
Bring this project to life
LLaVA-1.5 was released as an open-source, multi-modal language model on October 5th, 2023. This was great news for AI developers because they could now experiment and innovate with multi-modals that can handle different types of information, not just words, using a completely open-sourced model.
This article will show the capability of the LLaVA model on Paperspace Gradient. Paperspace acts as the engine for providing the computing power - for anyone looking to dive into the world of advanced AI without needing to purchase and setup their own GPU powered machine.
This article explores the LLaVA1.5 model with a code demo. Different experimental examples are shown with results.vThis article will also explore the latest LLaVA models AI developers can use for developing their applications.
Multimodality with LLaVA
Introduction to Multimodality
According to Grand View Research the global multimodal AI market size was estimated at USD 1.34 billion in 2023 and is projected to grow at a compound annual growth rate (CAGR) of 35.8% from 2024 to 2030.
A multimodal LLM, or multimodal Large Language Model, is an AI model designed to understand and process information from various data modalities, not just text. This means it can handle a symphony of data types, including text, images, audio, video
Traditional language AI models often focus on processing textual data. Multimodality breaks free from this limitation, enabling models to analyze images and videos, and process audio.
Use cases of Multi-models
- Writing stories based on images
- Enhanced robot control with simultaneous voice commands (audio) and visual feedback (camera)
- Real-time fraud detection by analyzing transaction data (text) and security footage (video)
- Analyze customer reviews (text, images, videos) for deeper insights and inform product development.
- Advanced weather forecasting by combining weather data (text) with satellite imagery (images).
Introduction to LLaVA
The full form of LLaVA is Large Language and Vision Assistant. LLaVA is an open-source model that was developed by the fine tuning LLaMA/Vicuna using multimodal instruction-following data collected by GPT. The transformer architecture serves as the foundation for this auto-regressive language model. LLaVA-1.5 achieves approximately SoTA performance on 11 benchmarks, with just simple modifications to the original LLaVA, utilizing all public data.
