
Introduction
Research in cognitive science shows that the use of mental imagery helps young children express themselves more clearly in writing (Gambrell and Koskinen, 2002; Gambrell and Bales, 1986; Joffe et al., 2007; Sadoski and Paivio, 2000). Generating useful and coherent text snippets is a typical problem for AI systems in the field of AI research.
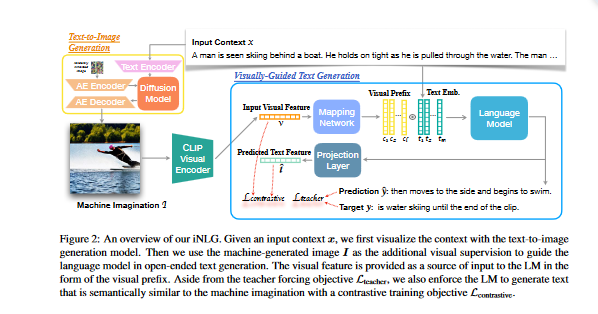
Motivated by this thought process, the authors wonder whether it is possible to program computers to use visual information and develop an overarching image of the environment to guide text output. They propose iNLG, an approach to natural language generation (NLG) that uses machine-generated images to guide language models (LM).
The authors recommend supplementing the visual monitoring of LMs with machine-generated images to help them generate language that is more contextually appropriate. Provide the model with an input context and let it generate text that makes sense in that environment: This is fundamental to many subsequent operations, including text completion, story generation, and dialog systems.
The authors experiment with three open-ended forms of text production: text completion, story generation, and concept-to-text generation.
Issue and solution
The open-ended text generation capabilities of large language models (LMs) are hampered by two significant technological challenges: text degeneration and semantic coverage.
To improve the text cover- age, StoryEndGen (Guan et al., 2019) leverages the knowledge graph to encode context sequentially. Fan et al. (2018) and Yao et al. (2019) plan the content (premise or keywords) first and then en- courage the generation based on planned content
- SimCTG (Su et al., 2022b) employs a contrastive training technique to encourage the model to learn isotropic token embeddings, which helps to reduce text degeneration.
- In Wang et al.'s (2022a) research, a scene graph is generated for each concept, and this graph is combined with text to provide the model's input.
- In previous research, it was suggested that visual information may be added to LM by retrieving images from the internet or from large-scale image collections (Yang et al., 2020; Cho et al., 2021; Su et al., 2022a). However, there is a possibility that the retrieved images may not properly include the context, which will cause the LM to be misled and prevent it from generating predictions that are contextually consistent. This method, in contrast to previous work, makes use of visuals that are generated based on the context in order to facilitate text generation.
Overview of the iNLG framework
More specifically, given the context xi, the researchers first use a text-to-image generator to illustrate an image Ii that depicts the input context. The LM is prompted with image Ii as the visual prefix along with the text context xi, and will incorporate the multimodal input to generate the output text ˆyi
The iNLG framework is a system for training language models to generate text from machine-generated images. There are two main parts to the framework:
- The initial part of the system is a text-to-image generator, or what the authors call the "machine imagination," since it creates a descriptive image based on the given context.
- The second part is a visually guided language model, and it makes use of the machine's imagination as a source of input. Additionally, it employs a supervision that encourages the LM to generate text that is semantically related to the visual information,
Text-to-Image Rendering
In text-to-image rendering, text input is transformed into an image using ML and AI. The basic objective of text-to-image transformation is to facilitate the comprehension of complex information by means of simple visual representations.
- The authors of this study suggest enhancing the LM's visual information with images generated automatically based on the current context. StableDiffusion (Rombach et al., 2022), which mainly comprises a text encoder, a diffusion model, and an autoencoder, provides the backbone for text-to-image generation.
- The text encoder originates from the frozen CLIP ViT-L/14 (Radford et al., 2021) and converts the input text to textual embeddings.
- When it comes to estimating noise, the diffusion model relies on UNet (Ronneberger et al., 2015).
- Images are encoded into lower-resolution latent maps zT by the encoder that is a part of the pretrained autoencoder. The noise estimate is provided by the diffusion model at each step t, and zt is modified in accordance with this information. The image prediction is generated by the decoder of the pretrained autoencoder using the final noise-free latent map z. Training for StableDiffusion is being done using LAION-5B.
Visually Guided Text Generation
Visual Prefix Construction
According to the paper,
With a dataset of image-text pairs (pI1, x1q) is used. The image is encoded with a visual encoder (Encvisual) to receive its visual features (v1). Then, a mapping network (F) is applied over v1 to receive a sequence of l visual prefixes. The visual prefixes are used to guide the language model (LM) in open-ended text generation.
