
Bring this project to life
In this article we will explore the large language model TinyLlama, a compact 1.1B language model pre-trained on around 1 trillion tokens for 3 epochs (approx.). TinyLlama is built on the architecture and tokenizer of Llama 2 (Touvron et al., 2023b), a new addition to the advancements from the open-source community. TinyLlama not only enhances computational efficiency but this model outperforms other comparable-sized language models in various downstream tasks, showcasing its remarkable performance.
Introduction
Recent developments in natural language processing (NLP) have mainly resulted from the scaling up of language model sizes. Large Language Models (LLMs), pre-trained on extensive text corpora, have proven highly effective across diverse tasks such as text summarization, content creation, sentence structuring and many more. A huge number of studies highlight emergent capabilities in LLMs, such as few-shot prompting and chain-of-thought reasoning, which are more prominent in models with a substantial number of parameters. Additionally, these research efforts emphasize the importance of scaling both model size and training data together for optimal computational efficiency. This insight guides the selection of model size and data allocation, especially when faced with a fixed compute budget.
A lot of times large models are preferred; this often leads to overlooking the smaller model.
Language models when designed for optimal inference operate to achieve peak performance within defined inference limitations. This is accomplished by training models with a higher number of tokens than recommended by the scaling law. Interestingly, smaller models, when exposed to more training data, can reach or surpass the performance of larger counterparts.
The TinyLlama model is more focused in training the model with a large number of tokens instead of using the scaling law.
This is the first attempt to train a model with 1B parameters using such a large amount of data.-Original Research Paper
TinyLlama demonstrates strong performance when compared to other open-source language models of similar sizes, outperforming both OPT-1.3B and Pythia1.4B across various downstream tasks. This model is open sourced, contributing to increased accessibility for language model researchers. Its impressive performance and compact size position it as an appealing option for both researchers and practitioners in the A.I. field.
Gradio App Demo of TinyLlama
This article provides a concise introduction to TinyLlama, featuring a demonstration through a Gradio app. Gradio facilitates an efficient way to showcase models by converting them into user-friendly web interfaces, accessible to a broader audience. The article includes a practical demonstration of the TinyLlama model using Paperspace.
Paperspace, a cloud computing platform, is highlighted for its provision of virtual machines and GPU instances known for the diverse computing tasks, particularly in the field of machine learning and deep learning. The platform offers a range of GPU options, including popular NVIDIA GPUs like the A6000, A4000, P4000, P6000, and the newly introduced H100. With a pay-as-you-go pricing model, Paperspace enables users to efficiently utilize resources, making it a cost-effective solution for those needing temporary access to robust GPUs without significant upfront investments.
# Import necessary libraries
import torch
# Check available GPUs
device = torch.device("cuda" if use_cuda else "cpu")
print("Device: ",device)
use_cuda = torch.cuda.is_available()
if use_cuda:
print('__CUDA VERSION:', torch.backends.cudnn.version())
print('__Number CUDA Devices:', torch.cuda.device_count())
print('__CUDA Device Name:',torch.cuda.get_device_name(0))
print('__CUDA Device Total Memory [GB]:',torch.cuda.get_device_properties(0).total_memory/1e9)
__CUDNN VERSION: 8401
__Number CUDA Devices: 1
__CUDA Device Name: NVIDIA RTX A4000
__CUDA Device Total Memory [GB]: 16.89124864
# Your machine learning code here, utilizing Paperspace GPU
# For example, training a simple model on GPU
# model = tf.keras.Sequential([...]) # Define your model
# model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# model.fit(train_data, train_labels, epochs=5, validation_data=(val_data, val_labels))
Please refer to Paperspace documentation for any specific configurations or requirements related to their platform.
Please feel free to click the link provided with this article to clone the repo. The repository includes essential files such along with app.py, requirements.txt, and a .ipynb file. Users can effortlessly execute the notebook to construct the Gradio web interface and explore the model.
Pretraining and Model Architecture
The model has been pre-trained using the natural language data from SlimPajama and the code data from Starcoderdata.
TinyLlama has a similar transformer based architectural approach to Llama 2.