LLaVA models are designed for tasks like video question answering, image captioning, or generating creative text formats based on complex images. They require substantial computational resources to process and integrate information across different modalities. H100 GPUs can cater to these demanding computations.
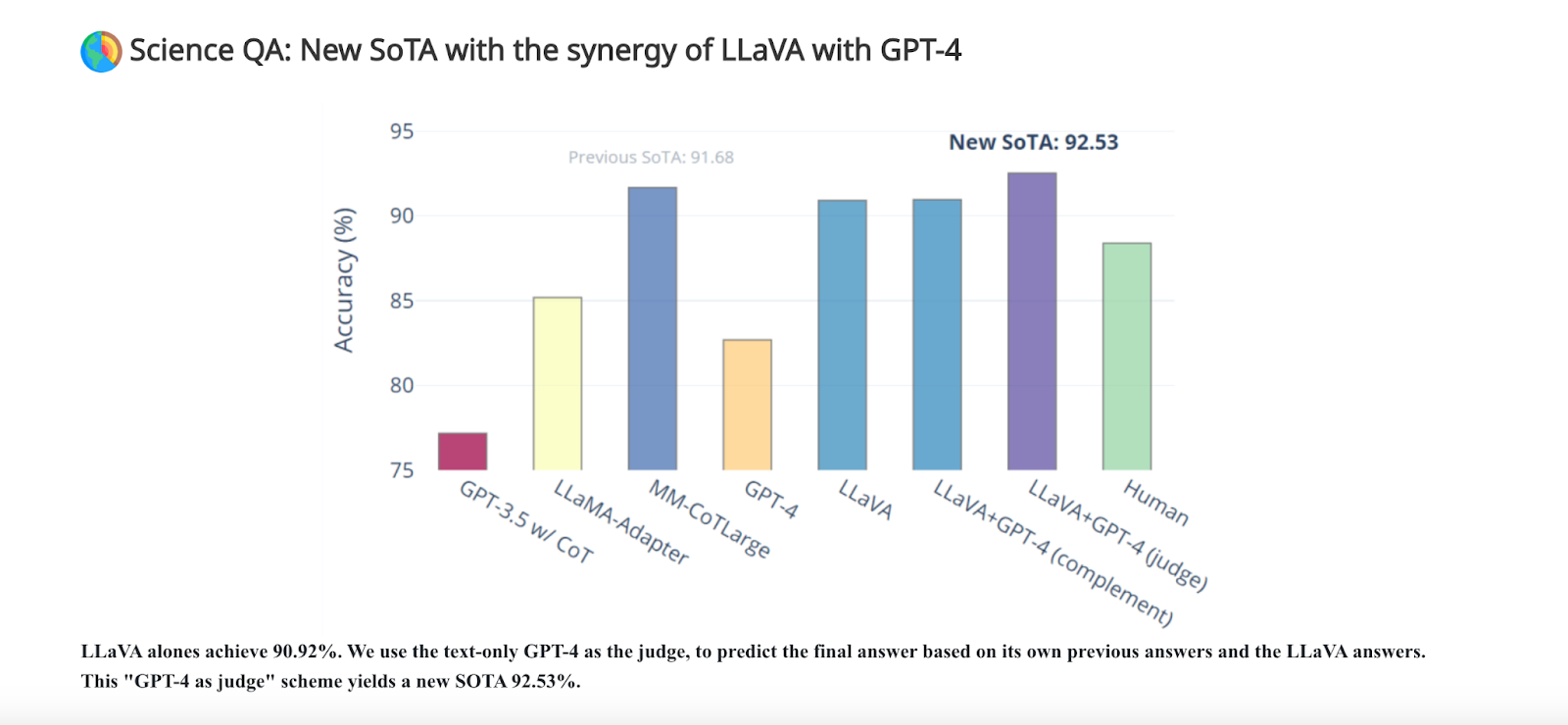
LLaVA alone demonstrates impressive multimodal chat abilities, sometimes exhibiting the behaviors of multimodal GPT-4 on unseen images/instructions, and yields a 90.92% accuracy score on a synthetic multimodal instruction-following dataset. But when LLaVA is combined with GPT-4 then its giving the highest performance in comparison to other models.
There are other LLaVA models out there. We have listed few of open-source models that can be tried:
- LLaVA-HR-It is a high-resolution MLLM with strong performance and remarkable efficiency. LLaVA-HR greatly outperforms LLaVA-1.5 on multiple benchmarks.
- LLaVA-NeXT- This model improved reasoning, OCR, and world knowledge. LLaVA-NeXT even exceeds Gemini Pro on several benchmarks.
- MoE-LLaVA (Mixture of Experts for Large Vision-Language Models) - It is a novel approach that tackles a significant challenge in the world of multimodal AI – training massive LLaVA models (Large Language and Vision Assistants) efficiently.
- Video-LLaVA - Video LLaVA builds upon the foundation of Large Language Models (LLMs), such as Cava, and extends their capabilities to the realm of video.Video-LLaVA also outperforms Video-ChatGPT by 5.8%, 9.9%, 18.6%, and 10.1% on MSRVTT, MSVD, TGIF, and ActivityNet, respectively.
- LLaVA-RLHF - It is the open-source RLHF-trained large multimodal model for general-purpose visual and language understanding. It achieved the impressive visual reasoning and perception capabilities mimicking spirits of the multimodal GPT-4. It is claimed that this model yielded 96.6% (v.s. LLaVA's 85.1%) relative score compared with GPT-4 on a synthetic multimodal instruction.
The LLaVA models mentioned above will require GPUs if they need to be trained and fine tuned. Try NVIDIA H100 GPUs on Paperspace. Talk to our experts.
Output Examples Tried with LLaVA Model
We tested LLaVA 1.5 on different prompts and got the following results.
