
Introduction
Instruction tuning is a method for enhancing language models' functionality in NLP applications. Instead of training it to tackle a single task, the language model is fine-tuned on a set of tasks defined by instructions. The purpose of instruction tuning is to optimize the model for NLP problem solving. By instructing the model to carry out NLP tasks in the form of commands or instructions, as in the FLAN (Fine-tuned Language Net) model, researchers have seen improvements in the model's capacity to process and interpret natural language.
Presentation of Flann collection 2022
The Flan Collection 2022 is an open-source toolkit for analyzing and optimizing instruction tuning that includes a variety of tasks, templates, and methodologies. It is the most comprehensive collection of tasks and techniques for instruction tuning that is accessible to the public, and it is an improvement above earlier approaches. The Flan 2022 Collection includes new dialogue, program synthesis, and complex reasoning challenges in addition to those already present in collections from FLAN, P3/T0, and Natural Instructions. The Flan 2022 Collection also has hundreds of premium templates, improved formatting, and data augmentation.
The collection features models that have been fine-tuned across a variety of tasks, from zero-shot prompts to few-shot prompts and chain-of-thought prompts. The collection includes models of several sizes and accessibility levels.
Google used a variety of input-output specifications, including those that merely provided instructions (zero-shot prompting), those that provided examples of the task (few-shot prompting), and those that asked for an explanation along with the answer (chain of thought prompting), to generate the Flan Collection 2022. The resultant models are far smarter and more timely than their predecessors.
The Flan Collection 2022 was developed to perform very well on a variety of language-related tasks, such as question answering, text categorization, and machine translation. Because it has been fine-tuned on more than one thousand extra tasks encompassing more languages than T5 models, its performance is superior to that of T5 models. In addition, the Flan Collection 2022 is customizable, which enables developpers to tailor it to their own requirements in a granular manner.
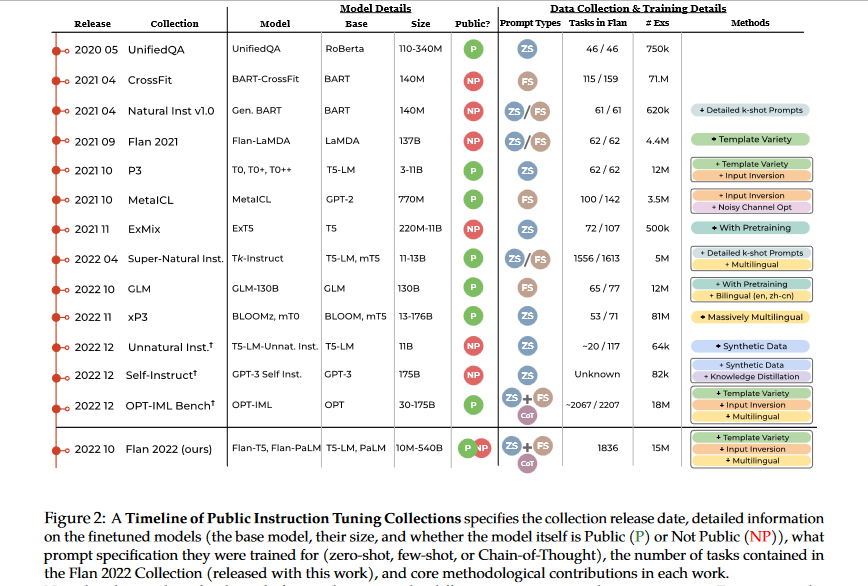
Flan-T5 small, Flan-T5 base, Flan-T5 big, Flan-T5 XL, and Flan-T5 XXL are all part of the Flan Collection 2022. These models can be used as-is with no further fine-tuning, or the Hugging Face Trainer class can be used to fine-tune them for a given dataset. The FLAN Instruction Tuning Repository contains the code needed to load the FLAN instruction tuning dataset.
Difference between pretrain-finetune, prompting and instruction tuning
The diagram that follows presents a comparison of three distinct approaches to the process of training language models. These approaches are referred to as pretrain-finetune (illustrated by BERT and T5), prompting (illustrated by GPT-3) and instruction tuning (illustrated by FLAN).
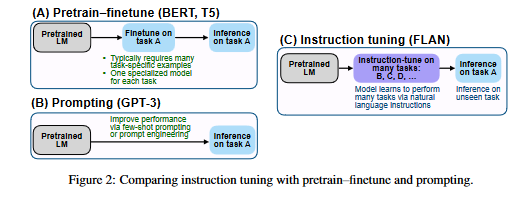
The pretrain-finetune method includes first training a language model on a huge corpus of text (known as pretraining), and then fine-tuning the model for a particular task by providing input and output samples that are unique to the task .