The model includes RoPE (Rotary Positional Embedding) for positional embedding, a technique used in recent large language models like PaLM, Llama, and Qwen. Pre-normalization is employed with RMSNorm for stable training. Instead of ReLU, the SwiGLU activation function (Swish and Gated Linear Unit) from Llama 2 is used. For efficient memory usage, grouped-query attention is adopted with 32 heads for query attention and 4 groups of key-value heads, allowing sharing of key and value representations across multiple heads without significant performance loss.
Further, the research included Fully Sharded Data Parallel (FSDP)1 to optimize the utilization of multi-GPU and multi-node setups during training. This integration is important for efficiently scaling the training process across multiple computing nodes, this resulted in a substantial improvement in training speed and efficiency. To add more, another significant enhancement is the integration of Flash Attention 2 (Dao, 2023), an optimized attention mechanism. Also, the replacement of SwiGLU module from the xFormers (Lefaudeux et al., 2022) repository with the original SwiGLU module lead a reduction in memory footprint. As a result, the 1.1B model can now comfortably fit within 40GB of GPU RAM.
The incorporation of these elements
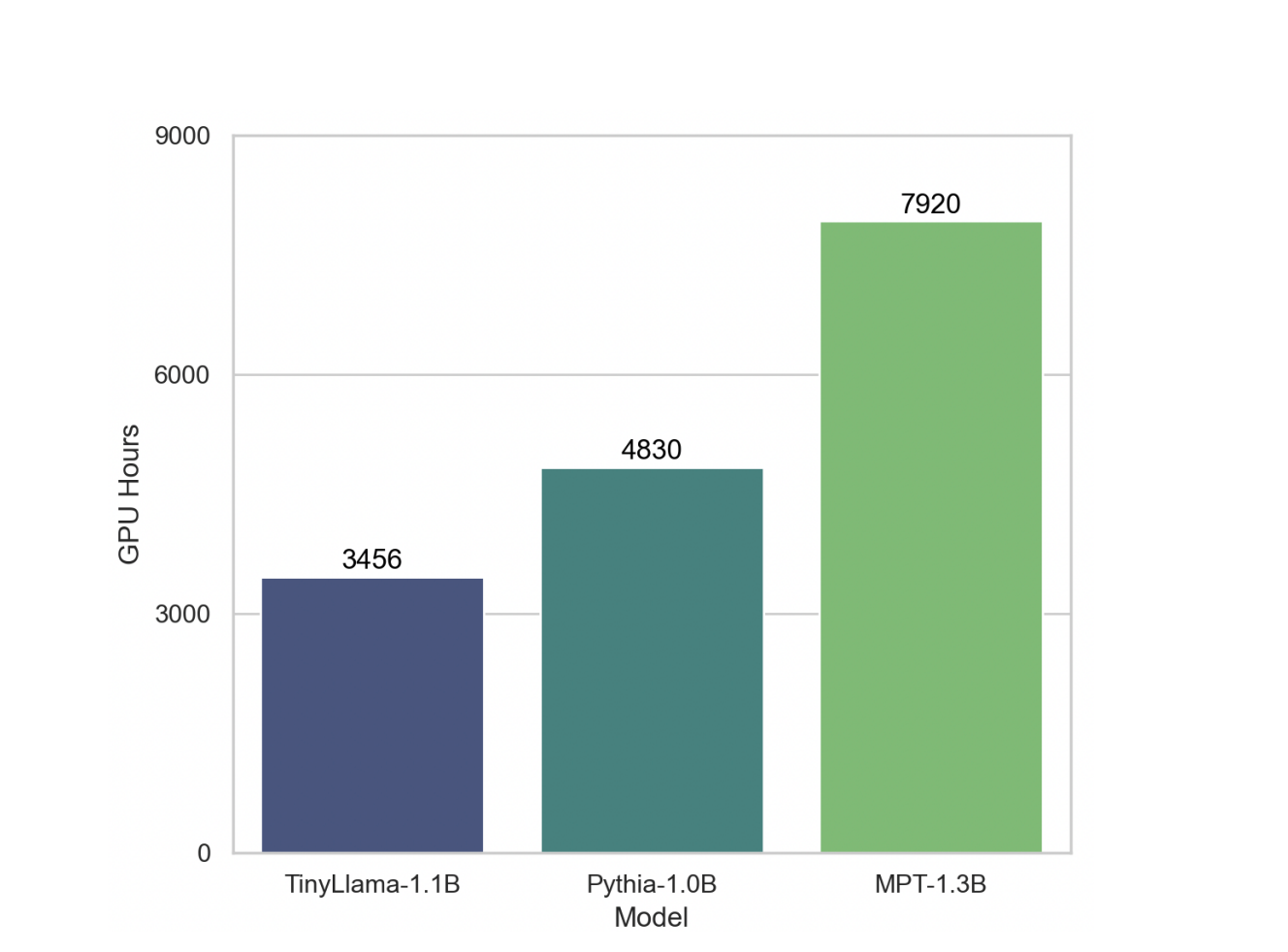
has propelled our training throughput to 24,000 tokens per second per A100-40G GPU. When
compared with other models like Pythia-1.0B (Biderman et al., 2023) and MPT-1.3B 2
, our codebase
demonstrates superior training speed. For instance, the TinyLlama-1.1B model requires only 3,456
A100 GPU hours for 300B tokens, in contrast to Pythia’s 4,830 and MPT’s 7,920 hours. This shows
the effectiveness of our optimizations and the potential for substantial time and resource savings in
large-scale model training. -Original Research Paper
Code Demo
Bring this project to life
Let us take a closer look at TinyLlama, before we start please make sure that you have transformers>=4.31.
- Install the necessary packages
!pip install accelerate
!pip install transformers==4.36.2
!pip install gradioOnce the packages are installed make sure to restart the kernel
- Import the necessary libraries
from transformers import AutoTokenizer
import transformers
import torch- Initialize the Model and the Tokenizer and use TinyLlama to generate texts
