
The goal of the discipline of natural language processing (NLP) is to enable computer programs to understand and utilise natural human language. To implement NLP procedures in Python, there is a toolkit called NLTK. It offers us a variety of text processing packages and a large number of test datasets. Using NLTK, a range of operations, including tokenizing and visualizing parse trees, may be completed. In this article, we'll go over how to set up NLTK in a paperspace gradient and utilize it to carry out a variety of NLP operations during the text processing stage. Then, we will create a Keras model with the help of some NLTK tools for sentiment analysis text classification.
What is Natural Language Processing ?
Natural Language Processing (NLP) is the autonomous manipulation of natural language by software, including speech and text.
This branch of linguistics, computer science, and artificial intelligence manages the interactions between computers and human language, particularly how to train computers to handle and interpret enormous volumes of natural language data.
The previous few decades have seen significant advancements in the field of natural language processing. Beginning with symbolic NLP, which was used by computers to simulate natural language understanding between the 1950s and the early 1990s. Then came the statistical NLP era, which lasted from the 1990s to the 2010s and saw the introduction of new statistical NLP methodologies with a more recent emphasis on machine learning algorithms. Deep neural network techniques have advanced to the point that they are now widely used in natural language processing. In this tutorial, we'll present cutting-edge techniques from this field's statistical and neural phases.
Although the terms AI and NLP may conjure up ideas of cutting-edge robots, there are already simple and basic instances of NLP at work in our everyday lives. Here are a few well-known examples:
- Email spam filtering and classification
- Smart Assistants and home automation hubs like Alexa, Siri and Ok Google
- Search engines (Google, Bing, ...)
- Text prediction like auto-correct and autocomplete
Bring this project to life
Setting up NLTK
The most popular platform for creating Python programs that use human language data is NLTK. Along with a collection of text processing libraries for classification, tokenization, stemming, tagging, parsing, and semantic reasoning, it offers simple interfaces for more than 50 large and structured set of texts (corpora) and lexical resources, including WordNet, which is a lexical database of semantic relations between words in more than 200 languages.
Let's start by setting up the NLKT library along with Numpy and Matplotlib, which are libraries we might also need for additional processing.
!pip install nltk
!pip install numpy
!pip install matplotlibThen, let's download a corpora to be used later in the processing examples:
import nltk
nltk.download()Using the command d we can select the download command then enter the identifier for the dataset, in our case we entered punkt.
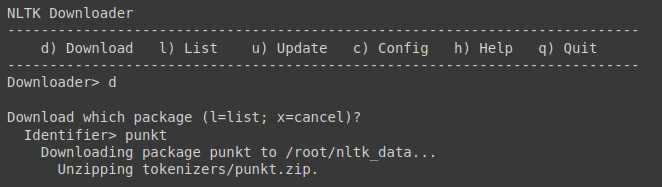
We can also directly download the dataset without browsing the corpus list.
import nltk
nltk.download("punkt")
nltk.download("averaged_perceptron_tagger")
nltk.download("stopwords")For this tutorial, we will use three main datasets:
- punkt: pre-trained tokenizer for English
- averaged_perceptron_tagger: pre-trained parts-of-speech tagger for English
- stopwords: a predefined list of 179 English stop words that add little to the text's meaning, such as "I," "a," and "the."
Then, let's define the text that we will be manipulating during this tutorial. We will use the Paperspace introductory text in our main page.
text = "Paperspace is built for the future where hardware and software are
inextricably linked. Our tools provide a seamless abstraction layer that
radically simplifies access to accelerated computing. The Paperspace
stack removes costly distractions, enabling individuals & organizations
to focus on what matters. "Once you have finished this stage, let's go deeply into the various NLTK processes.
Tokenization
Tokenization is the procedure of turning a string of characters into a list of lexical tokens, which are strings with assigned and identified meaning. Lexers, tokenizers, and scanners are names given to software tools that do lexical analysis; however, the term "scanner" can also refer to the initial stage of a tokenizer.
Typically, a tokenizer is used with a parser to study the syntax of programming languages, web pages, and other types of documents.