Test #1: Insightful Explanation
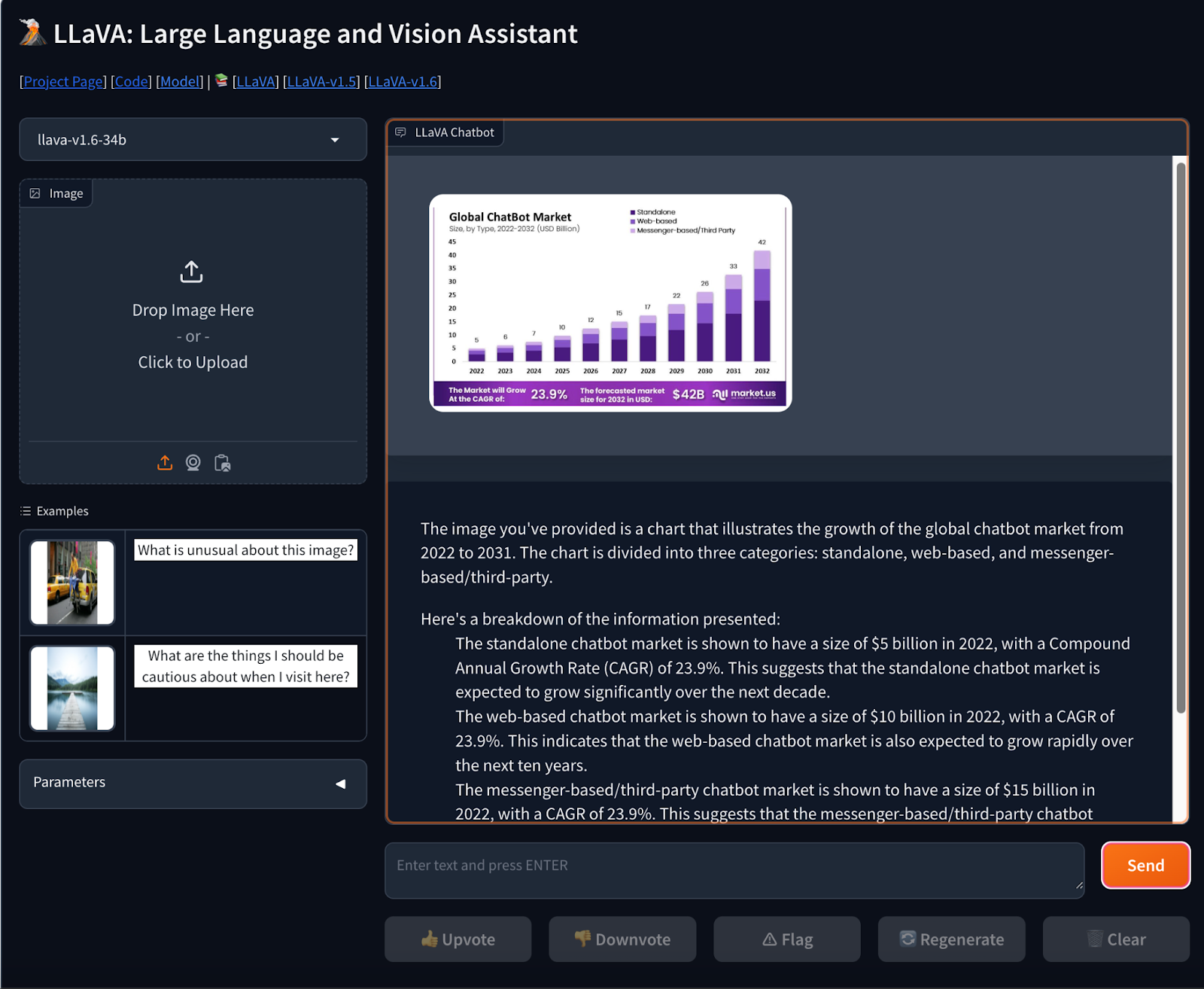
Prompt- Give an insightful explanation of this image.