# Model and Tokenizer Initialization
model = "PY007/TinyLlama-1.1B-Chat-v0.1"
tokenizer = AutoTokenizer.from_pretrained(model)
# Pipeline Initialization
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
# Prompt
prompt = "What are the values in open source projects?"
formatted_prompt = (
f"### Human: {prompt}### Assistant:"
)
# Generate the Texts
sequences = pipeline(
formatted_prompt,
do_sample=True,
top_k=50,
top_p = 0.7,
num_return_sequences=1,
repetition_penalty=1.1,
max_new_tokens=500,
)
# Print the result
for seq in sequences:
print(f"Result: {seq['generated_text']}")
Results
We have tested the model to understand its efficiency and we can conclude that the model works fine for general q and a and is not suitable for calculations. This makes sense as these models are primarily designed for natural language understanding and generation tasks.
Understanding the Model's Language Understanding and Problem Solving Capabilities
TinyLlama's problem solving abilities has been evaluated using the InstructEval benchmark, which comprises several tasks. Also, in the Massive Multitask Language Understanding (MMLU) task, the model's world knowledge and problem-solving capabilities are tested across various subjects in a 5-shot setting. The BIG-Bench Hard (BBH) task, a subset of 23 challenging tasks from BIG-Bench, evaluates the model's ability to follow complex instructions in a 3-shot setting. The Discrete Reasoning Over Paragraphs (DROP) task focuses on measuring the model's math reasoning abilities in a 3-shot setting. Additionally, the HumanEval task assesses the model's programming capabilities in a zero-shot setting. This diverse set of tasks provides a comprehensive evaluation of TinyLlama's problem-solving and language understanding skills.
Conclusion
In this article we introduce TinyLlama, an open source, small language model a novel approach in the world of LLMs. We are grateful for the fact that these models are open sourced to the community.
TinyLlama, with its compact design and impressive performance, has the potential to support end-user applications on mobile devices and serve as a lightweight platform for experimenting with innovative language model ideas.
I hope you enjoyed the article and the gradio demo!
Thank you for reading!











