter) started to take over the Top500.
With the emergence of parallelism (and soon 64-bit architectures), new architectures would soon supplant the old.
x86 takes over and the industry never looks back
It's not clear exactly when the industry decided to shift to x86 architectures, but one important event that occurred years earlier seems to have set the wheel in motion – when IBM selected the Intel 8088 for its PCs in the early 1980s.
It wasn't necessarily that Intel's x86 architecture was better than alternatives like the RISC-based PowerPC architectures we just learned about – but perhaps that Intel was simply better at keeping up with demand in the booming market.
Intel would go on to release the first 32-bit x86 chip in 1985 and by the early 2000s both Intel and AMD were successfully producing low-cost 64-bit x86 processors en masse.
By the mid-2000s x86-64 was powering 80%+ of the Top500 supercomputers.
And then, without much warning, by 2005 the free lunch is over – CPU clock speeds are no longer increasing the way they were for decades previously. We can actually see this phenomenon below in the couple of years of plateauing peak speeds that lead up to 2005.

Now all of a sudden we see that multi-core vector instruction set chips would need to be back on the menu. And the designers of massively parallel chips intended for rendering graphics – like the folks at NVIDIA – would certainly take notice.
The rise of accelerators
As early as 2003, many-core parallel processing on GPUs started to show tremendous promise compared to sequential processing on CPUs – even compared to multi-core CPUs.
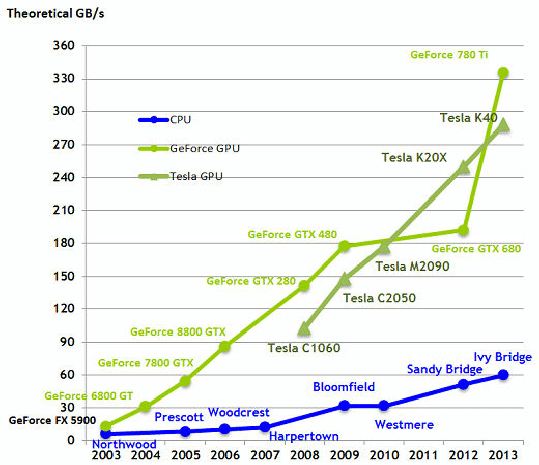
NVIDIA, recognizing the CPU bottleneck and looking to bring another usecase to GPUs aside from rendering graphics, released CUDA in 2007 to help developers run general purpose computing tasks on GPUs.
It's worth noting that the rise of accelerators is something of a return to form for supercomputing. The designs of massively parallel GPU-accelerated systems are closer to Cray than to x86 when it comes to architecture.
The rewards of GPU acceleration specifically have paid off better than anyone could have reasonably predicted. The world of HPC – for almost two decades dominated by x86 CPU architectures – has shifted wholesale its center of focus to GPU accelerators.
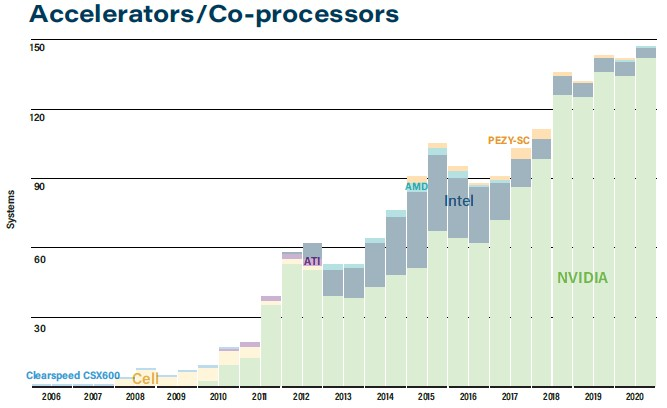
As of 2020, 146 of the Top500 are using NVIDIA GPU accelerator cards – including 6 systems of the most recent Top 10.