We tested the abilities of LLaVA 1.5 by giving an image which represents the Global chatbot market. This model has given complete insightful information about the breakdown of the chatbot market as shown in the figure above.
To further test LLaVA-1.5’s image understanding abilities.
Test #2: Image Understanding
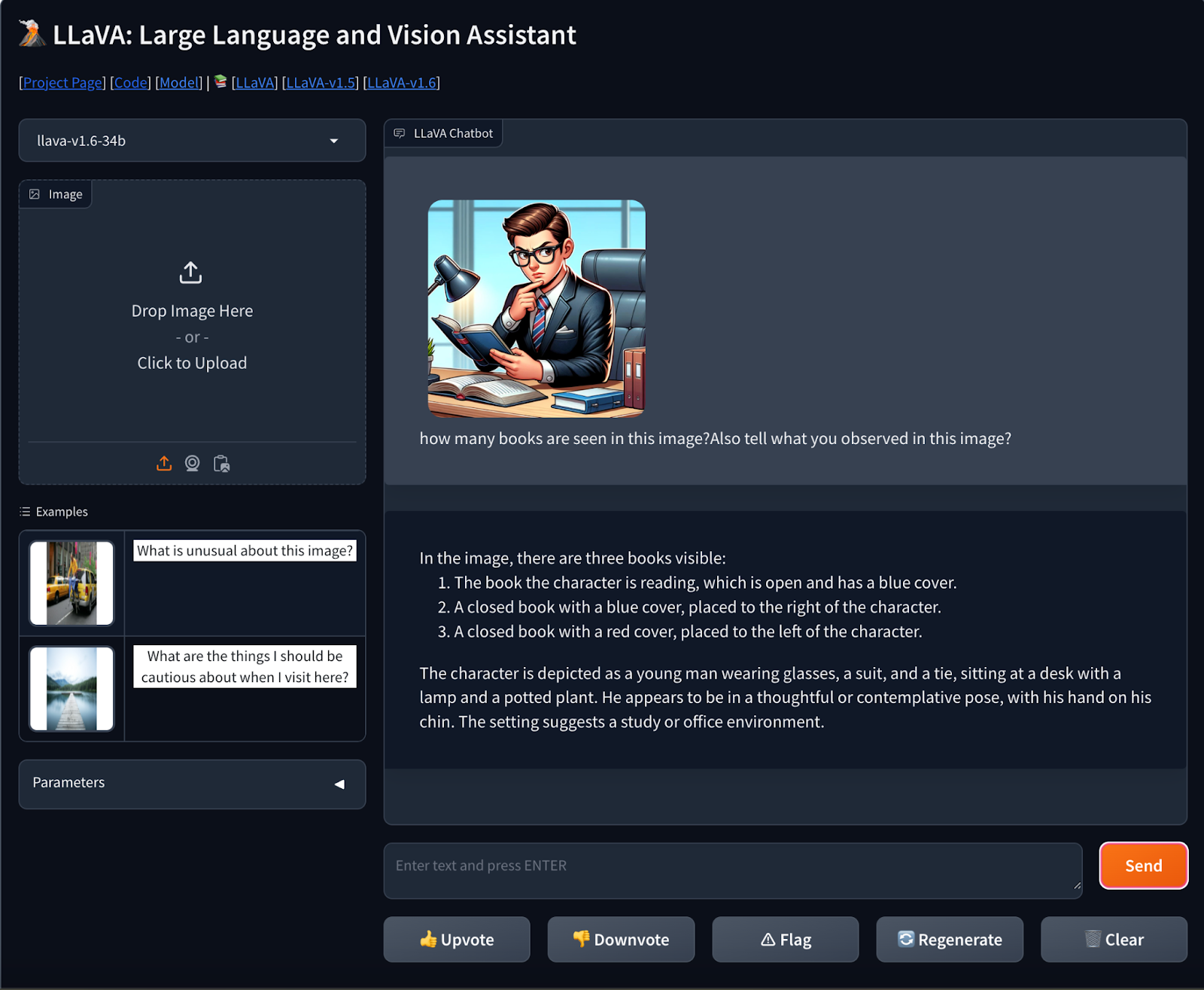
Prompt- how many books are seen in this image?Also tell what you observed in this image?