So in tokenization, we break down a large body of material into paragraphs, phrases, and words using lexical analysis. It entails recognizing and examining the structure of words.
Using NLTK, we can perform two types of text tokenization:
- Word tokenization: breaking all the sentences of text into words.
- Sentence tokenization: If there is more than a single sentence, we can break the sentences to a list of sentences.
Word tokenization
It is a good practice to always convert the text to lower case before tokenizing it.
text = text.lower()
word_tokens = nltk.word_tokenize(text)
print (word_tokens)This produces the following output:
['paperspace', 'is', 'built', 'for', 'the', 'future', 'where', 'hardware',
'and', 'software', 'are', 'inextricably', 'linked', '.', 'our', 'tools',
'provide', 'a', 'seamless', 'abstraction', 'layer', 'that', 'radically',
'simplifies', 'access', 'to', 'accelerated', 'computing', '.', 'the',
'paperspace', 'stack', 'removes', 'costly', 'distractions', ',',
'enabling', 'individuals', '&', 'organizations', 'to', 'focus', 'on',
'what', 'matters', '.']Sentence tokenization
text = text.lower()
sentence_tokens = nltk.sent_tokenize(text)
print (sentence_tokens)This results in the following output:
['paperspace is built for the future where hardware and software are
inextricably linked.', 'our tools provide a seamless abstraction layer
that radically simplifies access to accelerated computing.', 'the
paperspace stack removes costly distractions, enabling individuals &
organizations to focus on what matters.']Stop word removal
Stop words are words that are added to sentences for more speech fluidity and generally don't add any additional information. Hence, it's a good practice to remove them after the tokenization process.
Using the downloaded stopwords set and NLTK, we can clean the word-tokenized list:
from nltk.corpus import stopwords
stopword = stopwords.words('english')
word_tokens_cleaned = [word for word in word_tokens if word not in stopword]
print (word_tokens_cleaned)This results in the output below:
['paperspace', 'built', 'future', 'hardware', 'software', 'inextricably',
'linked', '.', 'tools', 'provide', 'seamless', 'abstraction', 'layer',
'radically', 'simplifies', 'access', 'accelerated', 'computing', '.',
'paperspace', 'stack', 'removes', 'costly', 'distractions', ',',
'enabling', 'individuals', '&', 'organizations', 'focus', 'matters', '.']Lemmatization
Lemmatization takes into account the words' morphological evaluation. To do this, it is essential to have comprehensive dictionaries that the algorithm may use to connect the word to its lemma.
For example, lemmatization is one of the best techniques to understand consumers' questions in the context of a chatbot. The chatbot is able to comprehend the contextual form of each word because to this method's morphological analysis, which allows it to better comprehend the overall meaning of the entire phrase.
Linguistics is the key to this methodology. It is required to look at each word's morphological analysis in order to obtain the correct lemma. To provide that kind of analysis, dictionaries for every language are necessary.
Below are two examples for word with their extracted lemmas.
| Word | Lemma |
|---|---|
| caches | cache |
| studies | study |
To use the lemmatization method offered by NTLK, we first need to download the Open Multilingual Wordnet (omw) set. This process should be explicit in a linux environment which is the case of a cloud machine learning service like Paperspace's gradient.
nltk.download("omw-1.4")
nltk.download("wordnet")We can then lemmatize the entire text:
from nltk.stem.wordnet import WordNetLemmatizer
wordnet_lemmatizer = WordNetLemmatizer()
lemmatized_tokens = [wordnet_lemmatizer.lemmatize(token) for token in word_tokens_cleaned]
print(lemmatized_tokens)The resulting output is as follows
['paperspace', 'built', 'future', 'hardware', 'software', 'inextricably',
'linked', '.', 'tool', 'provide', 'seamless', 'abstraction', 'layer',
'radically', 'simplifies', 'access', 'accelerated', 'computing', '.',
'paperspace', 'stack', 'remove', 'costly', 'distraction', ',',
'enabling', 'individual', '&', 'organization', 'focus', 'matter', '.']We can notice that the major change are plurals words like 'tools' and 'individuals' which became singular 'tool' and 'individual'.