When you prompt a language model, you provide it a prompt, which is a small bit of text. The language model then uses this prompt to produce a larger piece of text that fulfills the need of the task.
Instruction tuning is a technique that incorporates characteristics of prompting and pretrain-finetune into a single technique. It entails fine-tuning a language model by applying it to a collection of tasks that are framed as instructions, where each instruction consists of a prompt and a set of input-output instances. After then, the model is evaluated on unseen tasks.
FLAN: Instruction tuning improves zero-shot learning
Language models' receptivity to natural language processing (NLP) instructions is a key incentive for instruction tuning. The concept is that an LM can be taught to follow instructions and complete tasks without being shown what to do by providing it with a supervised environment in which to do so. In order to assess how well a model performs on tasks it hasn't seen before, they cluster datasets according to task type and isolate individual clusters for assessment, performing instruction tuning on the remaining clusters.
Since it would be time-consuming and resource-consuming to create an instruction tuning dataset from scratch with numerous tasks, the researchers convert existing datasets from the research community into an instructional format. They combine 62 text datasets, including both language understanding and language generation challenges, from Tensorflow Datasets. These datasets are shown in Figure 3; they are divided into 12 different task clusters, each including datasets that perform similar tasks.
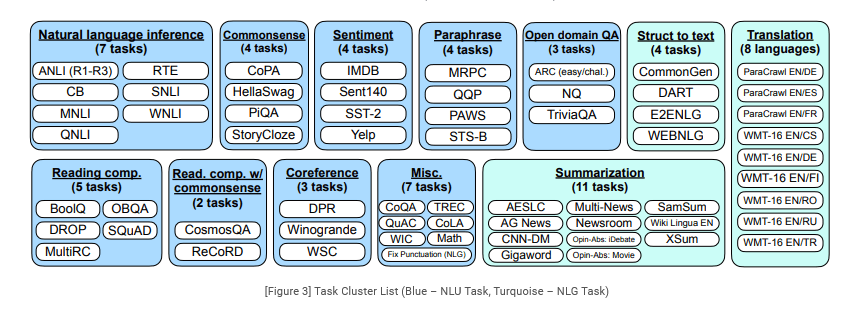
For each dataset, we manually compose ten unique templates that use natural language instructions to describe the task for that dataset. While most of the ten templates describe the original task, to increase diversity, for each dataset we also include up to three templates that “turned the task around,”(e.g., for sentiment classification we include templates asking to generate a movie review).
We then instruction tune a pretrained language model on the mixture of all datasets, with examples in each dataset formatted via a randomly selected instruction template for that dataset. Figure 4 shows multiple instruction templates for a natural language inference dataset.
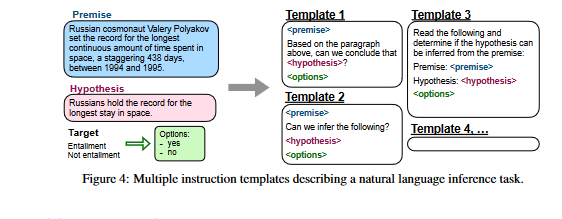
The premise of this task is that the Russian cosmonaut Valery Polyakov spent 438 days in orbit between 1994 and 1995, setting the record for the longest continuous amount of time spent in space. According to the hypothesis, the Russians have the record for the longest stay in space.
Our objective is to check whether the hypothesis can be deduced from the premise
There are a few templates for answering, depending on whether you think the hypothesis can be inferred or not, or if you want to create a new statement that follows from the premise and either supports or contradicts the hypothesis.
Training
Model architecture and pretraining
In their experiments, the researchers use LaMDA-PT, a dense left-to-right decoder-only transformer language model with 137B parameters (Thoppilan et al., 2022). This model was pre-trained on a variety of online pages, including those containing computer code, dialog data, and Wikipedia. These were tokenized into 2.49 trillion BPE tokens using the SentencePiece library, and a lexicon of 32,000 words was used (Kudo & Richardson, 2018). Approximately ten percent of the data collected prior to training was non-English. It is important to note that LaMDA-PT only provides pre-training of the language model, unlike LaMDA, which has been fine-tuned for dialogue.
Instruction tuning procedure
FlAN is the instruction tuned version of LaMDA-PT. The instruction tuning process combines all data sets and randomly draws samples from each of them. The researchers limit the number of training examples per dataset to 30k and follow the example-proportional mixing technique (Raffel et al., 2020), which allows for a mixing rate of no more than 3k.2. This helps them achieve a balance between the different dataset sizes.
