

Bring this project to life
In our increasingly interconnected world, the widespread presence of the internet, mobile devices, social media, and communication platforms has provided people with unprecedented access to multilingual content. In this context, the ability to communicate and comprehend information in any language on-demand is becoming increasingly crucial. Although this capability has always been a dream in science fiction, artificial intelligence is on its way of transforming this vision into a technical reality.
In this article we introduce SeamlessM4T: a groundbreaking multilingual and multitask model for seamless translation and transcription across speech and text. It supports automatic speech recognition, speech-to-text translation, speech-to-speech translation, text-to-text translation, and text-to-speech translation for nearly 100 languages, with 35 additional languages supported for output, including English.
SeamlessM4T marks a major advancement in the realm of speech-to-speech and speech-to-text technologies by overcoming the limitations associated with restricted language coverage and the reliance on distinct systems.
Approach used by Seamless M4T
In order to build a lightweight and efficient sequence modeling toolkit Meta redesigned fairseq, one of the first and most popular sequence modeling toolkits. Fairseq2 has proven to be more efficient and has helped to power the modeling behind SeamlessM4T.
A Multitask UnitY model architecture, it is capable of generating both translated text and speech directly. This advanced framework supports various functions, including automatic speech recognition, text-to-text, text-to-speech, speech-to-text, and speech-to-speech translations, seamlessly integrated from the vanilla UnitY model. The multitask UnitY model comprises three key components: text and speech encoders recognize speech input across nearly 100 languages, the text decoder translates meaning into nearly 100 languages for text, and a text-to-unit model decodes it into discrete acoustic units for 36 speech languages. To enhance model quality and stability, the self-supervised encoder, speech-to-text, text-to-text translation components, and text-to-unit model undergo pre-training. The final step involves converting the decoded discrete units into speech using a multilingual HiFi-GAN unit vocoder.
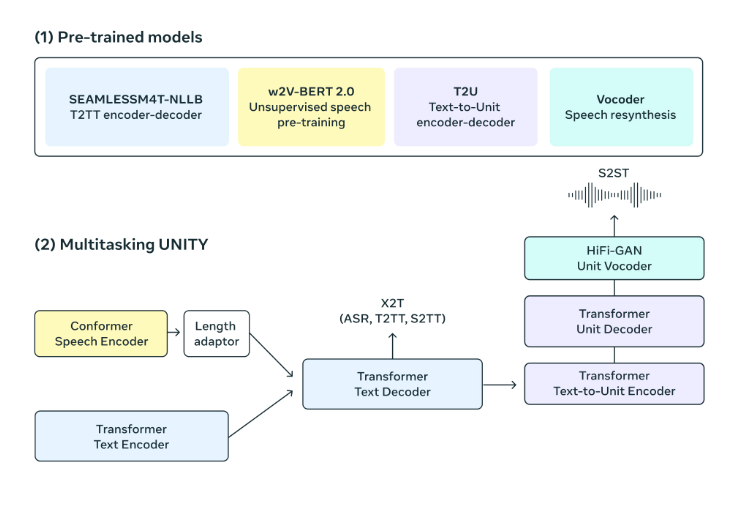
- Encoder Processes Speech:
The self-supervised speech encoder, w2v-BERT 2.0, is an upgraded version of w2v-BERT. This is designed in such a way to enhance the training stability and representation quality. It is even capable of learning and understanding the structure and meaning in speech by analyzing vast amounts of multilingual speech data over millions of hours. This encoder processes audio signals, breaks them into smaller components, and constructs an internal representation of the spoken content. To align with actual words, given that spoken words consist of various sounds and characters, a length adapter is used for more accurate mapping.
- Encoder Processes Text:
The text encoder based on the NLLB (NLLB Team et al., 2022) model, and is trained to understand 100 languages which is then used for translation.
- Producing text:
The text decoder is adept at handling encoded speech or text representations, making it versatile for tasks within the same language, including automatic speech recognition and multilingual translation. Through multitask training, a robust text-to-text translation model (NLLB) is utilized to effectively guide the speech-to-text translation model, employing token-level knowledge distillation for enhanced performance.