NVIDIA has not gone unchallenged in the accelerator card space. Seeing the opportunity in the CPU-to-vector accelerator transition, Intel in 2011 released the Knight's Ferry / Knight's Corner architecture (later known as Xeon Phi) which was a many-core processor based on x86 but with a different threading model and extra SIMD lanes (AVX series instructions).
Despite promising simplicity (no need to rewrite your code to get it to run on x86), it appears that Intel unfortunately was unprepared to compete or else unsuccessful competing with the momentum of NVIDIA's CUDA rollout and exploding community.
ARM economics
What is not obvious today from looking at the Top500 is that despite the fact that x86 dominates the list nearly as much as Linux does (which is a perfect 500/500), the x86 architecture itself is not exactly essential for modern HPC.
In the era of GPU accelerators, most of the work done by the CPU in an HPC environment is simply feeding data to the GPU. There isn't really a high architectural dependency. The big limitations on the CPU side today are memory and PCI-e bandwidth. (This is why solutions like NVLink appear primed to help NVIDIA dramatically increase CPU performance.)
Just as there was a time when POWER/PowerPC was the default choice for HPC and a time when early multi-core AMD processors were the first choice for new HPC systems – it looks today like there is a chance that ARM supplants Intel-based x86 as the dominant architecture for the world's fastest clusters.
ARM, which NVIDIA acquired for $40B this past year, was originally inspired by the folks at RISC in the 1980s. The company formed in 1990 and using architecture much different than Intel's x86 their work lead to the Acorn Achimedes – the first RISC-based PC.
ARM chips are favored for very low power usage and high efficiency. They are also in the middle of a production boom – much like microprocessors at the start of the personal PC revolution of the 1990s. As one author puts it:
Arm-based products are evidently ubiquitous. Any ‘smart’ device is likely to contain Arm technology inside. Being the most popular microprocessor architecture, Arm reported its silicon partners shipped a record 6.7 billion Arm-based chips in the fourth quarter of 2020, more than other popular CPU instruction set architectures combined...While Arm has been the preferred CPU for virtually all smartphones, a Nvidia-Arm acquisition will have astounding impacts on the broader computing industry.
It's small wonder that the cost of ARM is decreasing so rapidly – we saw the same forcing function when PCs first drove x86 prices down. And it's not just smartphones that ARM has been powering. It's also things like IoT sensors, MacBooks, data center servers, and so on!
It should therefore not come as a surprise to learn that the #1 computer on the Top500 is the ARM-based Fugaku by Fujitsu, located in Kobe, Japan.
Fugaku features 158,976 A64FX processors (which, by the way, replaced and older SPARC processor) and will continue to be the fastest public computer on the planet until late 2021.
What this means for deep learning
For reasons of architecture, cost, and efficiency we may see an industry-wide transition from x86 to ARM in high performance computing and this transition may well filter down into deep learning computation.
Although much older as a subset of computing, HPC is an excellent bellwether for deep learning. The applications are extremely similar in the sense that tensor cores also benefit traditional HPC applications.