They use the Adafactor Optimizer (Shazeer & Stern, 2018) with a learning rate of 3e-5 to fine tune all models for a total of 30k gradient steps, with a batch size of 8,192 tokens and a learning rate of 3e-5. The input and target sequence lengths used in the tuning process are 1024 and 256, respectively. They aggregate numerous training instances into a single sequence using a technique called packing (Raffel et al., 2020), which separates inputs from targets using a unique EOS token. This instruction tuning takes around 60 hours on a TPUv3 with 128 cores. For all evaluations, they report results on the final checkpoint trained for 30k steps
Results
The researchers evaluate FLAN on natural language inference, reading comprehension, closed-book QA, translation, commonsense reasoning, coreference resolution, and struct-to-text. Results on natural language inference, reading comprehension, closed-book QA, and translation are
summarized and described below:
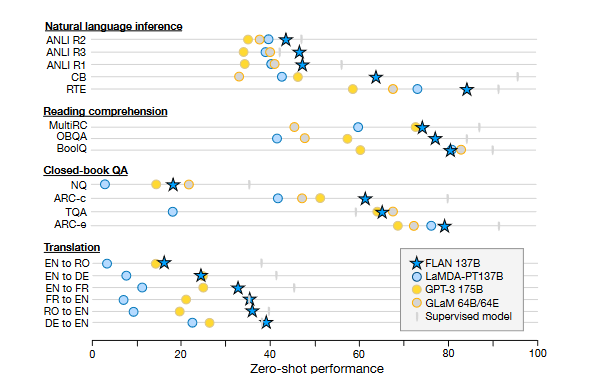
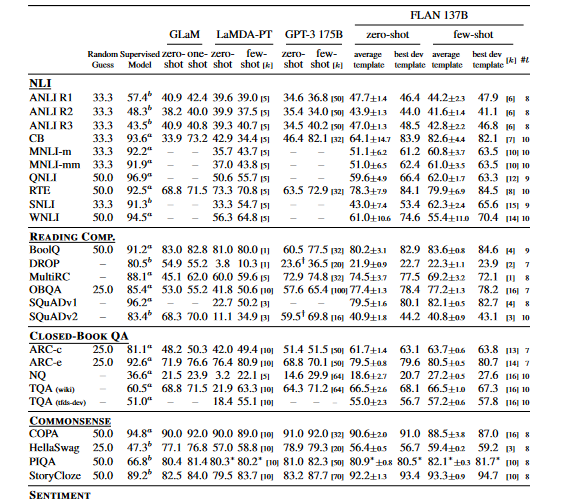
- Natural language inference (NLI): On five NLI datasets, where a model is asked to determine whether a hypothesis is true given a collection of premises, FLAN achieves state-of-the-art performance relative to all baselines. One possible explanation for GPT-3's difficulties with NLI is that NLI instances are often awkwardly constructed as a continuation of a sentence, so they are unlikely to have appeared organically in an unsupervised training set (Brown et al., 2020). The researchers improve the performance of FLAN by phrasing NLI as the more natural “Does <premise> mean that <hypothesis>?”.
- Reading comprehension: In terms of performance, FLAN is superior to the baselines for MultiRC (Khashabi et al., 2018) and OBQA (Mihaylov et al., 2018) in reading comprehension tasks in which models are asked to answer a question regarding a supplied passage. Although LaMDA-PT already achieves great performance on BoolQ (Clark et al., 2019a), FLAN significantly outperforms GPT-3 on this dataset.
- Closed-book QA: FLAN outperforms GPT-3 on all four datasets on closed-book QA, where models are asked to answer questions about the world without being given any of the information that might reveal the answer. On ARC-e and ARC-c, FLAN outperforms GLaM (Clark et al., 2018), but on NQ (Lee et al., 2019; Kwiatkowski et al., 2019) and TQA (Joshi et al., 2017), FLAN performs slightly worse.
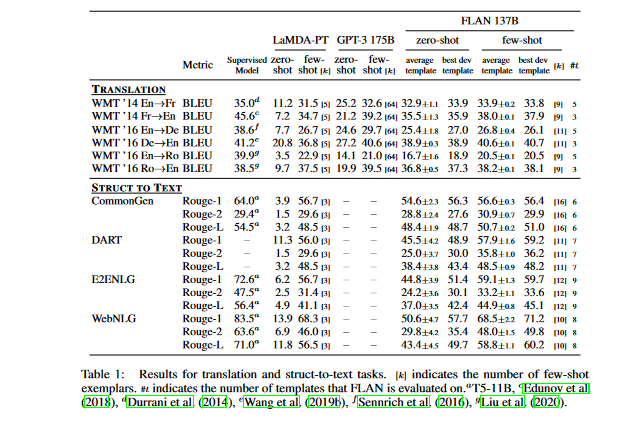
- Translation: LaMDA-PT's training data is similar to that of GPT-3 in that it is mostly English with a small amount of non-English text. The results of FLAN's machine translation are evaluated for the three datasets used in the GPT-3 paper: French-English from WMT'14 (Bojar et al., 2014), German-English from WMT'16 (Bojar et al., 2016), and Romanian-English from WMT'16 (Bojar et al., 2016). FLAN outperforms GPT-3 overall, and zero-shot GPT-3 in particular, on all six evaluations; however, it generally performs worse than few-shot GPT-3. FLAN achieves impressive performance when translating into English, and it performs well against supervised translation baselines, as does GPT-3. However, FLAN uses an English sentence piece tokenizer, and most of its pretraining data is in English, so its performance when translating from English to other languages was quite poor.