The model given the correct answer about the number of books and also the image was described accurately while focussing on minute details.
Test #3: Zero Shot Object Detection
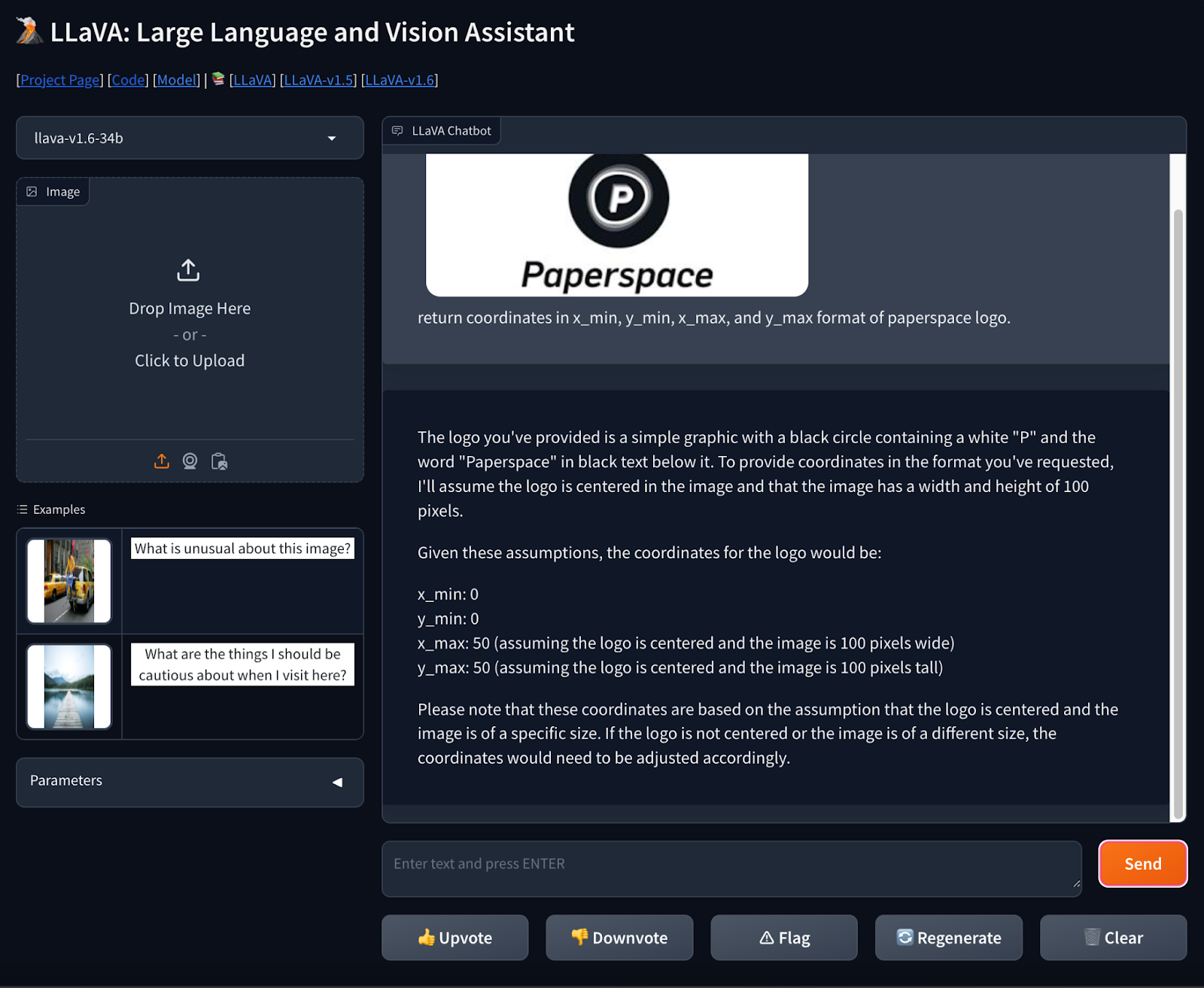
Prompt- Return the coordinates of Paperspace logo in x_min, y_min, x_max, and y_max format.
