
DETR (Detection Transformer) is a deep learning architecture first proposed as a new approach to object detection. It's the first object detection framework to successfully integrate transformers as a central building block in the detection pipeline.
DETR completely changes the architecture compared with previous object detection systems. In this article, we delve into the concept of Detection Transformer (DETR), a groundbreaking approach to object detection.
What is Object Detection?
According to Wikipedia, object detection is a computer technology related to computer vision and image processing that detects instances of semantic objects of a particular class (such as humans, buildings, or cars) in digital images and videos.
It's used in self-driving cars to help the car detect lanes, other vehicles, and people walking. Object detection also helps with video surveillance and with image search. The object detection algorithms use machine learning and deep learning to detect the objects. Those are advanced ways for computers to learn independently based on looking at many sample images and videos.
How Does Object Detection Work
Object detection works by identifying and locating objects within an image or video. The process involves the following steps:

- Feature Extraction: Extracting features is the first step in object detection. This usually involves training a convolutional neural network (CNN) to recognize image patterns.
- Object Proposal Generation: After getting the features, the next thing is to generate object proposals - areas in the image that could contain an object. Selective search is commonly used to pump out many potential object proposals.
- Object Classification: The next step is to classify the object proposals as either containing an object of interest or not. This is typically done using a machine learning algorithm such as a support vector machine (SVM).
- Bounding Box Regression: With the proposals classified, we need to refine the bounding boxes around the objects of interest to nail their location and size. That bounding box regression adjusts the boxes to envelop the target objects.
DETR: A Transformer-Based Revolution
DETR (Detection Transformer) is a deep learning architecture proposed as a new approach to object detection and panoptic segmentation. DETR is a groundbreaking approach to object detection that has several unique features.
End-to-End Deep Learning Solution
DETR is an end-to-end trainable deep learning architecture for object detection that utilizes a transformer block. The model inputs an image and outputs a set of bounding boxes and class labels for each object query. It replaces the messy pipeline of hand-designed pieces with a single end-to-end neural network. This makes the whole process more straightforward and easier to understand.
Streamlined Detection Pipeline
DETR (Detection Transformer) is special primarily because it thoroughly relies on transformers without using some standard components in traditional detectors, such as anchor boxes and Non-Maximum Suppression (NMS).
In traditional object detection models like YOLO and Faster R-CNN, anchor boxes play a pivotal role. These models need to predefine a set of anchor boxes, which represent a variety of shapes and scales that an object may have in the image. The model then learns to adjust these anchors to match the actual object bounding boxes.
The utilization of these anchor boxes significantly improves the models' accuracy, especially in detecting small-scale objects. However, the important caveat here is that the size and scale of these boxes must be fine-tuned manually, making it a somewhat heuristic process that could be better.
Similarly, NMS is another hand-engineered component used in YOLO and Faster R-CNN. It's a post-processing step to ensure that each object gets detected only once by eliminating weaker overlapping detections. While it's necessary for these models due to the practice of predicting multiple bounding boxes around a single object, it could also cause some issues. Selecting thresholds for NMS is not straightforward and could influence the final detection performance. The traditional object detection process can be visualized in the image below:

On the other hand, DETR eliminates the need for anchor boxes, managing to detect objects directly with a set-based global loss. All objects are detected in parallel, simplifying the learning and inference process. This approach reduces the need for task-specific engineering, thereby reducing the detection pipeline's complexity.
Instead of relying on NMS to prune multiple detections, it uses a transformer to predict a fixed number of detections in parallel. It applies a set prediction loss to ensure each object gets detected only once. This approach effectively suppresses the need for NMS. We can visualize the process in the image below:

The lack of anchor boxes simplifies the model but could also reduce its ability to detect small objects because it cannot focus on specific scales or ratios. Nevertheless, removing NMS prevents the potential mishaps that could occur through improper thresholding. It also makes DETR more easily end-to-end trainable, thus enhancing its efficiency.