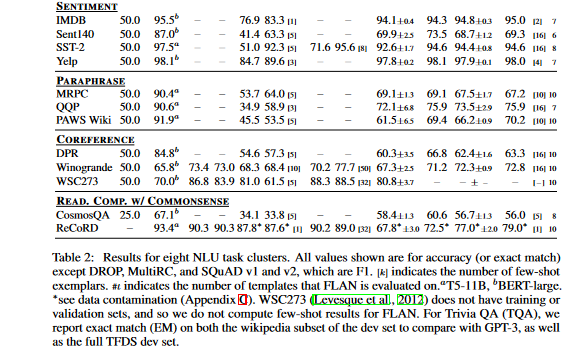
- Additional tasks: While instruction tuning shows promise for the aforementioned task clusters, it is not as effective for many language modeling tasks (such as commonsense reasoning or coreference resolution tasks expressed as sentence completions). In Table 2, we can observe that, of the seven coreference resolution and commonsense reasoning tasks, FLAN only performs better than LaMDA-PT on three of them. This negative result suggests that instruction tuning is not beneficial when the downstream task is identical to the original language modeling pre-training objective (i.e., in situations where instructions are mainly repetitive). Finally, in Table 2 and Table 1, the authors present the results of the sentiment analysis, paraphrase detection, and struct-to-text tasks, as well as other datasets for which GPT-3 results are not available. In most cases, zero-shot FLAN outperforms zero-shot LaMDA-PT and is on par with or even better than the performance of few-shot LaMDA-PT.
The figure below compares the performance of three different kinds of unseen tasks between zero-shot FLAN, zero-shot and few-shot GPT-3. Out of ten assessments, three of these tasks showed a significant improvement in performance thanks to instruction tuning.

Ablation studies involve systematically removing certain components of the model to assess their impact on performance. These studies reveal that the success of instruction tuning relies on key factors such as the number of finetuning datasets, model scale, and natural language instructions.
The critique of the paper
The critique of the paper "Fine-tuned Language Models are Zero-Shot Learners" sheds light on several key areas that could be crucial improvement points for future research. Here is a strategic plan for addressing these points.
- Better Evaluation Metrics: The paper has been criticized for the ambiguity in the results obtained and drawn conclusions. This could be improved by developing and using better evaluation metrics that can quantitively rank the performance of these models. The metrics should be comprehensive enough to include accuracy, precision, recall, and also, incorporate the feedback from human annotators. This will help in providing a more clear comparison of the results obtained.
- Considering Real-World Context: Critiques mentioned that the tasks were designed with less real-world context. Future research should focus on using real-world, task-specific datasets while training the models. This could be achieved by crowd-sourcing language tasks that are more representative of real-world applications of AI.
- Addressing Overparameterization: Overparameterization was identified as a significant concern in this paper. It leads to increased computational power and time. Future research could focus on developing methods to reduce the number of parameters without significantly affecting performance. Techniques like pruning, knowledge distillation, or using transformer variants with fewer parameters could be explored.
- Bias and Ethical considerations: The paper fails to address potential biases in trained models and ethical issues linked to AI's language understanding capabilities. Future research should focus more on bias detection and mitigation techniques to ensure the credibility and fairness of these models. Researchers could also explore and implement ways to make the model more transparent and explainable.
- Resource consumption: Fine-tuned language models are computation-heavy and consume a significant amount of energy, making them less accessible. Future studies could focus on developing more resource-efficient models or methods to make them more accessible and less power-hungry.
- Improved Documentation: The paper was criticized for dicey explanations of some concepts. Future research should emphasize more on a detailed explanation of every concept, idea, and results obtained to ensure the understanding of a broad audience.
Conclusion
FLAN is a potent resource for improving language model efficiency across a wide range of natural language processing (NLP) tasks. Developers that are attempting to create natural language processing models that can perform well on unseen tasks will find its zero-shot learning capabilities to be an invaluable resource. The number of tasks, large size of the model, and use of natural language instructions are all reasons why FLAN has been so successful.
References