- Producing speech:
In the UnitY model, the use of acoustic units represent speech. The text-to-unit (T2U) component creates these speech units from the text output. Before fine-tuning UnitY, T2U is pre-trained on ASR data. Finally, a multilingual HiFi-GAN unit vocoder transforms these units into audio waveforms.
- Data Scaling:
SeamlessM4T model required a large amount of data to train, preferably high quality data too. Previous efforts in text-to-text mining are further extended in this research with a similarity measure in a joint embedding space and also expansion of the initial work in speech mining are incorporated. These contributions help create additional resources for training the SeamlessM4T model.
SONAR (Sentence-level mOdality- and laNguage-Agnostic Representations), a highly effective multilingual and multimodal text embedding space for 200 languages, surpassing existing methods like LASER3 and LaBSE in multilingual similarity search has been established here. To work with these SONAR representations, a teacher-student approach is used to include speech modality. The data mining tasks involved vast amounts of data from web repositories (tens of billions of sentences) and speech (four million hours).
- Results Achieved:
The Data Scaling as discussed results in SeamlessAlign, a significant corpus with over 443,000 hours of aligned speech with texts and around 29,000 hours of speech-to-speech alignments. SeamlessAlign stands as the largest open parallel corpus for speech/speech and speech/text in terms of both volume and language coverage to date.
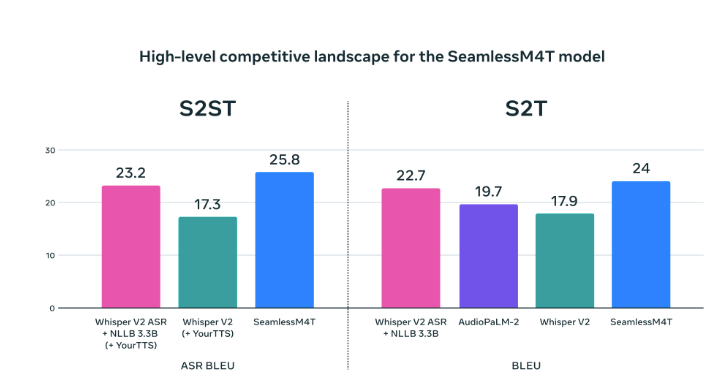
SeamlessM4T has proven to achieve state of the art results for ASR, speech-to-text, speech-to-speech, text-to-speech, and text-to-text translation—all in a single model. BLASER 2.0 is now used for metric evaluation.
Meta claims SeamlessM4T, outperforms previous SOTA competitors.
Paperspace Demo
Bring this project to life
To begin with initiate a Paperspace Notebook with your preferred GPU or with the free GPU. Clone the repository to use the Notebook, either using the provided link above or located at the beginning of this article. Clicking the link will open the project on a Paperspace Free GPU, if one is available. Next, open the project on Paperspace platform. Start the machine and click to open the .ipynb file.
Setup
With that done, navigate to open the notebook seamlessM4T.ipynb. This notebook has all the necessary code to run the model and obtain the results.
- Install the ‘transformer’, ‘sentencepiece’ using ‘pip install’
!pip install git+https://github.com/huggingface/transformers.git sentencepiece
This command installs the ‘transformers’ package from the specified GitHub repository and also installs the ‘sentencepiece’ package. The ‘transformers’ library, developed by Hugging Face, is commonly used for natural language processing tasks, and ‘sentencepiece’ is a library for tokenizing text.
2. Once the installation is complete, move to the next cell. This will import the necessary libraries required to work with the SeamlessM4T model.
#import the necessary libraries
from transformers import AutoProcessor, SeamlessM4Tv2Model
import torchaudio3. Next, load the pre-trained model using the Hugging Face Transformers library and processor from the "SeamlessM4T" family by Facebook.
#load the pre-trained model and processor
processor = AutoProcessor.from_pretrained("facebook/seamless-m4t-v2-large")
model = SeamlessM4Tv2Model.from_pretrained("facebook/seamless-m4t-v2-large")These two lines of code load a pre-trained SeamlessM4T model and its associated processor, making it ready for use in the NLP tasks. The processor is responsible for tokenizing and preprocessing input text, while the model is responsible for performing the actual tasks.
4. The below piece of code will help us to use the previously loaded SeamlessM4T model and processor to generate speech from a given input text or audio.