The model has returned the coordinates by taking the assumption that the logo is centered and given the answer as shown above in the image. The answer was satisfactory.
Making Multimodality Accessible with Paperspace Gradient
Demo
We have implemented LLaVA-1.5 (7 Billion parameter) in this demo. Start the Gradient Notebook by choosing the GPU. Select the prebuilt template for the project, and set the machine's auto shutdown time.
Installing Dependencies
!pip install python-dotenv
!pip install python-dotenv transformers torch
!pip install transformers
from dotenv import load_dotenv
from transformers import pipeline
load_dotenv() # take environment variables from .env.
import os
import pathlib
import textwrap
from PIL import Image
import torch
import requestsThis includes os for interacting with the operating system, pathlib for filesystem paths, textwrap for text wrapping and filling, PIL.Image for opening, manipulating, and saving many different image file formats, torch for deep learning, and requests for making HTTP requests.
Load environment variables
model_id = "llava-hf/llava-1.5-7b-hf"
pipe = pipeline("image-to-text",
model=model_id,
model_kwargs={})
The load_dotenv() function call loads environment variables from a .env file located in the same directory as your script. Sensitive information, like an API key (api_key), is accessed with os.getenv("hf_v"). Here we have not shown the full HuggingFace API key because of security reasons.
How to store API keys separately?
- Create a hidden file named .env in your project directory.
- Add this line to .env: API_KEY=YOUR_API_KEY_HERE (replace with your actual key).
- Write load_dotenv(); api_key = os.getenv("API_KEY")
Setting Up the Pipeline: The pipeline function from the transformers library is used to create a pipeline for the "image-to-text" task. This pipeline is a ready-to-use tool for processing images and generating text descriptions.
3. Image URL and Prompt
image_url = "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTdtdz2p9Rh46LN_X6m5H9M5qmToNowo-BJ-w&usqp=CAU"
image = Image.open(requests.get(image_url, stream=True).raw)
image
prompt_instructions = """
Act as an expert writer who can analyze an imagery and explain it in a descriptive way, using as much detail as possible from the image.The content should be 300 words minimum. Respond to the following prompt:
""" + input_textimage = Image.open(requests.get(image_url, stream=True).raw) fetches the image from the URL and opens it using PIL. Write the prompt and what type of explanation is needed and set the word limit.
4. Output
prompt = "USER: <image>\n" + prompt_instructions + "\nASSISTANT:"
print(outputs[0]["generated_text"])Closing Thoughts
This article explored the potential of LLaVA-1.5, showcasing its ability to analyze images and generate insightful text descriptions. We delved into the code used for this demonstration, providing a glimpse into the inner workings of these models. We also highlighted the availability of various advanced LLaVA models like LLaVA-HR and LLaVA-NeXT, encouraging exploration and experimentation.
The future of multimodality is bright, with continuous advancements in foundation vision models and the development of even more powerful LLMs. Paperspace Gradient stands ready to empower researchers, developers, and enthusiasts to be at the forefront of these advancements.
Join the multimodality revolution on Paperspace Gradient. Experiment and unlock the potential of LLaVA and other cutting-edge LLMs.
Try H100 GPUs on Paperspace.