Novel Architecture and Potential Applications
One thing about DETR is that its structure with attention mechanisms makes the models more understandable. We can easily see what parts of an image focus on, when it makes a prediction. It not only enhances accuracy but also aids in understanding the underlying mechanisms of these computer vision models.
This understanding is crucial for improving the models and identifying potential biases. DETR broke new ground in taking transformers from NLP into the vision world, and its interpretable predictions are a nice bonus from the attention approach. The unique structure of DETR has several real-world applications where it has proved to be beneficial:
- Autonomous Vehicles: DETR's end-to-end design means it can be trained with much less manual engineering, which is an excellent boon for the autonomous vehicles industry. It uses the transformer encoder-decoder architecture that inherently models object relations in the image. This can result in better real-time detection and identification of objects like pedestrians, other vehicles, signs, etc., which is crucial in the autonomous vehicles scene.
- Retail Industry: DETR can be effectively utilized in real-time inventory management and surveillance. Its set-based loss prediction can provide a fixed-size, unordered set of forecasts, making it suitable for a retail environment where the number of objects could vary.
- Medical Imaging: DETR's ability to identify variable instances in images makes it useful in medical imaging for detecting anomalies or diseases. Due to their anchoring and bounding box approach, Traditional models often struggle to detect multiple instances of the same anomaly or slightly different anomalies in the same image. DETR, on the other hand, can effectively tackle these scenarios.
- Domestic Robots: It can be used effectively in domestic robots to understand and interact with the environment. Given the unpredictable nature of domestic environments, the ability of DETR to identify arbitrary numbers of objects makes these robots more efficient.