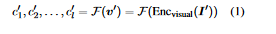
Following the generation of a descriptive image Ii for the given input context xi, the authors make use of CLIP(Contrastive Language-Image Pre-training) to encode Ii and get its visual features vi. They use the pre-trained mapping network F on vi, and as a result, they get the visual prefix ci of length l.

Visually-guided Language Modeling
In context-sensitive applications, visual language modeling is invaluable. In the case of image captioning, for instance, a model may take use of the image's visual clues to provide a precise and detailed caption. The same is true with dialogue systems; using visual clues to assist the machine understanding and provide more appropriate replies.
There are two ways in which they use visual information to steer text generation; these are represented in the training objective that follow:
- In the first step, they feed the LM information that has been created visually by a machine. For each m-token input context xi, they join together its corresponding visual prefix ci with its corresponding text embeddings ti.
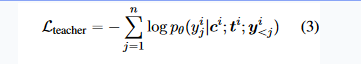
- To ensure that the output text is semantically similar to the input visual supervision, they build a contrastive objective using the InfoNCE.
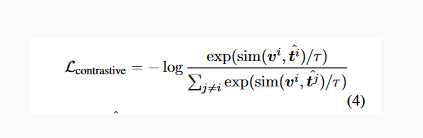
ˆt is the projected representation of the output of the decoder's final layer, and it may be thought of as the sentence-level representation of the text that was created. In this case, the sim ( ̈, ̈) function will first normalize the two vectors before computing the cosine similarity between them, where τ is the temperature.
Training & Inference
- The mapping network is initially pre-trained on the pretraining dataset using the teacher-forcing objective. Such pre-training is task-agnostic, meaning that it may be applied to any given downstream task.
- When implementing the iNLG described in this paper on downstream tasks, the authors train the base LM using the teacher forcing objective for the first N no_contra epochs.
- They introduce the contrastive objective and then proceed to adjust the base LM in conjunction with the mapping network and projection layer in order to minimize the following loss L. In this formula, ep stands for the epoch, and λ is the factor:
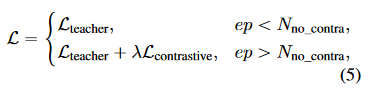
- During the inference process, they give the LM both the context and the image that was generated by the machine. They employ beam search during decoding with a beam width of 10
Experimental Setup
- The authors apply the iNLG presented in this research to three different open-ended text generation settings. These include sentence completion, story generation, and concept-to-text generation.
- For Sentence Completion, they run tests on the ActivityNet (Heilbron et al., 2015) subset of HellaSwag (Zellers et al., 2019), which is a standard for commonsense natural language inference. These experiments challenge the model to estimate the most probable follow-up among multiple possibilities given a particular context.
- Story Generation requires the model to write a story depending on the supplied title or context. ROCStories (Mostafazadeh et al., 2016) is a benchmark for story generation that is widely used, and the researchers undertake tests on it (Mostafazadeh et al., 2016). Each data item consists of a narrative title and a five-sentence ordinary life story that has been produced by a human and combines common sense in relation to the story title.
- Concept-to-Text is a slightly more constrained conditional text generation challenge that involves using reasoning based on common sense. This challenge will supply a collection of concept as input, and the model will be required to build a piece of text that portrays a daily occurrence while also including the concepts that were provided. The CommonGen (Lin et al., 2020) standard serves as the basis for oexperiments.
Evaluation
Metrics use for sentence completion and story generation
Researchers use model degeneration level (rep-n, diversity, distinct-n), text distribution divergence (MAUVE), and semantic similarity (BERTScore) to assess the quality of generated text for sentence completion and story generation
- rep-n: It estimates the percentage of duplicate n-grams, which is a measure of sequence level repetition.
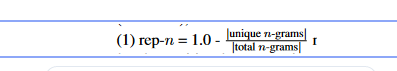
- Diversity: It measures the diversity of n-grams. A text sample is deemed uninformative if there is a strong probability that it will be repetitious to the input context.
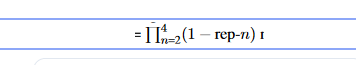
- distinct-n: It calculates how often unique n-grams occur in a text. It is determined by dividing the number of distinct n-grams (a sequence of n words) by total text length.

- MAUVE: MAUVE compares its generated text to human-written text and assesses the difference in the learned distributions divergence. If the MAUVE is low, the distributions of generated text and human text are quite different from one another.
- BERTScore: To measure how similar two texts are contextually, BERTScore computes the cosine similarity between the embedding of their tokens.