But basically the lemmatized version of the majority of words don't look very different from its lemma. This is due to the fact that the text is written in informative tone and doesn't use any weird connotations.
Stemming
Stemming algorithms operate by removing portions of words from the beginning or the end of words while taking into account a list of frequently occurring prefixes and suffixes that can be found in inflected words. This strategy has significant limitations since although this indiscriminate cutting can be effective in some situations, it is not always the case.
Although there are other stemming algorithms available, Porter stemmer is the most employed in English. The rules of this algorithm are separated into five phases, numbered from 1 to 5. These guidelines aim to strip words down to their fundamental components.
These are a couple of example of word stems:
| Word | Stem |
|---|---|
| caches | cach |
| studies | studi |
NLTK also offers a Porter Stemmer module
from nltk.stem.porter import PorterStemmer
stemmed_tokens = [PorterStemmer().stem(token) for token in word_tokens_cleaned]
print(stemmed_tokens)When applied to our tokenized text, it results in the following:
['paperspac', 'built', 'futur', 'hardwar', 'softwar', 'inextric', 'link',
'.', 'tool', 'provid', 'seamless', 'abstract', 'layer', 'radic',
'simplifi', 'access', 'acceler', 'comput', '.', 'paperspac', 'stack',
'remov', 'costli', 'distract', ',', 'enabl', 'individu', '&', 'organ',
'focu', 'matter', '.']Creating a stemmer is significantly easier than creating a lemmatizer. Deep linguistics knowledge is necessary in the latter case to develop the dictionaries that allow the algorithm to search for the right form of the word.
Part of Speech tagging
Bring this project to life
The part of speech (POS) tag enables us to identify each word's tags, such as its noun, adjective, or other classification.
pos_tag = nltk.pos_tag(word_tokens_cleaned)
print(pos_tag)Using this method we can evaluate the presence of a word category in the analyzed text.
[('paperspace', 'NN'), ('built', 'VBN'), ('future', 'JJ'), ('hardware',
'NN'), ('software', 'NN'), ('inextricably', 'RB'), ('linked', 'VBN'),
('.', '.'), ('tools', 'NNS'), ('provide', 'VBP'), ('seamless', 'JJ'),
('abstraction', 'NN'), ('layer', 'NN'), ('radically', 'RB'),
('simplifies', 'VBZ'), ('access', 'NN'), ('accelerated', 'VBD'),
('computing', 'VBG'), ('.', '.'), ('paperspace', 'NN'), ('stack', 'NN'),
('removes', 'VBZ'), ('costly', 'JJ'), ('distractions', 'NNS'), (',',
','), ('enabling', 'VBG'), ('individuals', 'NNS'), ('&', 'CC'),
('organizations', 'NNS'), ('focus', 'VBP'), ('matters', 'NNS'), ('.',
'.')]This kind of analysis is useful for editing tools that analyses the fluency for example. Using POS tagging, we can for instance check if we use the correct amount of adverbs in the text..
Word Frequency Distribution
Word frequency is another approach used in natural language processing. It can be utilized as an additional feature for tasks such as sentiment analysis or text classification. You may identify which terms appear in your text the most frequently by building a frequency distribution.
Here’s how to create a frequency distribution using the FreqDist module of NLTK:
from nltk import FreqDist
frequency_distribution = FreqDist(lemmatized_tokens)
frequency_distribution.most_common(10)Using this library, we extract the 10 most common lemmatized words in our test text:
[('.', 3),
('paperspace', 2),
('built', 1),
('future', 1),
('hardware', 1),
('software', 1),
('inextricably', 1),
('linked', 1),
('tool', 1),
('provide', 1)]Dispersion Plot
DispersionPlot visualizes the lexical scattering of words in a text sample. This plot depicts the occurrences of one or more search phrases throughout the content using vertical lines, noting how many words appear compared to the beginning of the text.
To be able to use the dispersion_plot method from NLTK, we must make sure to have Matplotlib installed.