Set-Based Loss in DETR for Accurate and Reliable Object Detection
DETR utilizes a set-based overall loss function that compels unique predictions through bipartite matching, a distinctive aspect of DETR. This unique feature of DETR helps ensure that the model produces accurate and reliable predictions. The set-based total loss matches the predicted bounding boxes with the ground truth boxes. This loss function ensures that each predicted bounding box is matched with only one ground truth bounding box and vice versa.
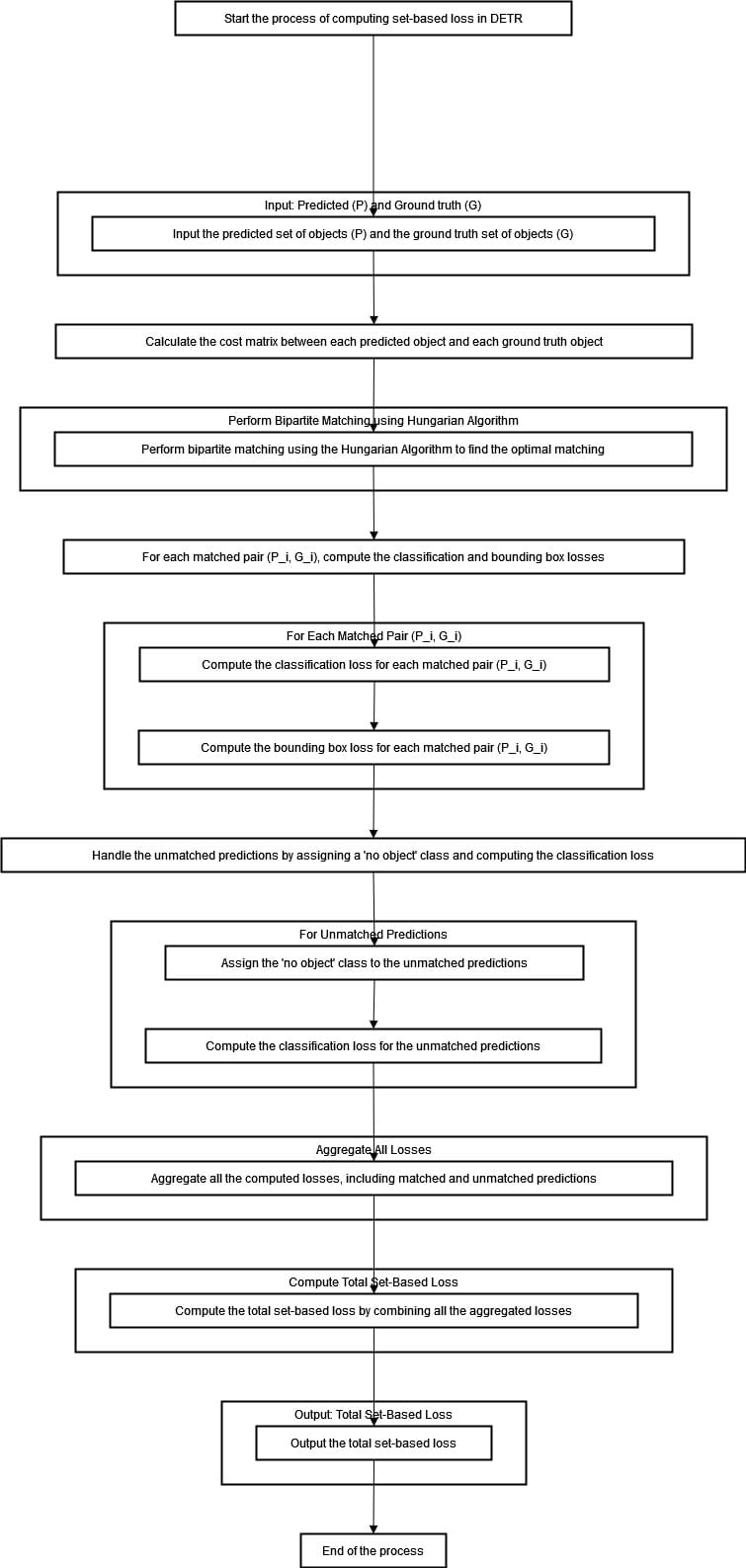
Embarking through the diagram above, we first stumble upon a fascinating input stage where predicted and ground truth objects are fed into the system. As we progress deeper into its mechanics, our attention is drawn towards a computational process that entails computing a cost matrix.
The Hungarian algorithm comes forth in time to orchestrate optimal matching between predicted and ground-truth objects—the algorithm factors in classification and bounding box losses for each match paired.
Predictions that fail to find a counterpart are handed off the "no object" label with their respective classification loss evaluated. All these losses are aggregated to compute the total set-based loss, which is then outputted, marking the end of the process.
This unique matching forces the model to make distinct predictions for each object. The global nature of evaluating the complete set of forecasts together compared to the ground truths drives the network to make coherent detections across the entire image. So, the special pairing loss provides supervision at the level of the whole prediction set, ensuring robust and consistent object localization.
Overview of DETR Architecture for Object Detection
We can look at the diagram of the DETR architecture below. We encode the image on one side and then pass it to the Transformer decoder on the other side. No crazy feature engineering or anything manual anymore. It's all learned automatically from data by the neural network.