Metrics used for concept-to-text
For concept-to-text, the authors present the metric scores on BLEU (Papineni et al., 2002), METEOR (Banerjee and Lavie, 2005), CIDEr (Vedantam et al., 2015), SPICE (Anderson et al., 2016)
Human evaluation
The researchers took 100 random examples from the test set for sentence completion and stories generation. They then compared the text snippets that their iNLG model generated with those generated by the baseline models. They have solicited the participation of human annotators in order to evaluate the quality of the text in relation to three distinct aspects:
- Coherence: which snippets makes the most logical sense given its context in terms of both meaning and flow?
- Fluency: Which snippet has better English proficiency?
- Informativeness: which snippet contains more information.
Implementation Details
- The researchers generate a 512x512 image from the context with the help of StableDiffusion-v1-1 (Rombach et al., 2022), and then they use CLIP ViT/B-32 to extract features offline.
- The mapping network is an 8-layer Transformer, and the visual prefix length is 20.
- The mapping network has been pre-trained on the MSCOCO (Lin et al.,2014) dataset so that it can perform the sentence completion and story generation tasks. In the task of mapping concepts to text, a mapping network that has been pre-trained on VIST is used (Huang et al., 2016).
- Finally, the mapping network is pre-trained for 5 epochs with a batch size of 128.
Result and Analysis
Few-Shot Learning Result
There are many configurations for open-ended text generation, and they can be implemented using a wide range of available means. Annotation collection is often a lengthy and resource-intensive process. Thefore, the researchers present few-shot results to see whether iNLG can quicly adapt to new task configurations with a few instances. The results of the trials and studies show that, despite having fewer training data, iNLG is able to generate text snippets that are logical and useful.
- Sentence Completion: Degeneration strikes StoryEndGen (see table below), which has the greatest rep-n but the lowest diversity. The performance of GPT2 is improved across the board when it is trained using just 1% of the total training data. Adding more machine-generated images using our iNLG in the same few-shot setup substantially reduces model degradation. The improved performance over MAUVE further suggests that using visual input can help GPT2 generate text that is more akin to human-written ones.
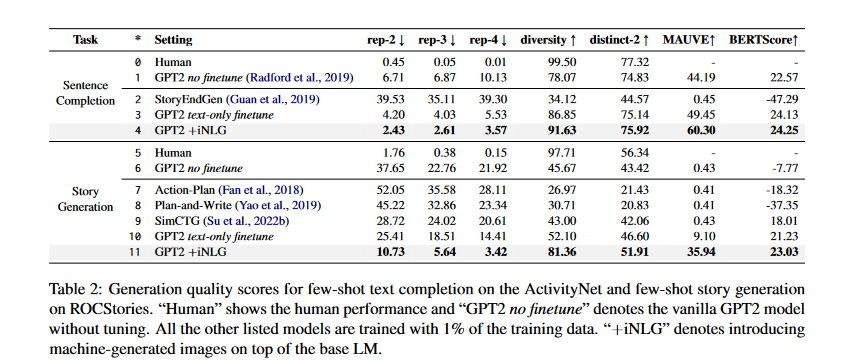
- Story Generation: Applying iNLG to GPT-2 results in a little decrease in quality, but it achieves the highest performance across the board. Some samples of the generated text are shown below:

- Concept-to-Text: Machine-generated visuals can boost the performance of the LM in concept-to-text generation. The results in the table below suggests that knowledge graph information can be underutilized in a few-shot scenario:
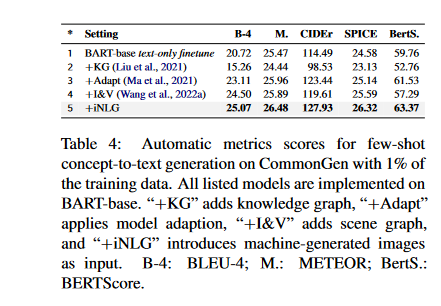
Conclusion
The authors of this study suggest iNLG, a framework for generating open-ended writing with the use of computer-generated graphics. Because of this, computers will be able to visualize their stories in the same imaginative ways that human authors do. Through pre-trained multi-modal models, they extract vision-related information and then build visual prefixes to direct language models in text creation using teacher forcing and a contrastive objective. Extensive trials demonstrate the effectiveness of iNLG in a wide variety of open-ended text generation tasks, such as sentence completion, story generation, and concept-to-text generation in low-resource contexts. The authors also include a link to the data and code that may be used to learn more about and apply the iNLG technique.
Reference:
Visualize Before You Write: Imagination-Guided Open-Ended Text Generation: https://arxiv.org/abs/2210.03765