# from text
text_inputs = processor(text = "Hello, my dog is cute", src_lang="eng", return_tensors="pt")
audio_array_from_text = model.generate(**text_inputs, tgt_lang="ben")[0].cpu().numpy().squeeze()# from audio
audio, orig_freq = torchaudio.load("https://www2.cs.uic.edu/~i101/SoundFiles/preamble10.wav")
audio = torchaudio.functional.resample(audio, orig_freq=orig_freq, new_freq=16_000) # must be a 16 kHz waveform array
audio_inputs = processor(audios=audio, return_tensors="pt")
audio_array_from_audio = model.generate(**audio_inputs, tgt_lang="ben")[0].cpu().numpy().squeeze()5. The final step to display and play the audio generated by the model. The below code snippet is used to utilize the 'Audio' class to display and play audio in an IPython environment. The audio data is provided in the form of NumPy arrays (audio_array_from_text and audio_array_from_audio), and the sampling rate is specified to ensure proper playback.
#import the Audio class from the IPython.display module.
from IPython.display import Audio
#retrieve the sampling rate of the audio generated by the SeamlessM4T model
sample_rate = model.config.sampling_rate
#create an Audio object using the generated audio array and specify sample rate
Audio(audio_array_from_text, rate=sample_rate)
# Audio(audio_array_from_audio, rate=sample_rate)The final step will allow the user to play the generated in the notebook itself also we can save the audio file if required to. We highly recommend our readers to click the link provided and navigate to the .ipynb file and explore the model and Paperspace platform.
What makes SeamlessM4T different
Creating a universal translator has been difficult due to the presence of a vast number of world’s languages. Additionally, a wide range of translation tasks like speech-to-text, speech-to-speech, and text-to-text are required to rely on various AI models.
These types of tasks generally require a huge amount of training data. SeamlessM4T, serving as a unified multilingual model across all modalities, addresses the above mentioned challenges. The model also seamlessly enables on-demand translations, significantly facilitating communication between speakers of different languages. To add more, the model has also significantly improved the translation performance of low- and mid-resource languages.
On Fleurs, SeamlessM4T raises the bar for translations into multiple target languages, outperforming the prior state-of-the-art in direct speech-to-text translation by an impressive 20% BLEU improvement. Compared to robust cascaded models, SeamlessM4T enhances the quality of into-English translation by 1.3 BLEU points in speech-to-text and by 2.6 ASR-BLEU points in speech-to-speech.
The model is also sensitive to bias and toxicity. To address toxicity, Meta expanded their multilingual toxicity classifier to analyze speech, identifying and filtering toxic words in both inputs and outputs. Further steps were taken to mitigate unbalanced toxicity in the training data by removing pairs where the input or output exhibited varying levels of toxicity.
It is worth mentioning: in order to make the model as ethically sound as possible, the AI researchers at Meta, followed a responsible framework which is again guided by the five pillars of Responsible AI.
Closing thoughts
Although text-based models have made huge developments to cover over 200 languages for machine translation, but unified speech-to-speech translation models still lag behind. Traditional speech-to-speech systems use cascaded approaches with multiple subsystems, this approach hampers the development of scalable and high-performing unified speech translation systems. To bridge these gaps, SeamlessM4T is introduced, which serves as a comprehensive model supporting translation across various modalities. This single model accommodates speech-to-speech, speech-to-text, text-to-speech, text-to-text, and automatic speech recognition tasks for up to 100 languages.
Being said that there is still a scope to further improve the model for ASR tasks as stated in the original research paper. Additionally, the model’s proficiency in translating slangs or proper nouns might vary between high and low-resource languages.
It is important to note here that translating speech has an extra challenge because it happens instantly, and speakers don't have much time to check or fix mistakes during a live conversation. Unlike with written language, where the words are planned and revised, spoken words can't be easily edited. So, speech-to-speech translation might have more risks in terms of misunderstandings or offensive language, as there's less chance to correct errors on the spot.
The applications developed using SeamlessM4T should be considered as an assistant and not a tool that replaces human translators or the need to learn new languages.
Speech is not just a few words but is an expression of emotions!
With this we come to the end of the article and we hope that you enjoyed the article and the Paperspace platform.
We strongly hope that SeamlessM4T opens up new possibilities for industrial applications and in research areas as well.
Thanks for reading!