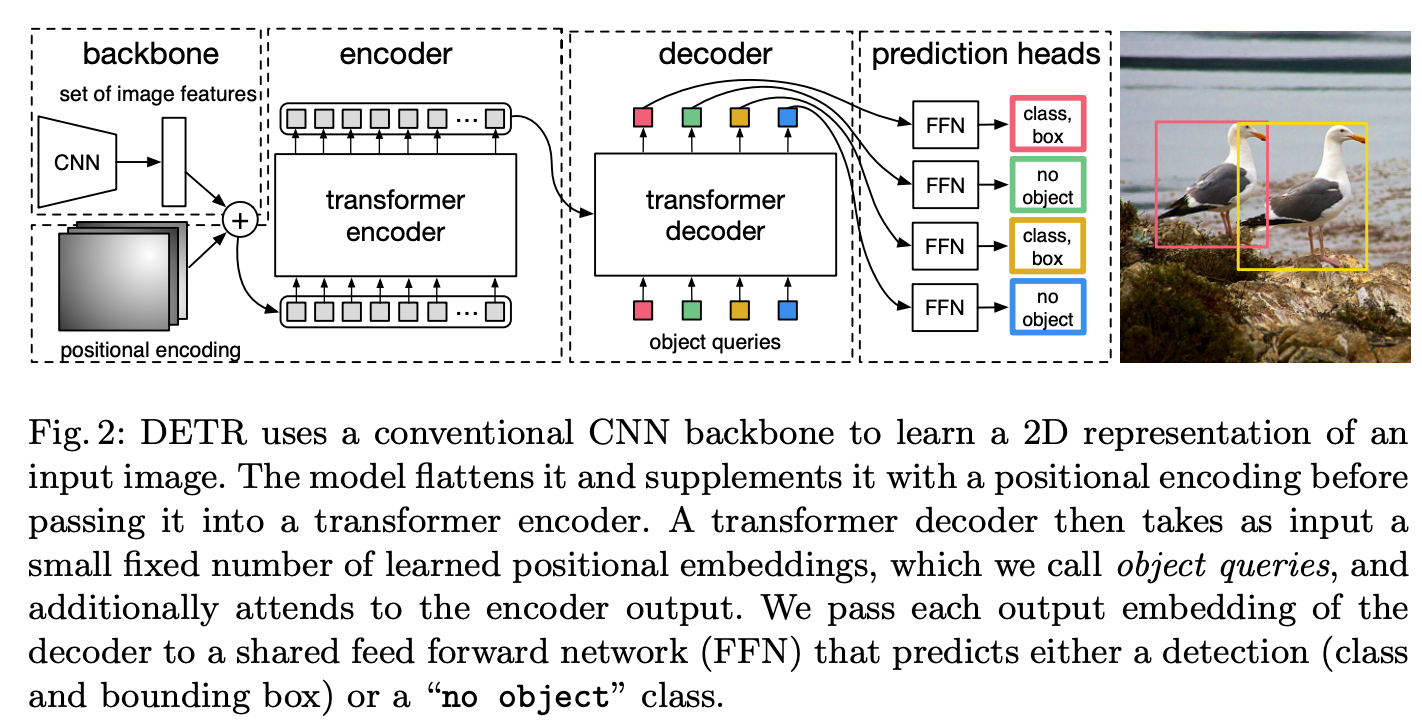
As shown in the image, DETR's architecture consists of the following components:
- Convolutional Backbone: The convolutional backbone is a standard CNN used to extract features from the input image. The features are then passed to the transformer encoder.
- Transformer Encoder: The transformer encoder processes the features extracted by the convolutional backbone and generates a set of feature maps. The transformer encoder uses self-attention to capture the relationships between the objects in the image.
- Transformer Decoder: The transformer decoder gets a few set learned position embeddings as input, which we call object queries. It also pays attention to the encoder output. We give each output embedding from the decoder to a shared feed-forward network (FFN) that predicts either a detection (class and bounding box) or a “no object” class.
- Object Queries: The object queries are learned positional embeddings used by the transformer decoder to attend to the encoder output. The object queries are learned during training and used to predict the final detections.
- Detection Head: The detection head is a feed-forward neural network that takes the output of the transformer decoder and produces the final set of detections. The detection head predicts the class and bounding box for each object query.
The Transformers architecture adopted by DETR is shown in the picture below:
DETR brings some new concepts to the table for object detection. It uses object queries, keys, and values as part of the Transformer's self-attention mechanism.
Usually, the number of object queries is set beforehand and doesn't change based on how many objects are actually in the image. The keys and values come from encoding the image with a CNN. The keys show where different spots are in the image, while the values hold information about features. These keys and values are used for self-attention so the model can determine which parts of the image are most important.
The true innovation in DETR lies in its use of multi-head self-attention. This lets DETR understand complex relationships and connections between different objects in the image. Each attention head can focus on various pieces of the image simultaneously.
Using the DETR Model for Object Detection with Hugging Face Transformers
Bring this project to life
The facebook/detr-resnet-50 model is an implementation of the DETR model. At its core, it's powered by a transformer architecture.