For testing, we used a text from the latest Graphcore and Paperspace partenership annoucement for the launch of the IPU cloud services
from nltk.text import Text
from nltk.draw import dispersion_plot
tokens = nltk.word_tokenize(text.lower())
nltk_text = Text(tokens)
words = ["paperspace","graphcore","gradient","performance"]
dispersion_plot(nltk_text,words,ignore_case=True)This resulted in the following dispersion plot

We can see how our co-founder Daniel Kobran used the keywords paperspace, graphcore and gradient, and made sure to have an even distribution through the text to keep the readers engaged with the subject. We can also see that the last 50 words included the three main keywords, which is a good techniques for anchoring in writing.
From this example, we can see the importance of this kind of analysis especially on long texts like a book or a thesis. Using the frequency distribution and dispersion plot we can have a basic concept on the main ideas that the writer was pushing for in his writing.
Syntax Tree generation
We can also define a set of grammar rules and then use NLTK ChartParser to extract all parts of speech from the sentence. These grammar rules are simply a programmatic formulation of the English language organized in a way that NLTK can understand. Then we can generate a syntax tree for the given sentence and set of rules.
sentence = "AI grows at an astounding pace"
sentence_tokens = nltk.word_tokenize(sentence)
groucho_grammar = nltk.CFG.fromstring("""
S -> NP VP
PP -> P NP
NP -> Det N | Det Adj N | Det N PP | Det Adj N PP | 'AI'
VP -> V NP | VP PP | V
Det -> 'an'
Adj -> 'astounding'
N -> 'pace'
V -> 'grows'
P -> 'at'
""")
parser = nltk.ChartParser(groucho_grammar)
for tree in parser.parse(sentence_tokens):
print(tree)The extracted tree is the following:
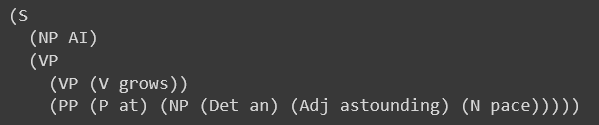
For more complex sentences, the parser will return more than a single tree:
"AI grows at an astounding pace with a wider impact"
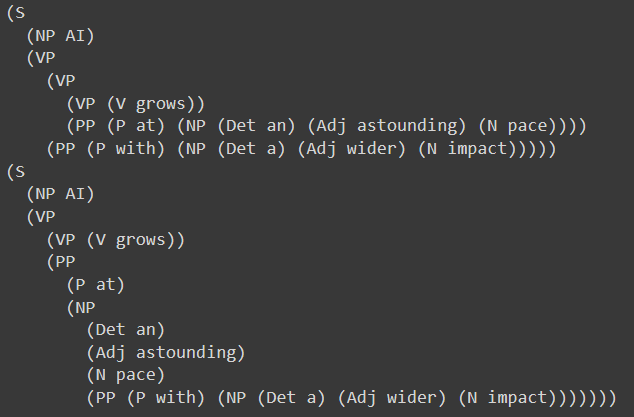
The syntax tree generating tools, like the dispersion plot and frequency distribution, are highly useful for constructing programs that verify the fluency and linguistic level of a given text. A text meant for an audience with a beginner reading skill level might have less syntax indentation, but a more linguistically knowledgeable audience could be exposed to a more sophisticated structure. As a result, the syntax tree generation can be quite useful for distinguishing between the two types of texts.
Sentiment analysis using Keras & NLTK
Sentiment analysis is a natural language processing (NLP) approach used to evaluate whether the data have a positive, negative, or neutral sentiment. Sentiment analysis is frequently done on text data to assist organizations in tracking the sentiment of brands and products in consumer feedback and understanding customer demands. It has also been recently used in the political context, to evaluate the voters reaction to parties declarations.
Other classification tasks where sentiment analysis have been employed are twitter posts and movies and products reviews sentiment classification.
In this tutorial, we will use a Keras model along with the UCI Sentiment Labelled Sentences Data Set, to evaluate the sentiment of some sentences. This dataset represents 3000 sentences along with it's corresponding sentiment label (1 being positive sentiment and 0 representing a negative sentiment).