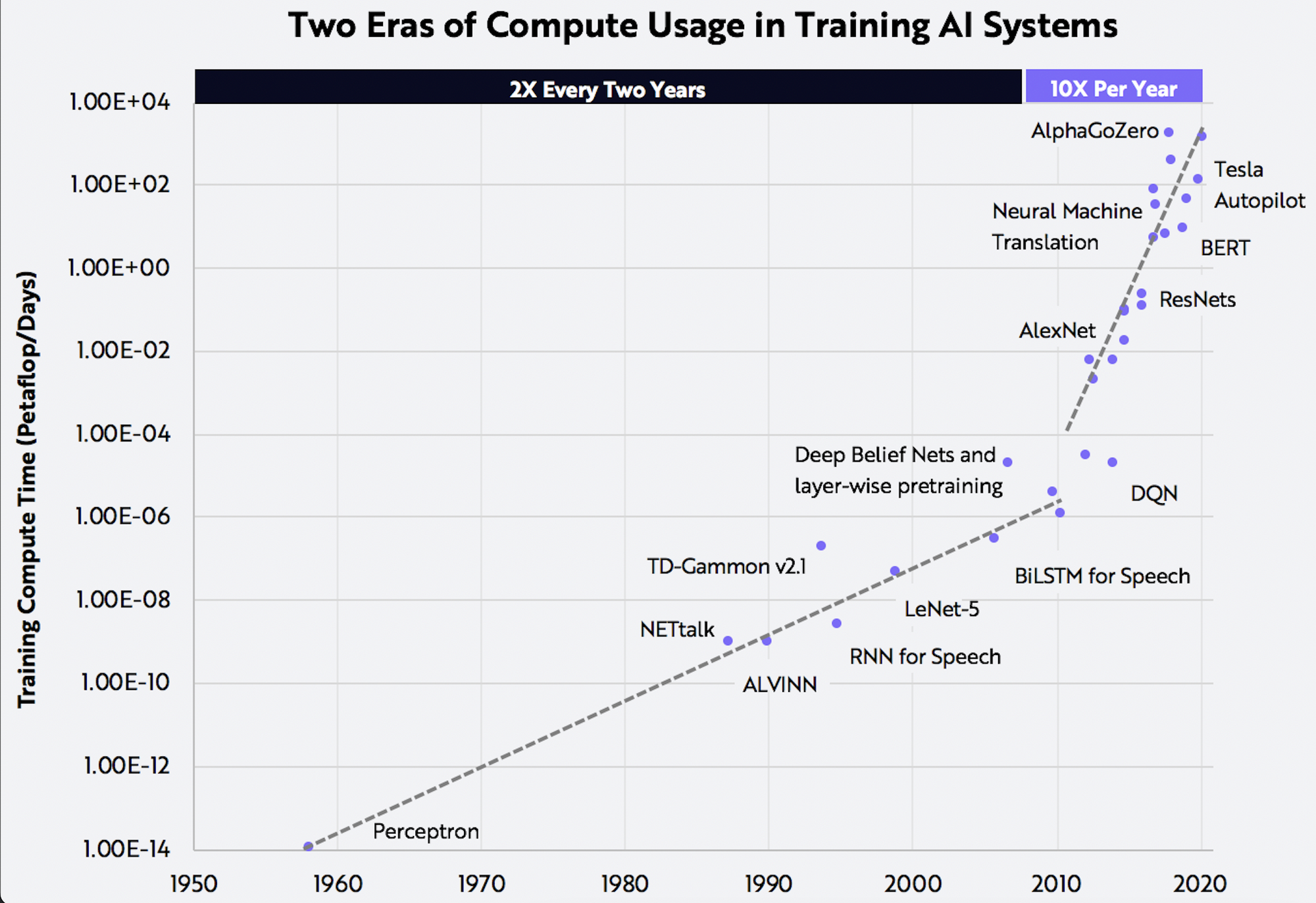
Computational requirements for training deep learning models are increasing yearly at an astronomical rate:
And simultaneously, the cost of computation is decreasing.