Specifically, this model uses an encoder-decoder transformer and a backbone ResNet-50 convolutional neural network. This means it can analyze an image, detect various objects within it, and identify what those objects are.
The researchers trained this model on a vast dataset called COCO that has tons of labeled everyday images with people, animals, and cars. This way, the model learned to detect everyday real-world objects like a pro. The provided code demonstrates the usage of the DETR model for object detection.
Bring this project to life
from transformers import DetrImageProcessor, DetrForObjectDetection
import torch
from PIL import Image
import requests
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
# you can specify the revision tag if you don't want the timm dependency
processor = DetrImageProcessor.from_pretrained("facebook/detr-resnet-50", revision="no_timm")
model = DetrForObjectDetection.from_pretrained("facebook/detr-resnet-50", revision="no_timm")
inputs = processor(images=image, return_tensors="pt")
outputs = model(**inputs)
# convert outputs (bounding boxes and class logits) to COCO API
# let's only keep detections with score > 0.9
target_sizes = torch.tensor([image.size[::-1]])
results = processor.post_process_object_detection(outputs, target_sizes=target_sizes, threshold=0.9)[0]
for score, label, box in zip(results["scores"], results["labels"], results["boxes"]):
box = [round(i, 2) for i in box.tolist()]
print(
f"Detected {model.config.id2label[label.item()]} with confidence "
f"{round(score.item(), 3)} at location {box}"
)
Output:
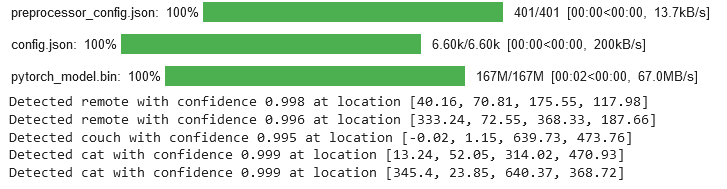
- The code above is doing some object detection stuff. First, it's grabbing the libraries it needs, like the Hugging Face transformers and some other standard ones like torch, PIL and requests.
- Then, it loads an image from a URL using requests. It sends the image through some processing using the
DetrImageProcessorto prepare it for the model. - It instantiates the
DetrForObjectDetectionmodel from the "facebook/detr-resnet-50" using thefrom_pretrainedmethod. Therevision="no_timm"parameter specifies the revision tag if the time dependency is not desired. - With the image and model prepared, the image is fed into the model, resulting in seamless object detection. The
processorprepares the image for input, and themodelperforms the object detection task. - The outputs from the model, which include bounding boxes, class logits, and other relevant information about the detected objects in the image, are then post-processed using the
processor.post_process_object_detectionmethod to obtain the final detection results. - The code then iterates through the results to print the detected objects, their confidence scores, and their locations in the image.
Conclusion
DETR is a deep learning model for object detection that leverages the Transformer architecture. It was initially designed for natural language processing (NLP) tasks as its main component to address the object detection problem uniquely and highly effectively.
DETR treats the object detection problem differently from traditional object detection systems like Faster R-CNN or YOLO. It simplifies the detection pipeline by dropping multiple hand-designed components that encode prior knowledge, like spatial anchors or non-maximal suppression.
It uses a set global loss function that compels the model to generate unique predictions for each object by matching them in pairs. This trick helps DETR make good predictions that we can trust.
References
 Shaoni Mukherjee
Shaoni Mukherjee
 Shaoni Mukherjee
Shaoni Mukherjee
"Petru Potrimba." Roboflow Blog, Sep 25, 2023. https://blog.roboflow.com/what-is-detr/
A. R. Gosthipaty and R. Raha. “DETR Breakdown Part 1: Introduction to DEtection TRansformers,” PyImageSearch, P. Chugh, S. Huot, K. Kidriavsteva, and A. Thanki, eds., 2023, https://pyimg.co/fhm45