Let's start by downloading the dataset
!curl https://raw.githubusercontent.com/adilmrk/Sentiment-Analysis-using-NLTK-Keras/main/sentiment_labelled_sentences.txt -o sentiment_labelled_sentences.txtThen, we will use pandas to read the data, and NLTK to tokenize and then lemmatize all the sentences. After that, we will split the dataset into training and testing sets, with a test set taking 25% of the dataset size.
For each sentence, we will transform it to lowercase then tokenize each sentence, and lemmatize each token of the sentences using the WordNetLemmatizer. When dealing with classification tasks, it has been demonstrated that the lemmatization process performs much better than stemming.
Finally, the set of altered sentences will then be vectorized. The scikit-learn module in Python offers an excellent tool called countVectorizer. It is used to convert a given text into a vector based on the number of times that each word appears across the text.
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import CountVectorizer
from nltk.stem.wordnet import WordNetLemmatizer
data = pd.read_csv("sentiment_labelled_sentences.txt", names=['sentence', 'label'], sep='\t')
sentences = data['sentence'].values
y = data['label'].values
sentences = [ nltk.word_tokenize(sentence.lower()) for sentence in sentences]
wordnet_lemmatizer = WordNetLemmatizer()
sentences = [ " ".join([wordnet_lemmatizer.lemmatize(token) for token in sentence_tokens]) for sentence_tokens in sentences]
sentences_train, sentences_test, y_train, y_test = train_test_split(sentences, y, test_size=0.25, random_state=1000)
vectorizer = CountVectorizer()
vectorizer.fit(sentences_train)
X_train = vectorizer.transform(sentences_train)
X_test = vectorizer.transform(sentences_test)Using the Vectorizer, we can create inputs with same sizes for different shape of phrases.
Next, we'll create a Keras sequential model using the input dimension equal to the size of the vectorized sentences.
from keras.models import Sequential
from keras import layers
input_dim = X_train.shape[1]
model = Sequential()
model.add(layers.Dense(10, input_dim=input_dim, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
model.summary()Then we will train the model on the dataset created previously
history = model.fit(X_train, y_train,
epochs=100,
verbose=False,
validation_data=(X_test, y_test),
batch_size=10)For the accuracy and loss plots:
import matplotlib.pyplot as plt
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
plt.figure(figsize=(24, 12))
plt.subplot(1, 2, 1)