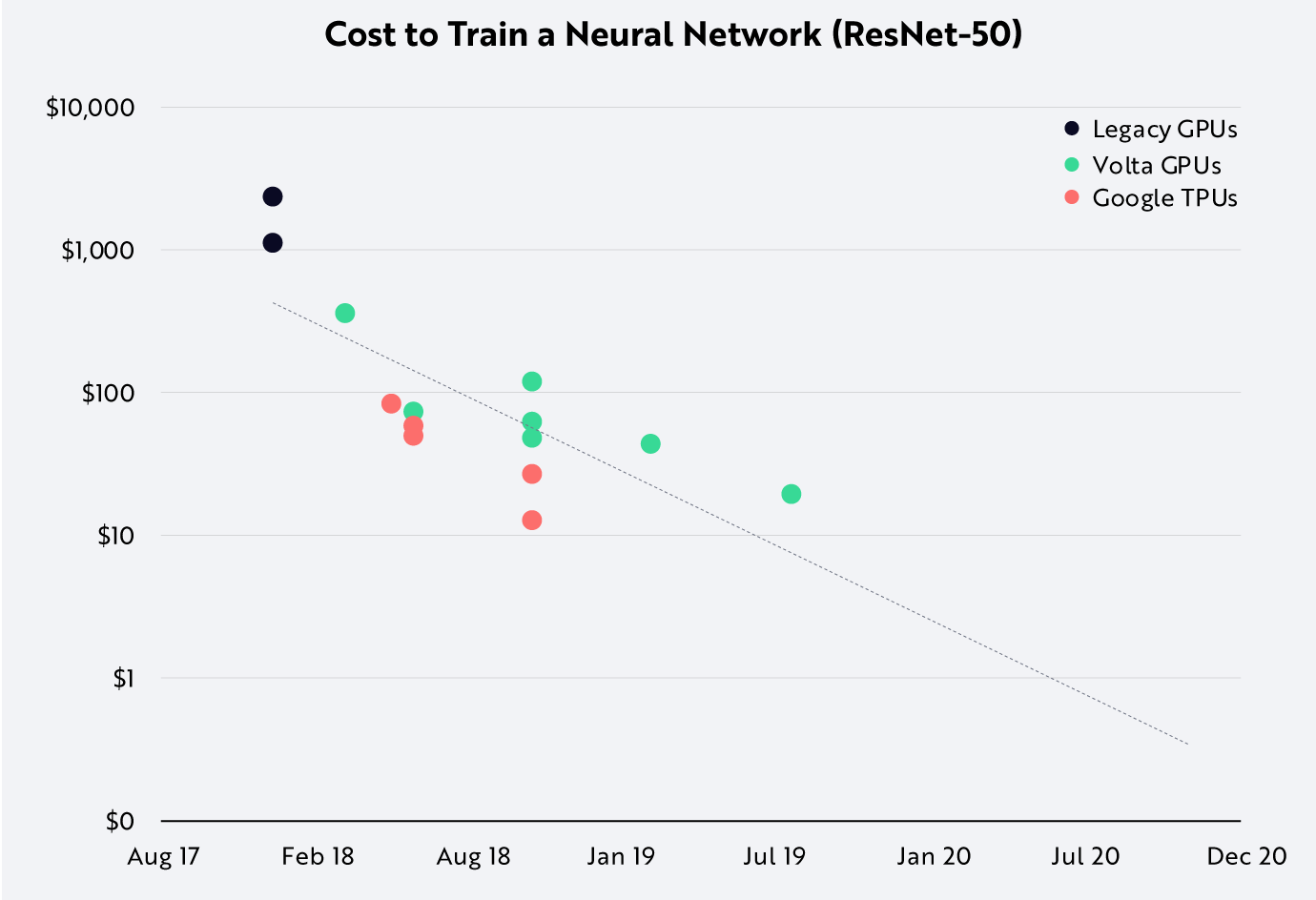
This is the same natural cycle for computation ever since the days of CDC and IBM mainframes: compute requirements increase while cost per unit of compute decreases.
Deep learning costs are rapidly decreasing. As one analyst writes:
Based on the pace of its cost decline, AI is in very early days. During the first decade of Moore’s Law, transistor count doubled every year—or at twice the rate of change seen during decades thereafter. The 10-100x cost declines we are witnessing in both AI training and AI inference suggest that AI is nascent in its development, perhaps with decades of slower but sustained growth ahead.
ARM represents an exciting path to satisfy deep learning's insatiable appetite for computing. The production volume is in place – to the tune of ~7B ARM units per quarter. The licensing model is in place as well – allowing for vendor extensions that can provide deep integration with accelerator cards. And the Top supercomputer in the world is already showing what's possible with an ARM-based architecture.
So is it reasonable to expect to see deep learning libraries ported over to ARM anytime soon?
The odds look promising. And if one thing is certain – if it does happen it'll happen much sooner than we might expect.