plt.plot(range(1, len(acc) + 1), acc, 'b', label='Training acc')
plt.plot(range(1, len(acc) + 1), val_acc, 'r', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(range(1, len(acc) + 1), loss, 'b', label='Training loss')
plt.plot(range(1, len(acc) + 1), val_loss, 'r', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()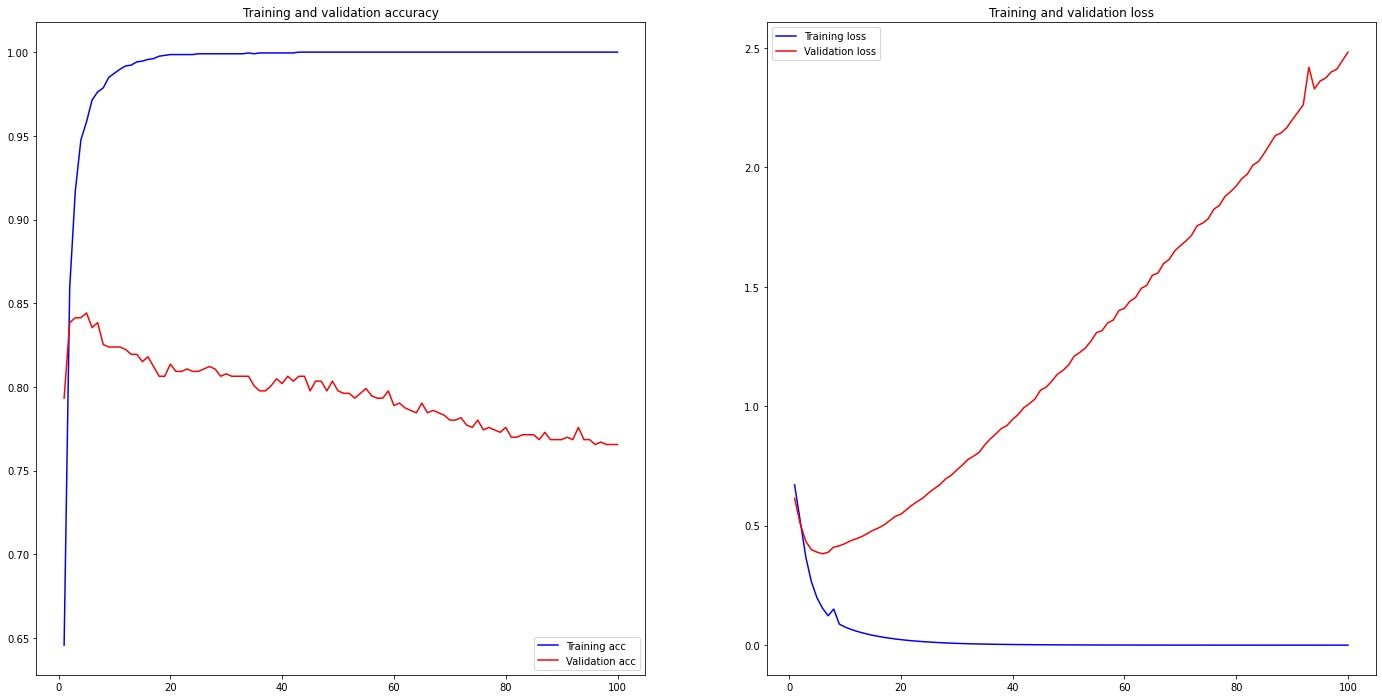
Using this model, we achieved a sentiment analysis accuracy of 76%
loss, accuracy = model.evaluate(X_test, y_test, verbose=False)
print("Testing Accuracy: {:.4f}".format(accuracy))
Then using this trained model, we performed tests on a set of 3 new sentences, two of which are clearly considered to have a positive sentiment, while the third have a negative sentiment.
sentences = ["AI is growing at an amazing pace","paperspace is one of the best cloud computing service providers",
"Using local GPU AI machines is a bad idea"]
sentences = [ nltk.word_tokenize(sentence.lower()) for sentence in sentences]
wordnet_lemmatizer = WordNetLemmatizer()
sentences = [ " ".join([wordnet_lemmatizer.lemmatize(token) for token in sentence_tokens]) for sentence_tokens in sentences]
X_predict = vectorizer.transform(sentences)
predictions = model.predict(X_predict)
predictions = [ (y[0] > 0.5) for y in predictions]
for i in range(0,len(sentences)):
if predictions[i]:
print("Positive sentiment : " + sentences[i])
else:
print("Negative sentiment : " + sentences[i])The result of the sentiment analysis for the 3 test sentences is the following
| Sentence | Sentiment |
|---|---|
| ai is growing at an amazing pace | Positive |
| paperspace is one of the best cloud computing service provider | Positive |
| using local gpu ai machine is a bad idea | Negative |
Conclusion
The goal of natural language processing (NLP) is to enable computer programs to understand and use natural human dialogue. In this article, we looked at the NLTK toolbox, which allows NLP operations to be performed in Python. It gives us a variety of text processing packages as well as various test datasets. Tokenizing, lemmatizing, stemming, and visualizing parse trees are among these processes. We demonstrated how to configure NLTK in a paperspace gradient and use it to conduct a variety of NLP operations during text processing. Then, using NLTK and Keras, we built a Sentiment Analysis model to evaluate the sentiment of a given sentence.
Resources
https://www.researchgate.net/publication/291179558_Natural_Language_Processing
https://archive.ics.uci.edu/ml/datasets/Sentiment+Labelled+Sentences











